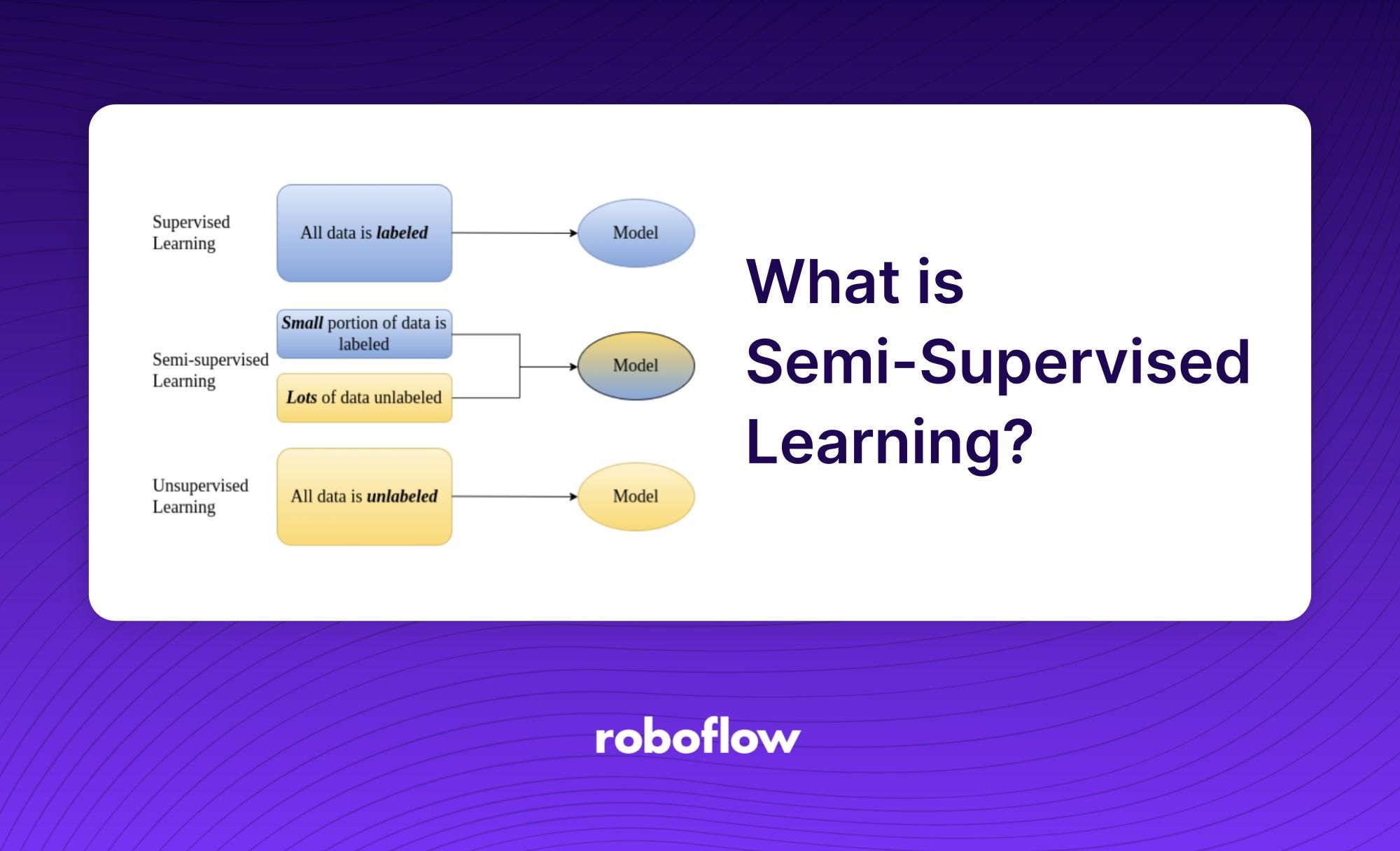
Semi-supervised learning is a sub-field of machine learning that uses both labelled and unlabelled data to train an algorithm. The aim of semi-supervised learning is to make use of the unlabelled data to supplement the labelled data. This allows the training process to have more information to be trained from while still using only a fraction of the amount of labelled data. Semi-supervised learning is a form of supervised learning as it uses some labelled data, but is different in that it also takes advantage of unlabelled data.
The underlying idea of semi-supervised learning is that it is usually easier to realize the rules of unlabelled data than the rules of labelled data. It is also commonly used when only a small amount of labelled data is available. Because of this, it has become a popular approach in the field of machine learning.
There are many types of semi-supervised learning algorithms. These algorithms usually fall into one of two categories: generative models or discriminative models. Generative models are algorithms that attempt to model the distribution of data, while discriminative models are algorithms that attempt to model the differences between classes given the data. Below are a few examples of semi-supervised algorithms:
• Generative Adversarial Networks (GANs): GANs are a type of generative model that use two neural networks (generator and discriminator) to generate new data that follows the distribution of the original dataset. GANs can be used for semi-supervised learning as they are able to generate data from the original dataset in order to augment the data for training.
• Self-training: Self-training is a type of semi-supervised learning technique in which an algorithm is trained on a labelled dataset and then used to output labels for the corresponding unlabelled data. The output labels are then used as part of the labelled data for the model to train on.
• Label Propagation: Label propagation is a specific type of semi-supervised learning technique in which labels are propagated from labelled data to the surrounding unlabelled data. The labels are propagated based on the similarity of the data and the labelled data.
Overall, semi-supervised learning is a powerful technique for machine learning as it allows the use of both labelled and unlabelled data to train an algorithm. This allows the algorithm to leverage both sources of data and therefore is able to produce more accurate results.