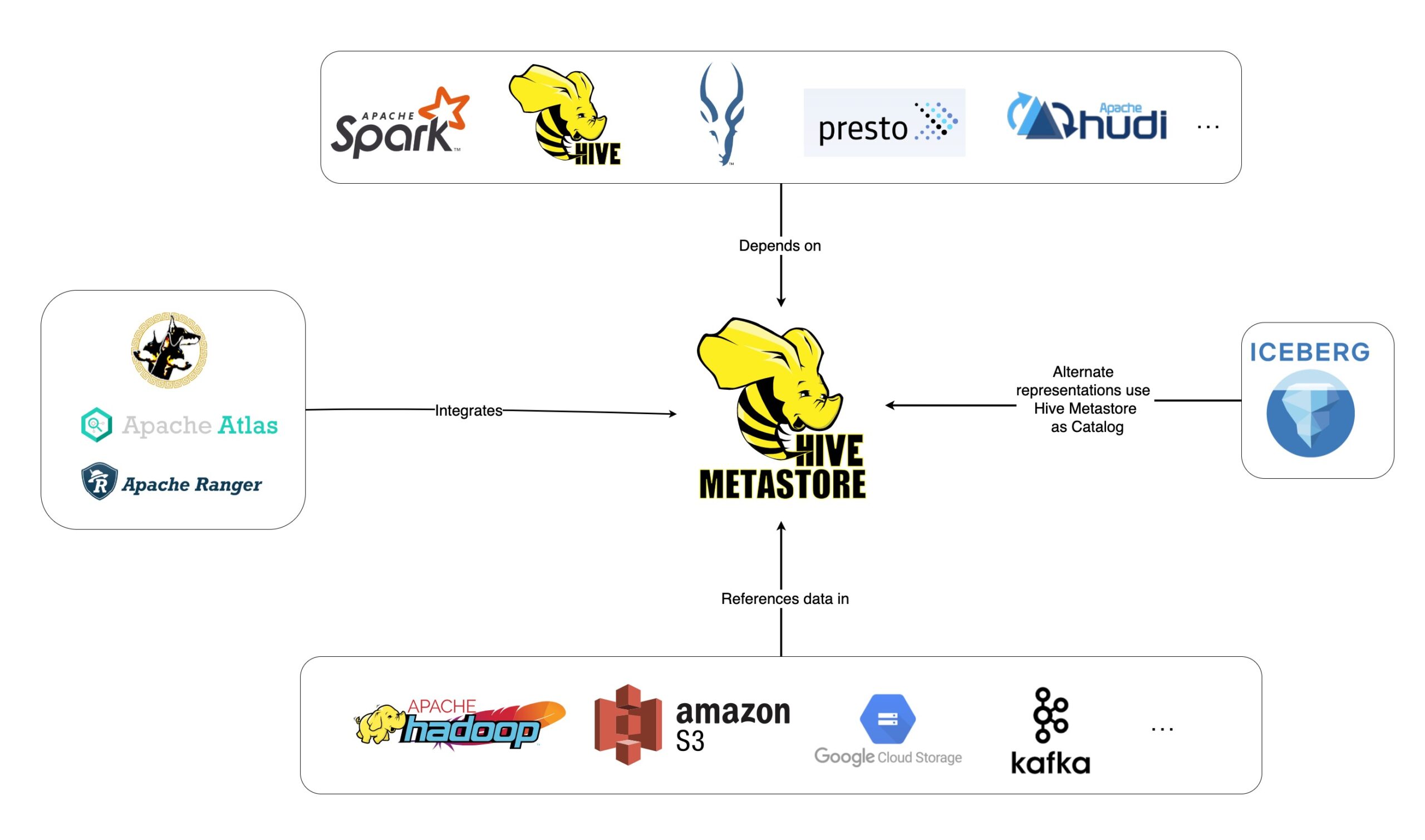
Apache Hive to system hurtowni danych typu open source opracowany w celu ułatwienia odczytu, zapisu i zarządzania dużymi zbiorami danych przechowywanymi w pamięci rozproszonej. Napisany w Javie i opracowany przez Apache Software Foundation, ma ułatwić wydajne wykonywanie zapytań i analizę danych przechowywanych w rozproszonym systemie plików Hadoop (HDFS).
Apache Hive służy do podsumowywania danych, zapytań i analizy dużych zbiorów danych przechowywanych w klastrze Hadoop. Umożliwia dostęp do danych przechowywanych w systemie HDFS za pośrednictwem różnych języków programowania, takich jak Java, Python i Ruby. HiveQL (Hive Query Language) to język zapytań używany do wykonywania zapytań i analizowania danych przechowywanych w Apache Hive. HiveQL to w zasadzie połączenie SQL i Hadoop, dzięki czemu Hive może być używany jako hurtownia danych.
Hive to świetny wybór do analizy danych, ponieważ jest znacznie łatwiejszy w użyciu niż Hadoop. Apache Hive zapewnia efektywny sposób organizowania i analizowania danych przechowywanych w klastrze Hadoop. Co więcej, Apache Hive może pracować z ogromnymi zbiorami danych i można go łatwo skalować, aby pomieścić ogromne ilości danych. Jest także wysoce niezawodny, dzięki czemu dane są zawsze aktualne.
Oprócz analizy danych Hive służy również do wykonywania zapytań ad hoc i eksploracji danych. Hive obsługuje zaawansowane funkcje bezpieczeństwa, które pozwalają użytkownikom chronić swoje dane przed złośliwymi atakami. Ponadto obsługuje różne formaty przechowywania, takie jak ORC, Parquet, Avro i Thrift.
Apache Hive zapewnia wiele funkcji i korzyści zarówno programistom, jak i analitykom danych. Podstawa open source pozwala użytkownikom w pełni korzystać z funkcji i narzędzi platformy. Upraszcza także proces przeprowadzania złożonej analizy danych.