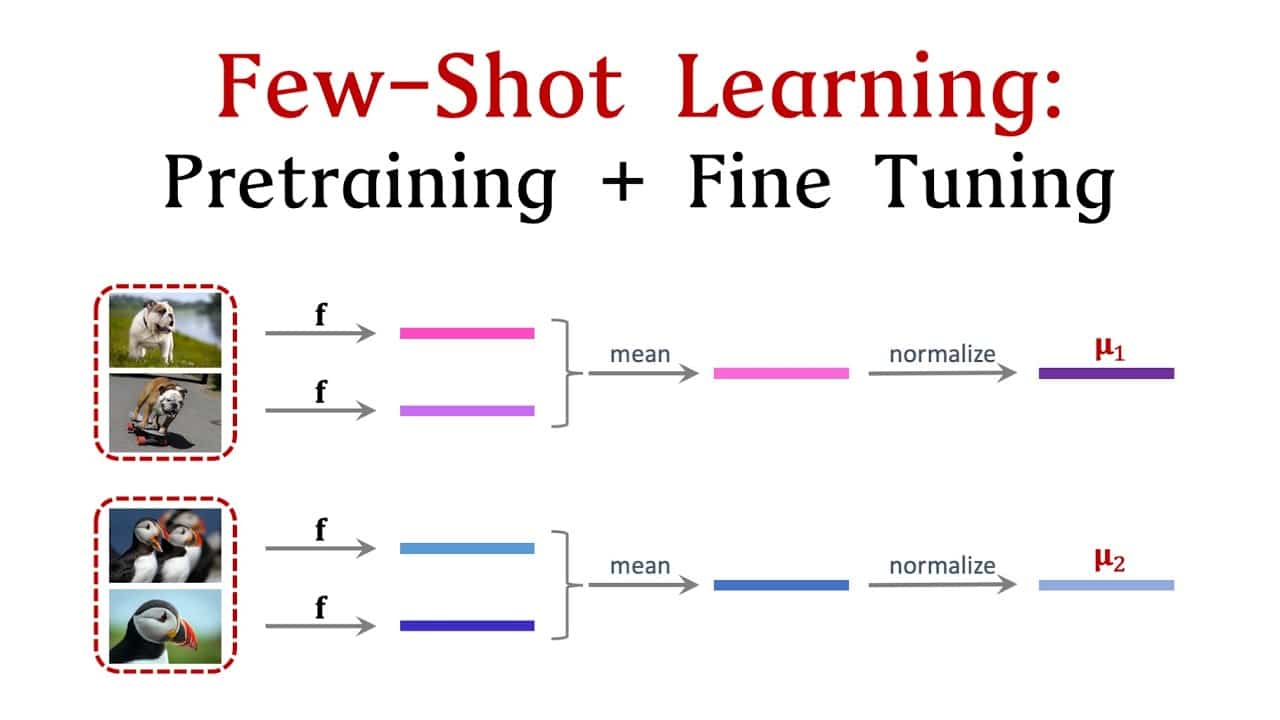
Few shot learning is een machine-leermethode die zich bezighoudt met technieken die gebruikt worden om snel te leren van kleine datasets. Het is een deelgebied van machinaal leren en heeft betrekking op modellen die zich snel kunnen aanpassen aan nieuwe taken als er maar een paar voorbeelden zijn. Het stelt computers in staat om snel te leren en kennis toe te passen zonder veel gegevens.
De methode is ontworpen om snel te kunnen leren op basis van beperkte ervaring. Als zodanig is het een krachtig en nuttig hulpmiddel in veel situaties waarin gegevens schaars zijn, zoals bij medische diagnose, het leren herkennen van objecten na het zien van een of twee voorbeelden, of natuurlijke taalvertaling op basis van kleine datasets.
De basis voor 'few-shot learning' ligt in transfer learning, waarbij over het algemeen wordt geleerd van grote datasets en de kennis wordt overgedragen naar een nieuw domein of een nieuwe taak. Het is minder geschikt voor medische beeldvorming, autonome robots of natuurlijke taalverwerking, waar datasets veel kleiner kunnen zijn.
Few-shot learning wordt gebruikt in veel gebieden van machinaal leren, zoals beeldherkenning, natuurlijke taalverwerking en robotica. Het is met name toegepast op taken zoals het leren herkennen van objecten op een beeld met beperkte resolutie na het zien van slechts een paar voorbeelden, of het leren van een robot om complexe taken uit te voeren met een klein aantal individuele voorbeelden.
Er zijn verschillende benaderingen van 'few-shot learning'. Deze omvatten op metriek gebaseerde methoden, die de gelijkenis tussen de voorbeelden en nieuwe ongeziene gegevens meten om ze te classificeren; op optimalisatie gebaseerde methoden, die een reeds bestaand model optimaliseren om op de nieuwe gegevens te passen; en generatieve en discriminatieve methoden, die nieuwe gegevens genereren of classificeren op basis van bestaande gegevens.
In veel toepassingen kan 'few-shot learning' een efficiëntere en nauwkeurigere manier van leren bieden dan traditionele leermethoden. Door de hoeveelheid gegevens die verzameld moeten worden te verminderen en over-fitting te vermijden, kan de tijd en de kosten die nodig zijn om een taak te leren aanzienlijk worden verminderd, waardoor een snellere en nauwkeurigere analyse mogelijk wordt.