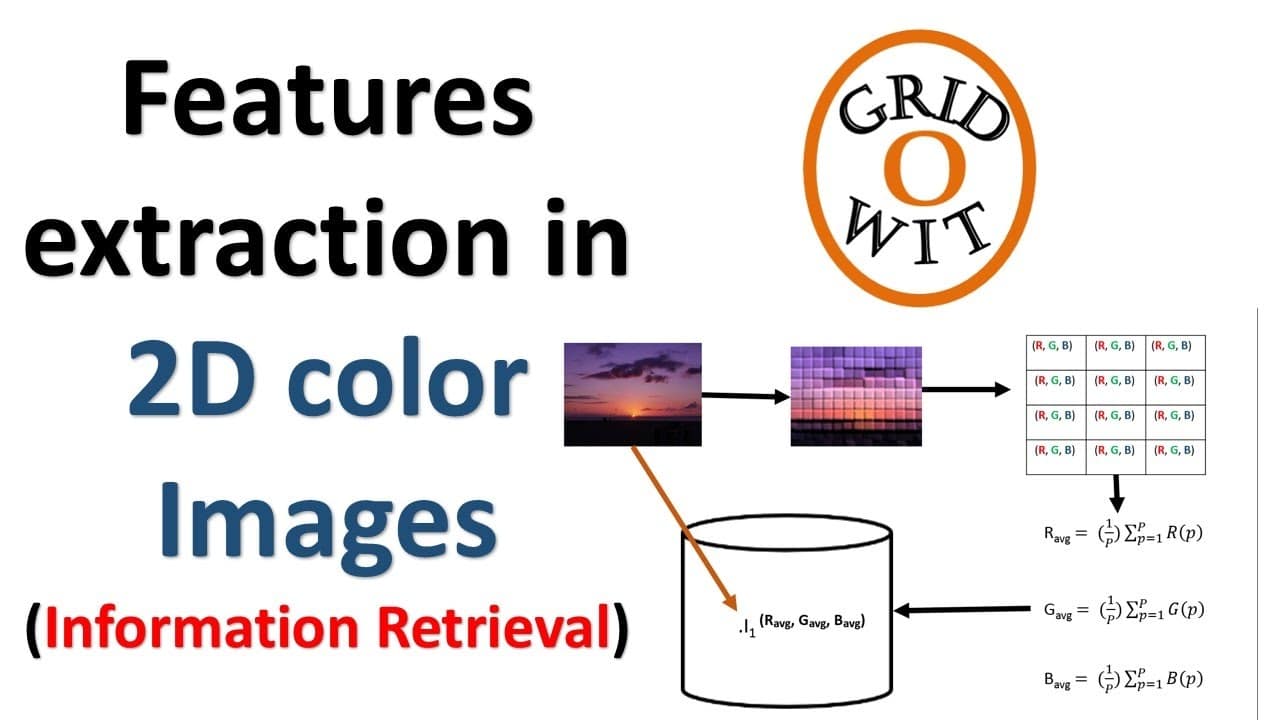
特徴抽出は、生データから意味のある情報を抽出し、特定の目的に使用するプロセスです。これは、データセットの重要な特性を特定し、特定のタスクの予測可能性と最適化を可能にするモデルを作成するために、コンピューター、プログラミング、サイバーセキュリティの分野で最も一般的に使用されています。
特徴抽出のプロセスは、データが使用されている環境からデータを解放し、さらなる処理に備えるデータの前処理から始まります。一般的な前処理ステップには、データ クリーニング、正規化、スケーリング、サンプリング、特徴選択、次元削減が含まれます。データが前処理された後、意味のある特徴の抽出が行われます。
特徴抽出は手動で行うこともできますが、通常は機械学習と自動特徴検出を通じて行われます。自動特徴抽出では、多くの場合、主成分分析 (PCA) や線形判別分析 (LDA) などのアルゴリズムを使用して、データ セットから関連する特徴を特定します。これらのアルゴリズムは、データの次元を削減し、モデルの構築に使用できるパターンを識別するために使用されます。
サイバーセキュリティの分野では、特徴抽出を使用してデータ内のパターンを識別し、悪意のあるアクティビティの検出を可能にするモデルを作成します。閲覧行動、ネットワークリクエスト、アップロードされたファイルなど、ユーザーが生成したデータから特徴を抽出することで、悪意のあるアクティビティを検出できるモデルを構築できます。
特徴抽出は、コンピューター サイエンス、プログラミング、サイバーセキュリティの分野における重要なプロセスです。これを使用して、生データから重要な特性を特定し、モデルを構築し、悪意のあるアクティビティを検出できます。特徴抽出を利用すると、特定のタスクの予測と最適化に使用できるモデルを作成できます。