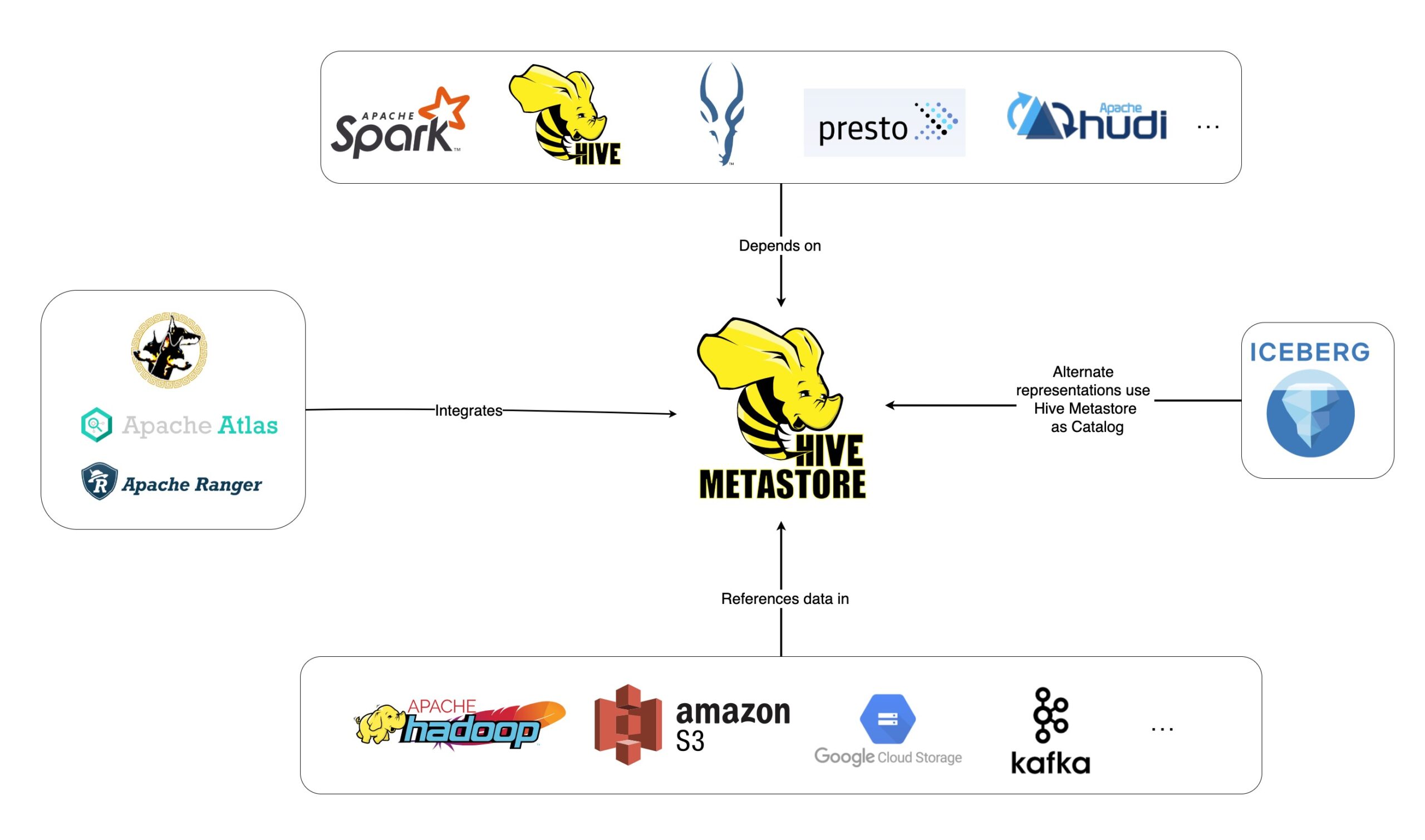
Apache Hive je systém datového skladu s otevřeným zdrojovým kódem vyvinutý pro usnadnění čtení, zápisu a správy velkých datových sad uložených v distribuovaném úložišti. Je napsán v Javě a vyvinutý Apache Software Foundation a slibuje, že usnadní efektivní dotazování a analýzu dat uložených v Hadoop Distributed File System (HDFS).
Apache Hive se používá pro sumarizaci dat, dotazy a analýzu velkých datových sad uložených v clusteru Hadoop. Umožňuje přístup k datům uloženým v HDFS prostřednictvím různých programovacích jazyků, jako je Java, Python a Ruby. HiveQL (Hive Query Language) je dotazovací jazyk používaný k provádění dotazů a analýze dat uložených v Apache Hive. HiveQL je v podstatě kombinací SQL a Hadoop, což umožňuje použití Hive jako datového skladu.
Hive je skvělá volba pro analýzu dat, protože se používá mnohem snadněji než Hadoop. Apache Hive poskytuje efektivní způsob, jak organizovat a analyzovat data uložená v clusteru Hadoop. Kromě toho je Apache Hive schopen pracovat s masivními datovými sadami a lze jej snadno škálovat, aby pojal obrovské množství dat. Je také vysoce spolehlivý a zajišťuje, že data jsou vždy aktuální.
Kromě analýzy dat se Hive používá také pro ad-hoc provádění dotazů a dolování dat. Hive podporuje sofistikované bezpečnostní funkce, které uživatelům umožňují chránit svá data před škodlivými útoky. Kromě toho podporuje různé formáty úložiště, jako je ORC, Parquet, Avro a Thrift.
Apache Hive poskytuje mnoho funkcí a výhod vývojářům i datovým analytikům. Open-source základ umožňuje uživatelům plně využívat funkce a nástroje platformy. Zjednodušuje také proces provádění komplexní analýzy dat.