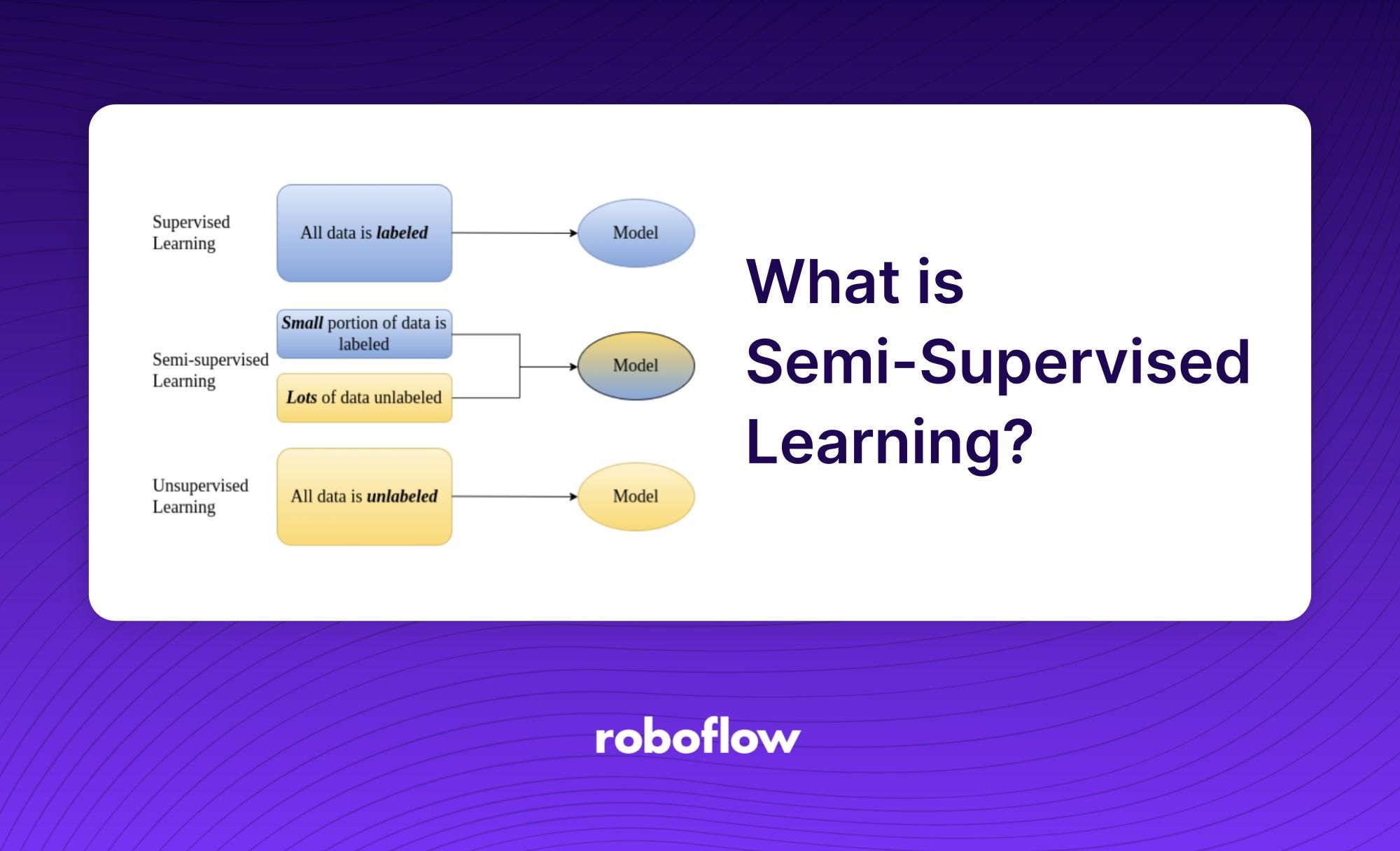
Pembelajaran separa penyeliaan ialah subbidang pembelajaran mesin yang menggunakan kedua-dua data berlabel dan tidak berlabel untuk melatih algoritma. Matlamat pembelajaran separa penyeliaan adalah untuk menggunakan data tidak berlabel untuk menambah data berlabel. Ini membolehkan proses latihan mempunyai lebih banyak maklumat untuk dilatih sementara masih menggunakan hanya sebahagian kecil daripada jumlah data berlabel. Pembelajaran separa penyeliaan ialah satu bentuk pembelajaran diselia kerana ia menggunakan beberapa data berlabel, tetapi berbeza kerana ia turut mengambil kesempatan daripada data tidak berlabel.
Idea asas pembelajaran separa penyeliaan ialah biasanya lebih mudah untuk merealisasikan peraturan data tidak berlabel daripada peraturan data berlabel. Ia juga biasa digunakan apabila hanya sejumlah kecil data berlabel tersedia. Oleh kerana itu, ia telah menjadi pendekatan popular dalam bidang pembelajaran mesin.
Terdapat banyak jenis algoritma pembelajaran separa penyeliaan. Algoritma ini biasanya termasuk dalam satu daripada dua kategori: model generatif atau model diskriminatif. Model generatif ialah algoritma yang cuba memodelkan pengedaran data, manakala model diskriminatif ialah algoritma yang cuba memodelkan perbezaan antara kelas yang diberi data. Di bawah ialah beberapa contoh algoritma separa diselia:
• Rangkaian Adversarial Generatif (GAN): GAN ialah sejenis model generatif yang menggunakan dua rangkaian saraf (penjana dan diskriminator) untuk menjana data baharu yang mengikuti pengedaran set data asal. GAN boleh digunakan untuk pembelajaran separa penyeliaan kerana mereka dapat menjana data daripada set data asal untuk menambah data untuk latihan.
• Latihan kendiri: Latihan kendiri ialah sejenis teknik pembelajaran separa penyeliaan di mana algoritma dilatih pada set data berlabel dan kemudian digunakan untuk mengeluarkan label untuk data tidak berlabel yang sepadan. Label output kemudiannya digunakan sebagai sebahagian daripada data berlabel untuk model untuk dilatih.
• Penyebaran Label: Penyebaran label ialah jenis teknik pembelajaran separa penyeliaan khusus di mana label disebarkan daripada data berlabel kepada data tidak berlabel di sekeliling. Label disebarkan berdasarkan persamaan data dan data berlabel.
Secara keseluruhan, pembelajaran separa penyeliaan ialah teknik yang berkuasa untuk pembelajaran mesin kerana ia membenarkan penggunaan kedua-dua data berlabel dan tidak berlabel untuk melatih algoritma. Ini membolehkan algoritma memanfaatkan kedua-dua sumber data dan oleh itu mampu menghasilkan keputusan yang lebih tepat.