共参照解決は、テキストまたは会話内の代名詞またはその他の用語を識別および分析し、それらがどの実体を参照しているかを判断するプロセスです。自然言語処理 (NLP) では、大量のテキストから意味のある情報を抽出するために使用されます。また、対話システムでも一般的に使用されており、機械が人間の言語をよりよく理解するのに役立ちます。
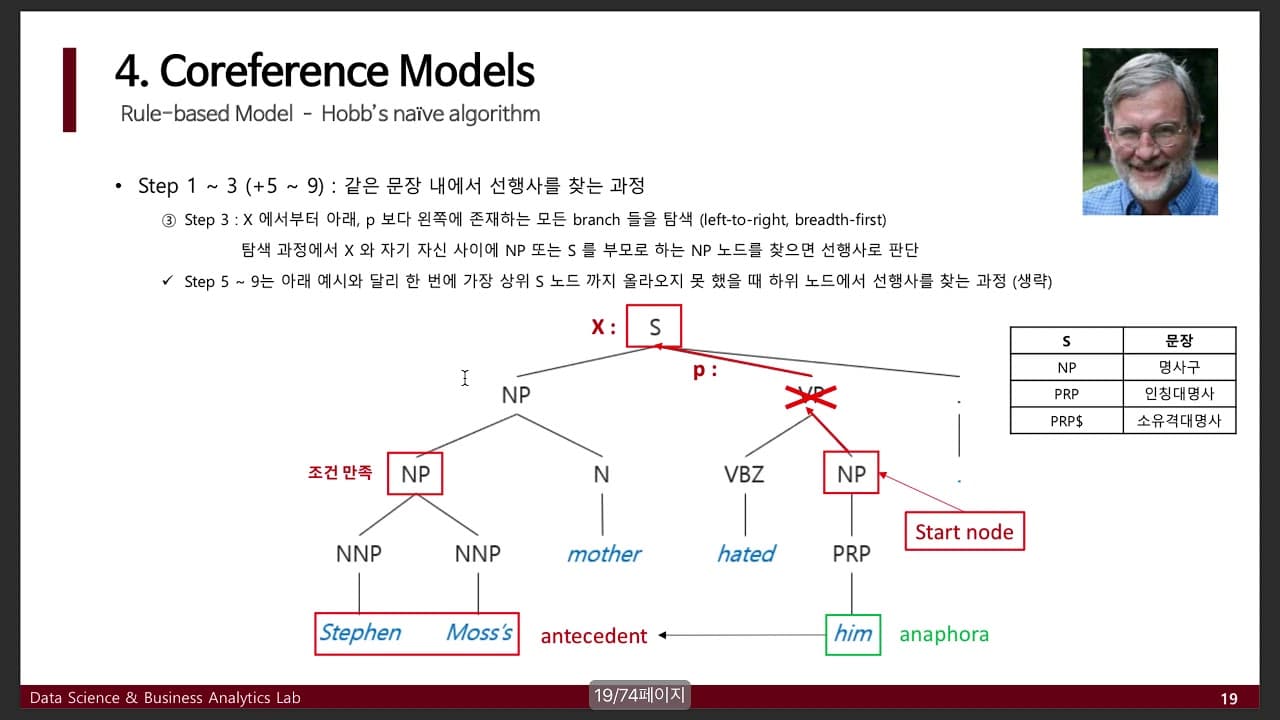
相互参照の解決は、ルールベースのシステムを使用するか、機械学習ベースのシステムを使用するかの 2 つの方法で実行できます。ルールベースのシステムでは、コンピューターは、特定の語句や単語の参照を判断するのに役立つテキスト内の特定のパターンを探すようにプログラムされています。機械学習技術では、さまざまなアルゴリズムを使用して、同様の方法で参照を識別および解決するために使用されるモデルを生成します。
相互参照解決のタスクは、テキスト内のエンティティとそれらの関係の識別が含まれるため、固有表現認識 (NER) の一種と考えることができます。これは、構文解析や意味役割ラベル付けなどの他の NLP タスクと組み合わせて使用されることがよくあります。
相互参照解決は、会話エージェント、スマート アシスタント、質問応答システム、情報抽出システムなど、多くの自然言語理解 (NLU) アプリケーションで使用されます。テキスト読み上げシステムでも使用され、より自然な音声の応答を生成するのに役立ちます。
共参照解決を使用するNLPシステムは、会話エージェントを認識・理解する際のパフォーマンスを向上させることが示されている。例えば、ある研究では、会話エージェントを、Coreference Resolutionを使用していないシステムと比較した。その結果、共参照を利用したシステムでは、会話を理解する際のパフォーマンスが19%向上した。
全体として、Coreference Resolutionは、テキストや会話から情報を処理し、有用な意味や知識を抽出するための強力なテクニックである。より自然な対話システムの構築、情報抽出の改善、自然言語理解能力の拡張に役立てることができる。