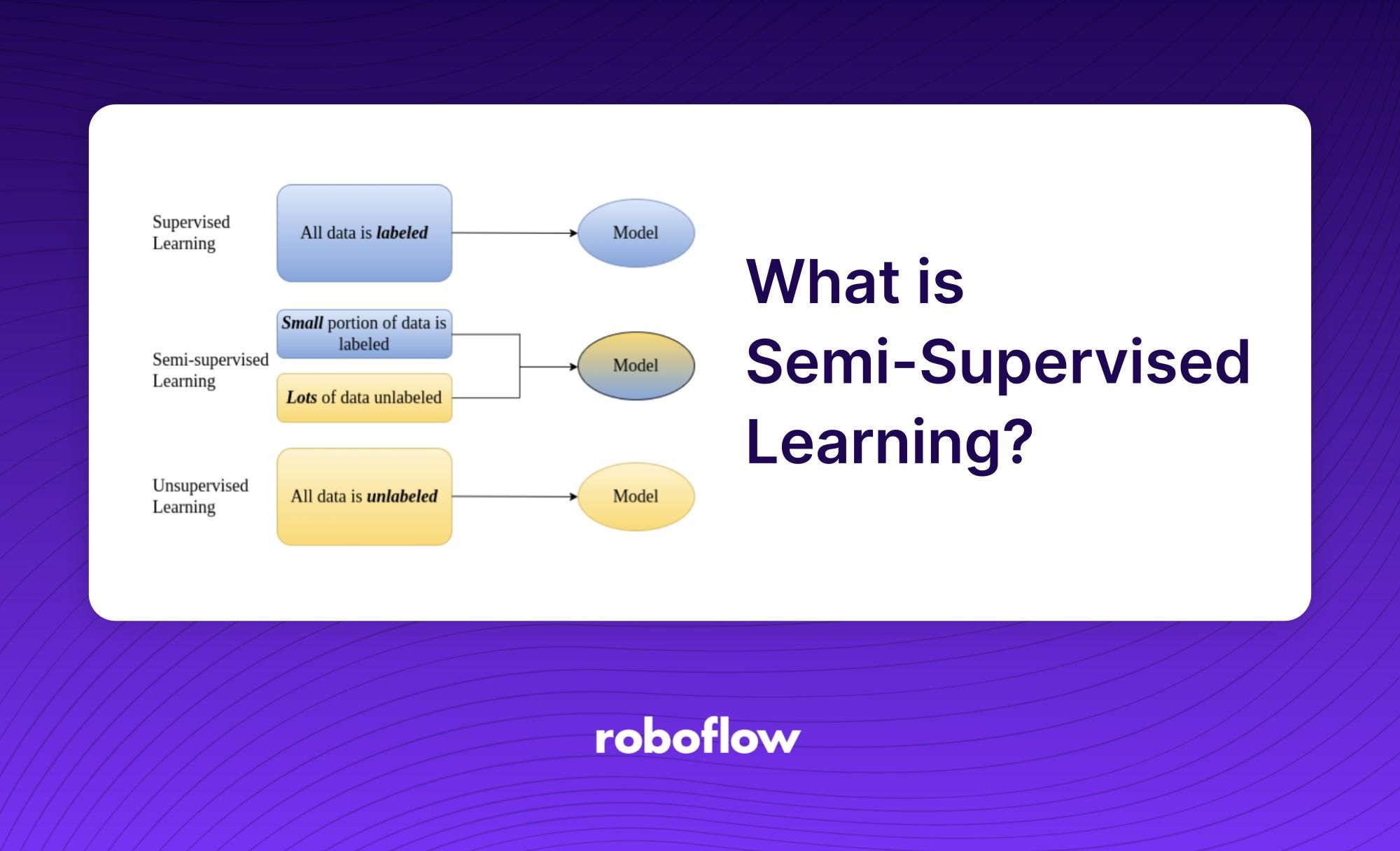
El aprendizaje semisupervisado es un subcampo del aprendizaje automático que utiliza datos etiquetados y no etiquetados para entrenar un algoritmo. El objetivo del aprendizaje semisupervisado es utilizar los datos no etiquetados para complementar los datos etiquetados. De este modo, el proceso de entrenamiento dispone de más información y, al mismo tiempo, utiliza sólo una fracción de los datos etiquetados. El aprendizaje semisupervisado es una forma de aprendizaje supervisado, ya que utiliza algunos datos etiquetados, pero se diferencia en que también aprovecha los datos no etiquetados.
La idea subyacente del aprendizaje semisupervisado es que suele ser más fácil comprender las reglas de los datos no etiquetados que las reglas de los datos etiquetados. También se suele utilizar cuando sólo se dispone de una pequeña cantidad de datos etiquetados. Por ello, se ha convertido en un enfoque muy popular en el campo del aprendizaje automático.
Existen muchos tipos de algoritmos de aprendizaje semisupervisado. Estos algoritmos suelen clasificarse en una de estas dos categorías: modelos generativos o modelos discriminativos. Los modelos generativos son algoritmos que intentan modelizar la distribución de los datos, mientras que los modelos discriminativos son algoritmos que intentan modelizar las diferencias entre clases dados los datos. A continuación se presentan algunos ejemplos de algoritmos semisupervisados:
- Redes Generativas Adversariales (GAN): Las GAN son un tipo de modelo generativo que utiliza dos redes neuronales (generadora y discriminadora) para generar nuevos datos que siguen la distribución del conjunto de datos original. Las GAN pueden utilizarse para el aprendizaje semisupervisado, ya que son capaces de generar datos a partir del conjunto de datos original con el fin de aumentar los datos para el entrenamiento.
- Autoformación: El autoentrenamiento es un tipo de técnica de aprendizaje semisupervisado en la que un algoritmo se entrena en un conjunto de datos etiquetados y, a continuación, se utiliza para generar etiquetas para los datos no etiquetados correspondientes. A continuación, las etiquetas de salida se utilizan como parte de los datos etiquetados con los que se entrena el modelo.
- Propagación de etiquetas: La propagación de etiquetas es un tipo específico de técnica de aprendizaje semisupervisado en la que las etiquetas se propagan desde los datos etiquetados a los datos circundantes no etiquetados. Las etiquetas se propagan en función de la similitud entre los datos y los datos etiquetados.
En general, el aprendizaje semisupervisado es una potente técnica de aprendizaje automático, ya que permite utilizar datos etiquetados y no etiquetados para entrenar un algoritmo. De este modo, el algoritmo puede aprovechar ambas fuentes de datos y obtener resultados más precisos.