Apache Pig est une plateforme de traitement de données open-source conçue pour accélérer et faciliter le processus d'analyse des données. Elle est construite au-dessus de la plateforme Hadoop et est principalement utilisée par les organisations pour extraire des données à partir de grands ensembles de données pour leurs tâches d'analyse de données et d'apprentissage automatique. Développé par Yahoo en 2007, Pig est écrit dans le langage populaire de script et de requête Pig Latin, qui permet aux utilisateurs d'écrire des programmes à l'aide de commandes de type SQL.
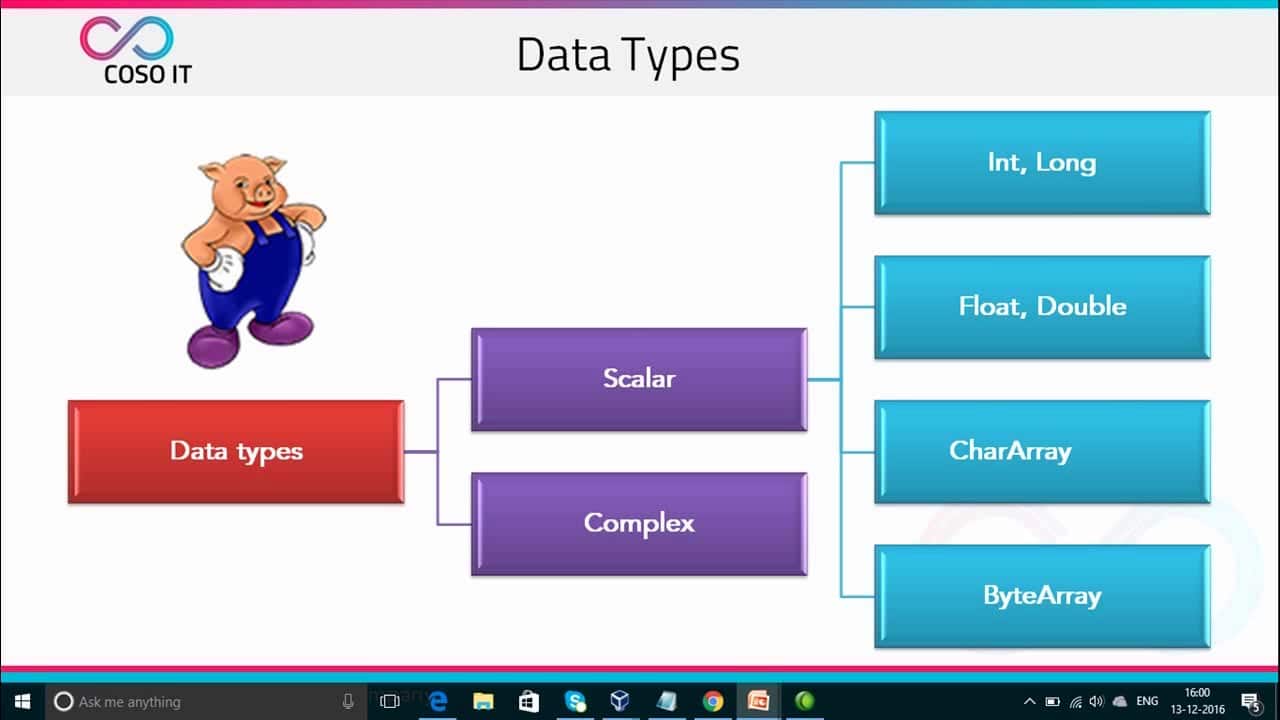
Dans sa forme la plus simple, Pig peut être utilisé pour effectuer des opérations de filtrage, d'agrégation et de tri de données sur de grands ensembles de données. Par exemple, une requête sur Apache Pig peut être utilisée pour joindre des données provenant de deux sources différentes, calculer des statistiques simples et effectuer des opérations telles que le group-by et le count. Bien que la syntaxe de Pig Latin soit similaire à celle de SQL, elle est beaucoup plus expressive et inclut des opérations telles que les types de données complexes, les fonctions définies par l'utilisateur et le chargement de données personnalisées.
Le principal avantage de Pig Latin par rapport à MapReduce de Hadoop est qu'il est plus puissant et plus simple d'écrire des fonctions complexes. Cela le rend populaire auprès des analystes de données et des développeurs qui travaillent sur des projets de Big Data. Il est également plus intuitif et permet des cycles de développement plus rapides. Pig peut également être utilisé en conjonction avec d'autres projets Apache tels que Hive, Sqoop, HCatalog, Spark et Oozie.
Outre son utilisation dans le traitement des données, Apache Pig peut également être utilisé dans divers types de projets de visualisation de données et de science des données. Il est souvent utilisé avec d'autres projets open-source comme Apache Spark et Hadoop pour créer des tableaux de bord visuels et d'autres formes d'analyse de données.
En bref, Apache Pig est une plateforme de traitement de données open-source qui simplifie le processus d'analyse des grands ensembles de données, permettant aux utilisateurs d'extraire et de traiter rapidement des informations à partir de leurs données. Grâce à sa facilité d'utilisation, à ses puissantes fonctionnalités et à son large éventail de cas d'utilisation, Apache Pig est un choix populaire parmi les analystes de données et les développeurs.