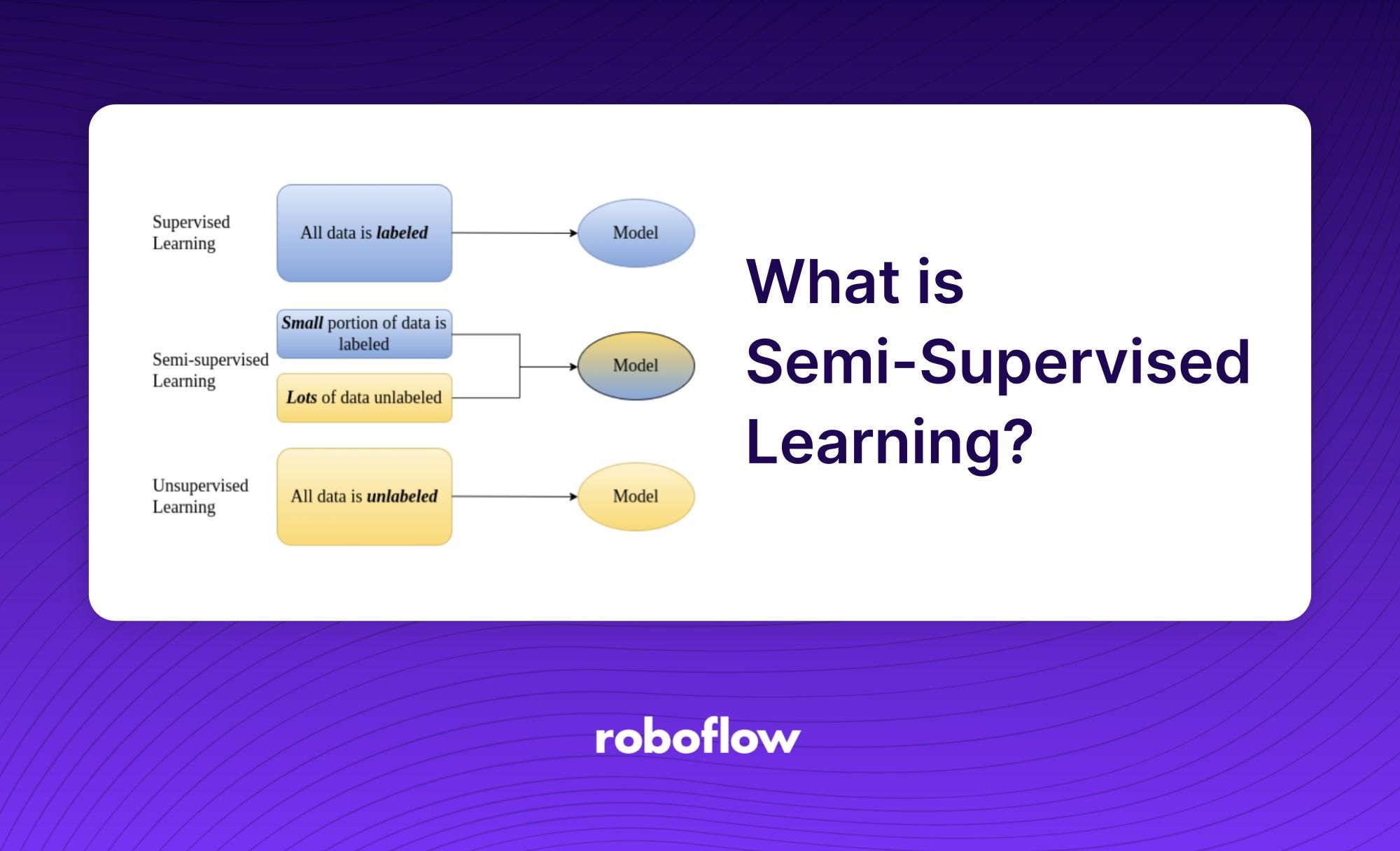
半监督学习是机器学习的一个子领域,它同时使用标记的和未标记的数据来训练算法。半监督学习的目的是利用未标记的数据来补充标记的数据。这使得训练过程有更多的信息可供训练,同时仍然只使用一小部分标记的数据。半监督学习是监督学习的一种形式,因为它使用一些标记的数据,但不同的是它也利用了未标记的数据。
半监督学习的基本思想是,通常实现无标签数据的规则比实现有标签数据的规则要容易。当只有少量的标记数据可用时,它也被普遍使用。正因为如此,它已经成为机器学习领域的一种流行方法。
有许多类型的半监督学习算法。这些算法通常分为两类之一:生成模型或判别模型。生成模型是试图对数据的分布进行建模的算法,而判别模型是试图对给定数据的类之间的差异进行建模的算法。下面是一些半监督算法的例子:
- 生成式对抗网络(GANs):生成网络是一种生成模型,它使用两个神经网络(生成器和鉴别器)来生成遵循原始数据集分布的新数据。GANs可以用于半监督学习,因为它们能够从原始数据集中生成数据,以增加训练的数据。
- 自我训练:自我训练是一种半监督学习技术,在这种技术中,一个算法在一个标记的数据集上被训练,然后被用来为相应的无标记数据输出标签。然后,输出的标签被用作模型训练的标记数据的一部分。
- 标签传播:标签传播是一种特定类型的半监督学习技术,其中标签从有标签的数据传播到周围没有标签的数据。标签的传播是基于数据和标记数据的相似性。
总的来说,半监督学习是一种强大的机器学习技术,因为它允许使用标记的和未标记的数据来训练一个算法。这使算法能够利用这两种数据来源,因此能够产生更准确的结果。