Apache Pig to platforma przetwarzania danych o otwartym kodzie źródłowym, zaprojektowana w celu przyspieszenia i ułatwienia procesu analizy danych. Jest ona zbudowana na platformie Hadoop i jest używana głównie przez organizacje do wyodrębniania danych z dużych zbiorów danych w celu analizy danych i zadań uczenia maszynowego. Opracowany przez Yahoo w 2007 roku, Pig jest napisany w popularnym języku skryptowym i zapytań Pig Latin, który umożliwia użytkownikom pisanie programów przy użyciu poleceń podobnych do SQL.
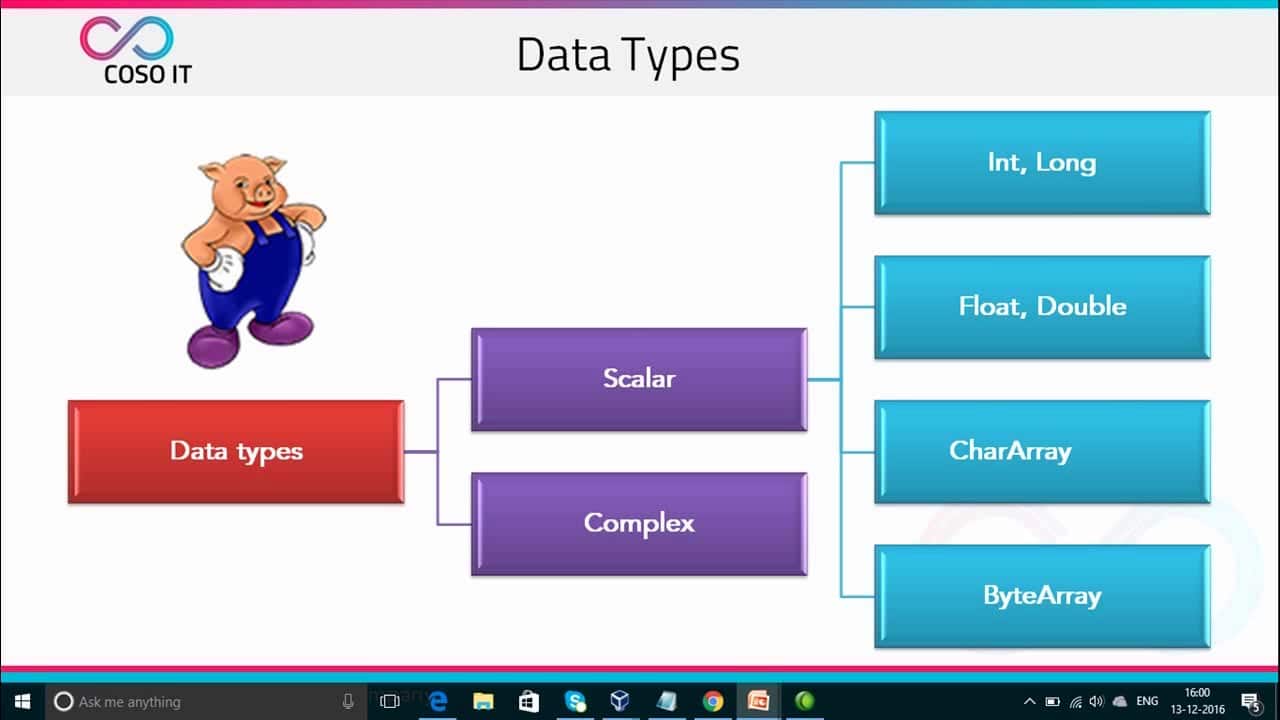
W swojej najprostszej formie Pig może być wykorzystywany do przeprowadzania operacji filtrowania, agregowania i sortowania danych na dużych zbiorach danych. Przykładowo, zapytanie w Apache Pig może być wykorzystane do łączenia danych z dwóch różnych źródeł, obliczania prostych statystyk i wykonywania operacji takich jak grupowanie i zliczanie. Chociaż składnia Pig Latin jest podobna do SQL, jest ona znacznie bardziej ekspresyjna i obejmuje operacje takie jak złożone typy danych, funkcje zdefiniowane przez użytkownika i niestandardowe ładowanie danych.
Główną przewagą Pig Latin nad MapReduce Hadoopa jest to, że jest bardziej wydajny i prostszy w pisaniu złożonych funkcji. To sprawia, że jest popularny wśród analityków danych i programistów, którzy pracują z projektami Big Data. Jest również bardziej intuicyjny i pozwala na szybsze cykle rozwoju. Pig może być również używany w połączeniu z innymi projektami Apache, takimi jak Hive, Sqoop, HCatalog, Spark i Oozie.
Oprócz zastosowania w przetwarzaniu danych, Apache Pig może być również wykorzystywany w różnego rodzaju projektach wizualizacji danych i Data Science. Jest często używany wraz z innymi projektami open-source, takimi jak Apache Spark i Hadoop, do tworzenia wizualnych pulpitów nawigacyjnych i innych form analizy danych.
W skrócie, Apache Pig to platforma przetwarzania danych typu open-source, która upraszcza proces analizy dużych zbiorów danych, umożliwiając użytkownikom szybkie wyodrębnianie i przetwarzanie informacji z ich danych. Dzięki łatwości użytkowania, potężnej funkcjonalności i szerokiemu zakresowi zastosowań, jest to popularny wybór wśród analityków danych i programistów.