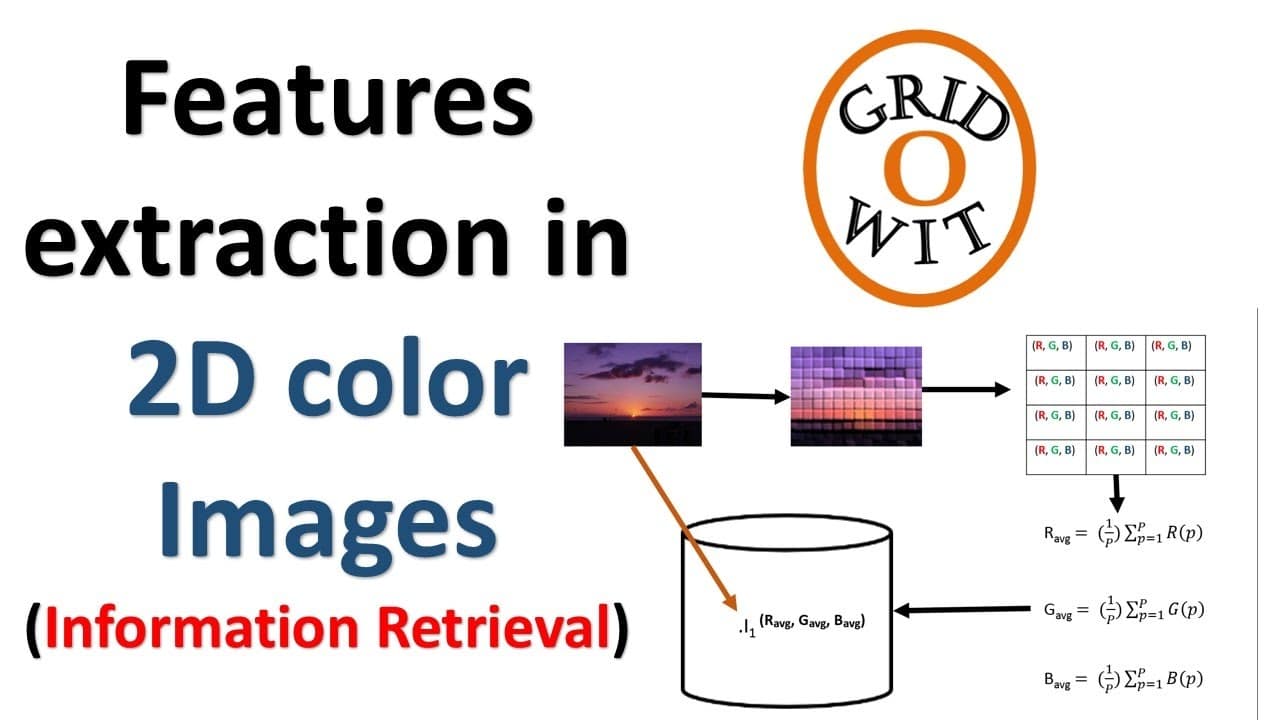
Ekstrakcja cech to proces, podczas którego z surowych danych wydobywane są istotne informacje i wykorzystywane w określonym celu. Najczęściej stosowana jest w dziedzinie komputerów, programowania i cyberbezpieczeństwa, w celu identyfikacji ważnych cech w zbiorach danych i tworzenia modeli, które pozwalają na przewidywalność i optymalizację konkretnego zadania.
Proces ekstrakcji cech rozpoczyna się od wstępnego przetwarzania danych, które polega na uwolnieniu danych ze środowiska, w którym są wykorzystywane, i przygotowaniu ich do dalszego przetwarzania. Typowe etapy przetwarzania wstępnego obejmują czyszczenie danych, normalizację, skalowanie, próbkowanie, wybór funkcji i redukcję wymiarowości. Po wstępnym przetworzeniu danych następuje wyodrębnienie istotnych cech.
Ekstrakcję funkcji można przeprowadzić ręcznie, ale zwykle odbywa się to poprzez uczenie maszynowe i automatyczne wykrywanie funkcji. Zautomatyzowana ekstrakcja cech często wykorzystuje algorytmy, takie jak analiza głównych składowych (PCA) i liniowa analiza dyskryminacyjna (LDA), w celu zidentyfikowania odpowiednich cech ze zbioru danych. Algorytmy te służą do zmniejszania wymiarowości danych i identyfikowania wzorców, które można wykorzystać do budowy modeli.
W obszarze cyberbezpieczeństwa ekstrakcja cech służy identyfikacji wzorców w danych i tworzeniu modeli pozwalających na wykrycie szkodliwej aktywności. Wyodrębniając funkcje z danych generowanych przez użytkowników, takie jak zachowanie przeglądania, żądania sieciowe i przesłane pliki, możliwe jest budowanie modeli wykrywających złośliwą aktywność.
Ekstrakcja cech to ważny proces w dziedzinie informatyki, programowania i cyberbezpieczeństwa. Można go używać do identyfikowania ważnych cech na podstawie surowych danych, tworzenia modeli i wykrywania złośliwej aktywności. Wykorzystując ekstrakcję cech, możliwe jest tworzenie modeli, które można wykorzystać do przewidywania i optymalizacji konkretnych zadań.