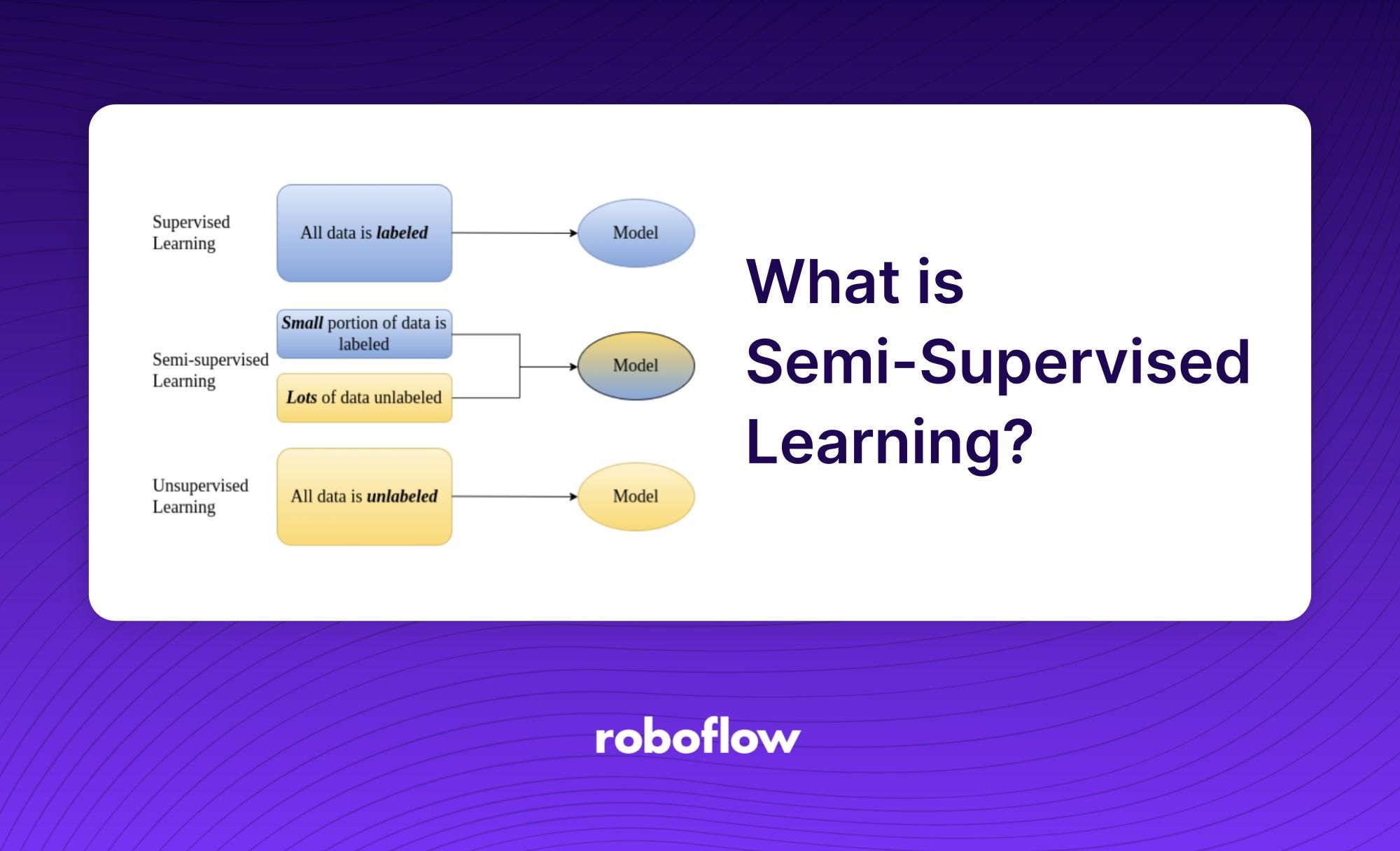
L'apprentissage semi-supervisé est un sous-domaine de l'apprentissage automatique qui utilise à la fois des données étiquetées et non étiquetées pour former un algorithme. L'objectif de l'apprentissage semi-supervisé est d'utiliser les données non étiquetées pour compléter les données étiquetées. Cela permet au processus de formation de disposer de plus d'informations tout en n'utilisant qu'une fraction de la quantité de données étiquetées. L'apprentissage semi-supervisé est une forme d'apprentissage supervisé puisqu'il utilise certaines données étiquetées, mais il est différent en ce sens qu'il tire également profit des données non étiquetées.
L'idée sous-jacente de l'apprentissage semi-supervisé est qu'il est généralement plus facile de réaliser les règles des données non étiquetées que celles des données étiquetées. Il est également couramment utilisé lorsque seule une petite quantité de données étiquetées est disponible. C'est pourquoi il est devenu une approche populaire dans le domaine de l'apprentissage automatique.
Il existe de nombreux types d'algorithmes d'apprentissage semi-supervisé. Ces algorithmes se classent généralement dans l'une des deux catégories suivantes : les modèles génératifs ou les modèles discriminatifs. Les modèles génératifs sont des algorithmes qui tentent de modéliser la distribution des données, tandis que les modèles discriminatifs sont des algorithmes qui tentent de modéliser les différences entre les classes en fonction des données. Voici quelques exemples d'algorithmes semi-supervisés :
- Réseaux adversoriels génératifs (GAN) : Les GAN sont un type de modèle génératif qui utilise deux réseaux neuronaux (générateur et discriminateur) pour générer de nouvelles données qui suivent la distribution de l'ensemble de données d'origine. Les GAN peuvent être utilisés pour l'apprentissage semi-supervisé car ils sont capables de générer des données à partir de l'ensemble de données d'origine afin d'augmenter les données pour la formation.
- Auto-apprentissage : L'auto-apprentissage est un type de technique d'apprentissage semi-supervisé dans lequel un algorithme est formé sur un ensemble de données étiquetées, puis utilisé pour produire des étiquettes pour les données non étiquetées correspondantes. Les étiquettes de sortie sont ensuite utilisées comme partie des données étiquetées sur lesquelles le modèle s'entraîne.
- Propagation d'étiquettes : La propagation des étiquettes est un type spécifique de technique d'apprentissage semi-supervisé dans lequel les étiquettes sont propagées des données étiquetées aux données environnantes non étiquetées. Les étiquettes sont propagées en fonction de la similarité entre les données et les données étiquetées.
Globalement, l'apprentissage semi-supervisé est une technique puissante pour l'apprentissage automatique, car il permet d'utiliser à la fois des données étiquetées et non étiquetées pour former un algorithme. Cela permet à l'algorithme d'exploiter les deux sources de données et donc de produire des résultats plus précis.