Apache Pig es una plataforma de procesamiento de datos de código abierto diseñada para agilizar y facilitar el proceso de análisis de datos. Está construida sobre la plataforma Hadoop y es utilizada principalmente por organizaciones para extraer datos de grandes conjuntos de datos para sus tareas de análisis de datos y aprendizaje automático. Desarrollado por Yahoo en 2007, Pig está escrito en el popular lenguaje de secuencias de comandos y consultas Pig Latin, que permite a los usuarios escribir programas utilizando comandos similares a SQL.
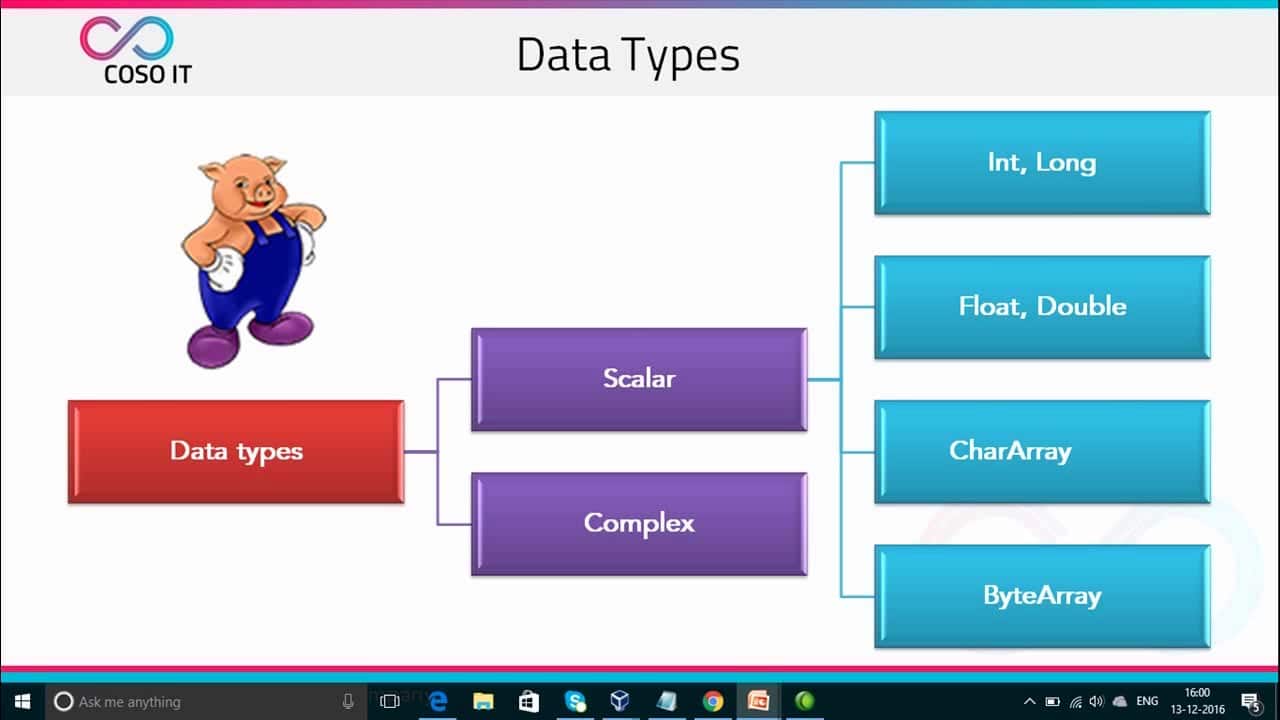
En su forma más simple, Pig puede utilizarse para realizar operaciones de filtrado, agregación y ordenación de datos en grandes conjuntos de datos. Por ejemplo, una consulta en Apache Pig puede utilizarse para unir datos de dos fuentes distintas, calcular estadísticas sencillas y realizar operaciones como agrupar por y contar. Aunque la sintaxis de Pig Latin es similar a la de SQL, es mucho más expresiva e incluye operaciones como tipos de datos complejos, funciones definidas por el usuario y carga de datos personalizada.
La principal ventaja de Pig Latin sobre MapReduce de Hadoop es que es más potente y más sencillo escribir funciones complejas. Esto lo hace popular entre los analistas de datos y los desarrolladores que trabajan con proyectos de Big Data. También es más intuitivo y permite ciclos de desarrollo más rápidos. Pig también se puede utilizar junto con otros proyectos de Apache como Hive, Sqoop, HCatalog, Spark y Oozie.
Aparte de su uso en el procesamiento de datos, Apache Pig también se puede utilizar en varios tipos de visualización de datos y proyectos de Ciencia de Datos. A menudo se utiliza junto con otros proyectos de código abierto como Apache Spark y Hadoop para crear cuadros de mando visuales y otras formas de análisis de datos.
En resumen, Apache Pig es una plataforma de procesamiento de datos de código abierto que simplifica el proceso de análisis de grandes conjuntos de datos, permitiendo a los usuarios extraer y procesar rápidamente la información de sus datos. Gracias a su facilidad de uso, su potente funcionalidad y su amplia gama de casos de uso, es una opción muy popular entre analistas de datos y desarrolladores.