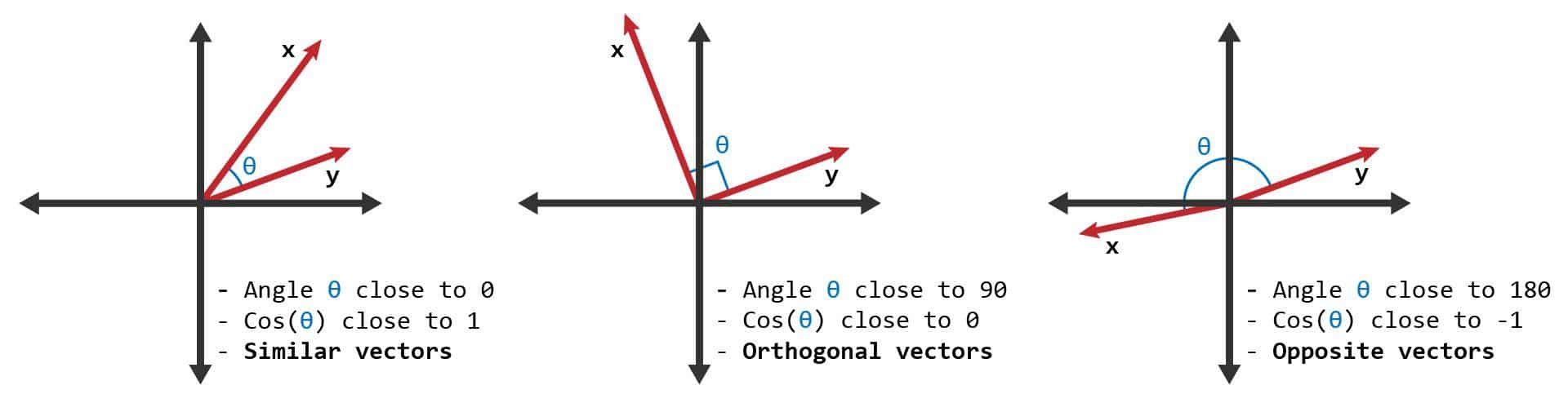
Cosine similarity is a measure of similarity between two non-zero vectors of an inner product space that measures the cosine of the angle between them. It is frequently used in information retrieval and text mining to identify the degree of similarity between two documents. It is also used in machine learning algorithms for facial recognition, object recognition, and other tasks.
Cosine similarity is based on the cosine angle between two non-zero vectors, a and b. The cosine similarity between the two vectors is a numerical representation of their similarity; it ranges from -1 which is completely different, to 1 which is an exact match.
The calculation of cosine similarity is as follows:
cos(θ) = a · b / |a| · |b|
where |a| and |b| are the magnitudes of a and b, and a · b is the dot product of a and b.
Cosine similarity can be used to compare word embeddings, identify related terms, and identify the degree of similarity between documents. It is also used to compare two text documents in order to find text reuse. For example, cosine similarity can be used to identify plagiarism in documents.
In machine learning, cosine similarity is used in object recognition, facial identification, and other tasks. It is a popular method for measuring the similarity between two images, enabling facial recognition applications such as those used in facial biometrics, as well as object recognition applications. Cosine similarity can also be used to identify similar documents in a corpus of text.
Overall, cosine similarity is a popular measure of similarity between two non-zero vectors of an inner product space. It can be used in many different applications in the fields of information retrieval, text mining, machine learning, and more.