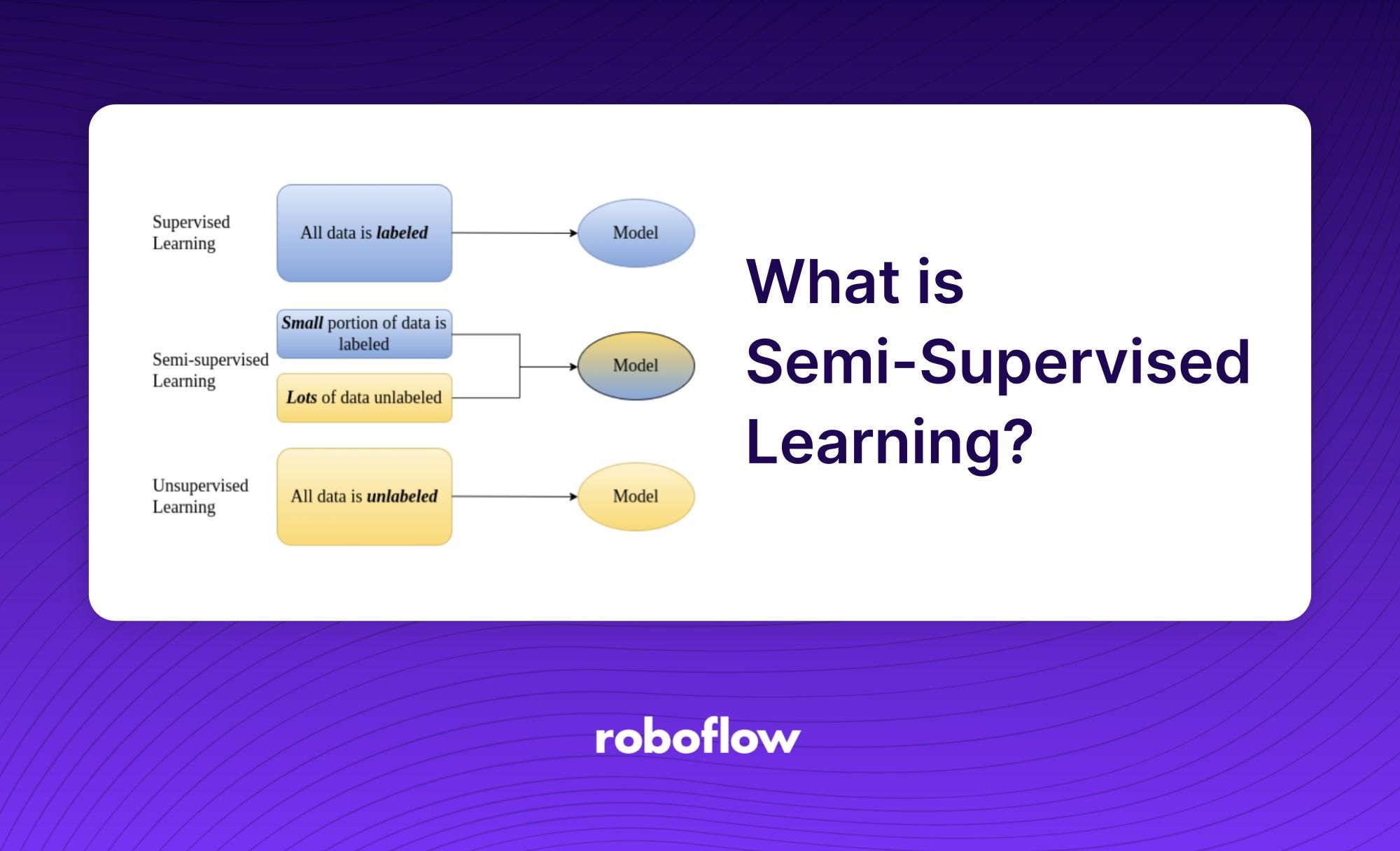
O aprendizado semissupervisionado é um subcampo do aprendizado de máquina que usa dados rotulados e não rotulados para treinar um algoritmo. O objetivo do aprendizado semissupervisionado é usar os dados não rotulados para complementar os dados rotulados. Isso permite que o processo de treinamento tenha mais informações para ser treinado e, ao mesmo tempo, use apenas uma fração da quantidade de dados rotulados. O aprendizado semissupervisionado é uma forma de aprendizado supervisionado, pois usa alguns dados rotulados, mas é diferente porque também aproveita os dados não rotulados.
A ideia subjacente do aprendizado semissupervisionado é que, em geral, é mais fácil perceber as regras dos dados não rotulados do que as regras dos dados rotulados. Também é comumente usado quando apenas uma pequena quantidade de dados rotulados está disponível. Por esse motivo, tornou-se uma abordagem popular no campo da aprendizagem de máquina.
Há muitos tipos de algoritmos de aprendizado semissupervisionado. Esses algoritmos geralmente se enquadram em uma de duas categorias: modelos generativos ou modelos discriminativos. Os modelos generativos são algoritmos que tentam modelar a distribuição dos dados, enquanto os modelos discriminativos são algoritmos que tentam modelar as diferenças entre as classes com base nos dados. Veja a seguir alguns exemplos de algoritmos semissupervisionados:
- Redes Adversariais Generativas (GANs): As GANs são um tipo de modelo generativo que usa duas redes neurais (geradora e discriminadora) para gerar novos dados que seguem a distribuição do conjunto de dados original. As GANs podem ser usadas para aprendizado semissupervisionado, pois são capazes de gerar dados do conjunto de dados original para aumentar os dados para treinamento.
- Auto-treinamento: O autotreinamento é um tipo de técnica de aprendizagem semissupervisionada em que um algoritmo é treinado em um conjunto de dados rotulados e, em seguida, usado para gerar rótulos para os dados não rotulados correspondentes. Os rótulos de saída são então usados como parte dos dados rotulados para o treinamento do modelo.
- Propagação de rótulos: A propagação de rótulos é um tipo específico de técnica de aprendizado semissupervisionado em que os rótulos são propagados dos dados rotulados para os dados não rotulados ao redor. Os rótulos são propagados com base na semelhança entre os dados e os dados rotulados.
De modo geral, o aprendizado semissupervisionado é uma técnica poderosa para o aprendizado de máquina, pois permite o uso de dados rotulados e não rotulados para treinar um algoritmo. Isso permite que o algoritmo aproveite ambas as fontes de dados e, portanto, seja capaz de produzir resultados mais precisos.