MapReduce è un modello di programmazione utilizzato per attività di calcolo distribuito. Si basa su un approccio divide et impera per risolvere problemi computazionali complessi suddividendoli in parti più piccole e più gestibili. Il modello MapReduce viene utilizzato principalmente su set di dati di grandi dimensioni e di solito si basa su un cluster di server di base per la potenza di calcolo.
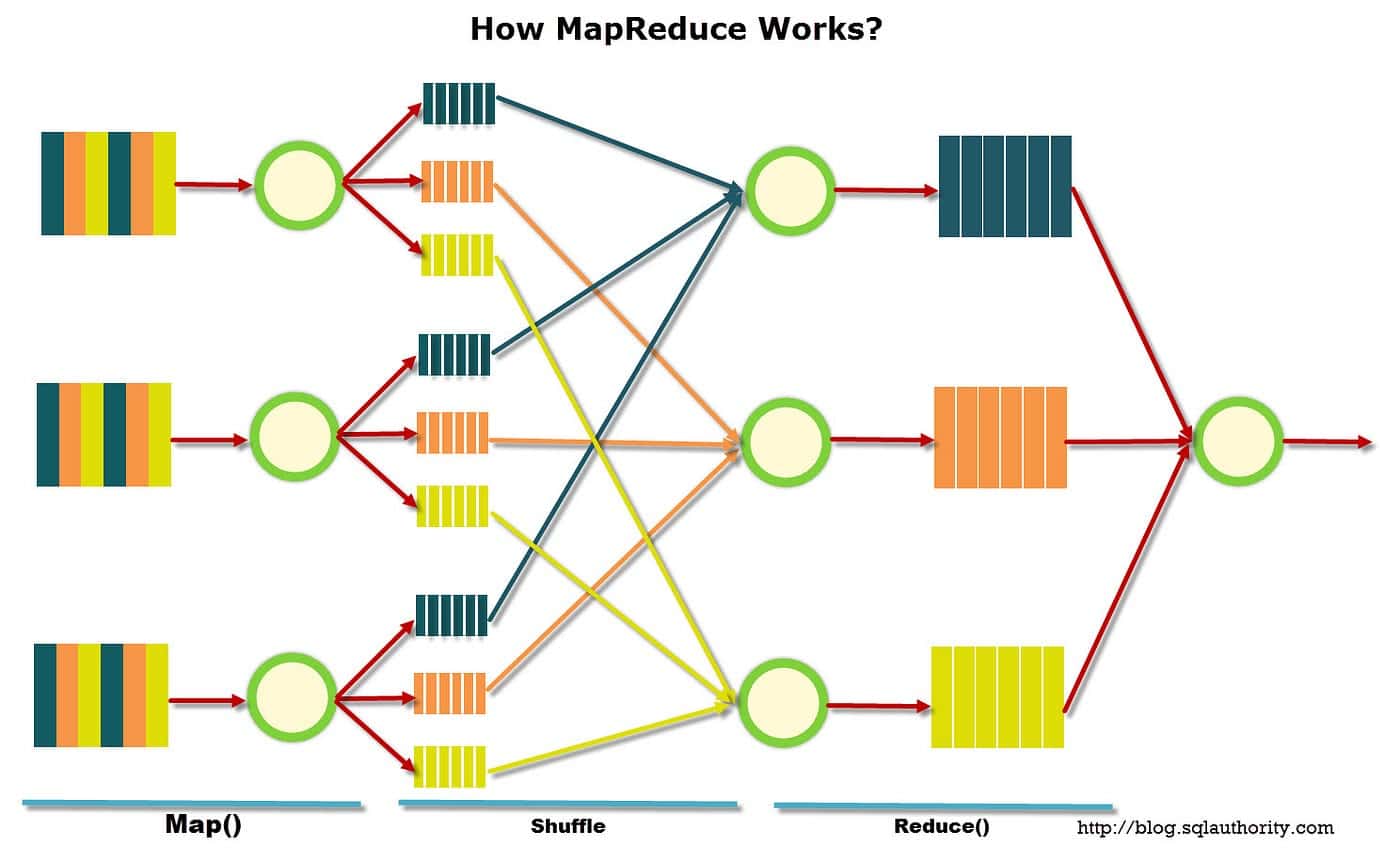
MapReduce è stato introdotto per la prima volta dai ricercatori di Google nel 2004 e da allora è diventato uno strumento popolare per l'analisi e l'elaborazione dei dati. Questo modello prevede due fasi distinte: la fase di mappatura e quella di riduzione.
Nella fase della mappa, i dati vengono suddivisi in blocchi chiamati “split”. Ogni suddivisione viene assegnata a un mappatore che elabora i dati e restituisce un set di coppie chiave-valore. Le coppie chiave-valore vengono quindi inserite nella fase di riduzione, dove vengono ordinate e aggregate in un unico output.
Il modello MapReduce è utile per molte attività, tra cui data mining, machine learning ed elaborazione del linguaggio naturale. Viene spesso utilizzato per analizzare grandi quantità di dati, come registri Web e registri di server, e per elaborare rapidamente grandi set di dati.
MapReduce è stato integrato in molti linguaggi di programmazione popolari, come Java, Python e C#, ed è supportato da diverse piattaforme popolari, come Hadoop e Apache Spark. Di conseguenza, è diventato uno strumento comune per l’elaborazione e l’analisi dei dati e viene utilizzato da un’ampia varietà di organizzazioni per aiutarle a trarre valore da grandi set di dati.