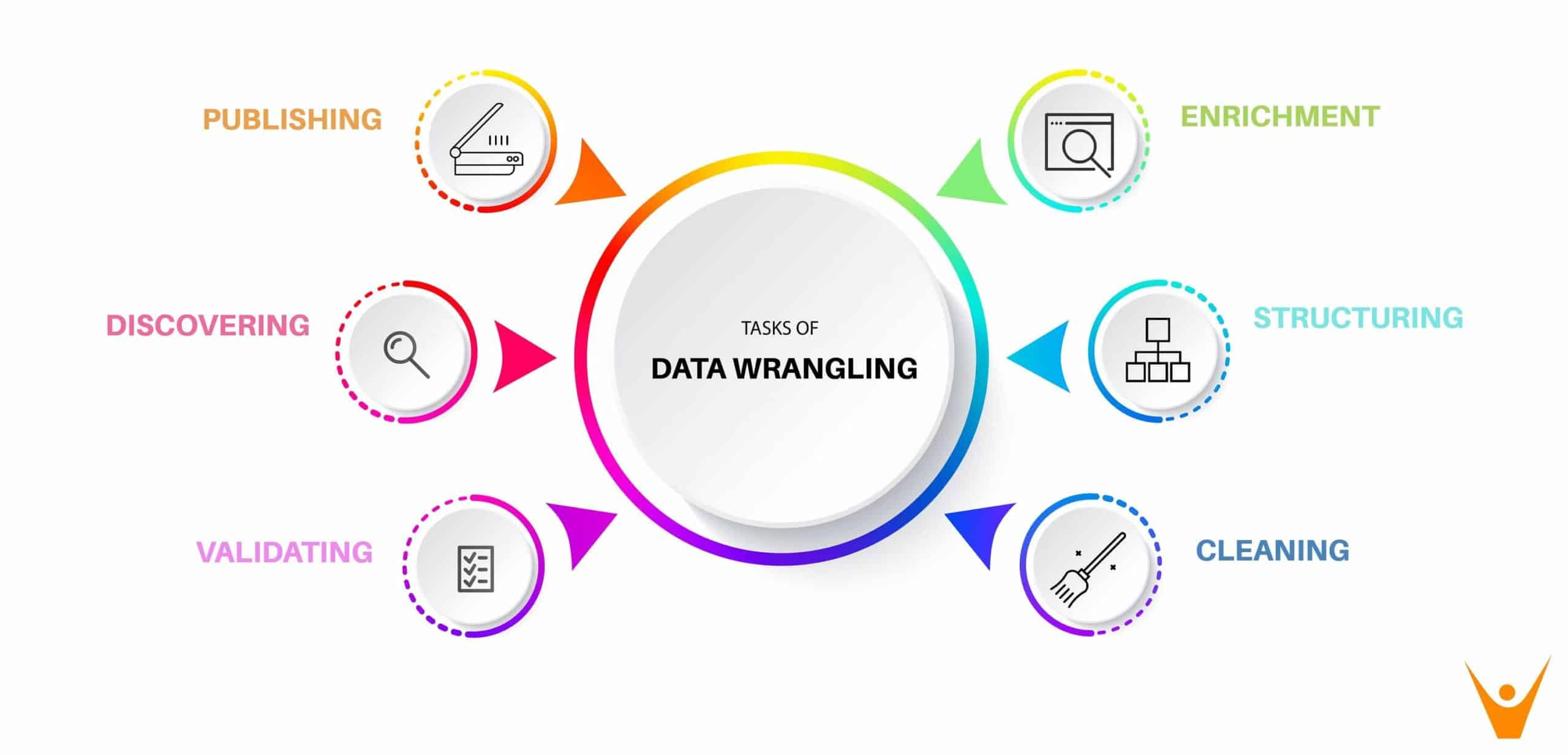
데이터 정리(Data Munging)는 데이터 정리 및 준비에 일반적으로 사용되는 데이터 랭글링 또는 데이터 조작의 한 유형입니다. 데이터 정리에는 원시 데이터를 더 쉽게 분석하거나 시각화할 수 있는 형식으로 변환하는 작업이 포함됩니다. 소프트웨어 엔지니어링, 특히 데이터 마이닝 및 기계 학습에서 가장 자주 사용됩니다. 이 프로세스에는 다양한 소스의 데이터를 CSV와 같은 보다 균일한 형식으로 변환하여 보다 쉽게 구문 분석하고 분석할 수 있도록 하는 작업이 포함됩니다.
데이터 정리에는 여러 소스의 데이터를 단일 형식으로 변환하고, 정렬하고, 이상값을 제거하고, 오류를 수정하고, 누락된 값을 채우고, 값을 결합하거나 분리하는 작업이 포함될 수 있습니다. 또한 당면한 작업에 적합한 새로운 데이터 세트를 생성하기 위해 여러 데이터 세트를 결합하거나 병합하는 작업이 포함될 수도 있습니다. 데이터 시각화는 데이터의 대화형 시각화를 생성하기 위해 데이터 시각화와 함께 사용되는 경우가 많습니다.
데이터 과학자는 원시 데이터를 가져와서 정리하고 추가 분석에 적합한 것으로 변환해야 하는 경우가 많기 때문에 데이터 정리는 데이터 과학에서 중요한 역할을 합니다. 데이터 정리는 예측 모델 구축을 위한 데이터를 준비하는 데 자주 사용되므로 예측 분석에도 유용합니다. 데이터를 이해하고 패턴을 발견함으로써 데이터 통합은 모델 성능과 정확성을 향상시키는 데 도움이 될 수 있습니다.
대규모 데이터 세트는 처리하는 데 시간이 많이 걸릴 수 있으므로 데이터 정리를 사용하여 데이터 세트의 크기를 줄일 수도 있습니다. 필터링, 정렬, 그룹화 등의 데이터 정리 기술을 사용하면 데이터 세트를 관련 정보로 축소하여 처리 속도를 높일 수 있습니다.
데이터 통합은 추가 분석에 사용되기 전에 데이터의 정확성과 유효성을 보장하는 데 도움이 되므로 모든 데이터 과학 프로세스에서 중요한 부분입니다. 데이터 과학자는 데이터를 적절하게 조작함으로써 데이터가 추가 분석에 적합하고 가능한 최상의 통찰력을 제공할 수 있는지 확인할 수 있습니다.