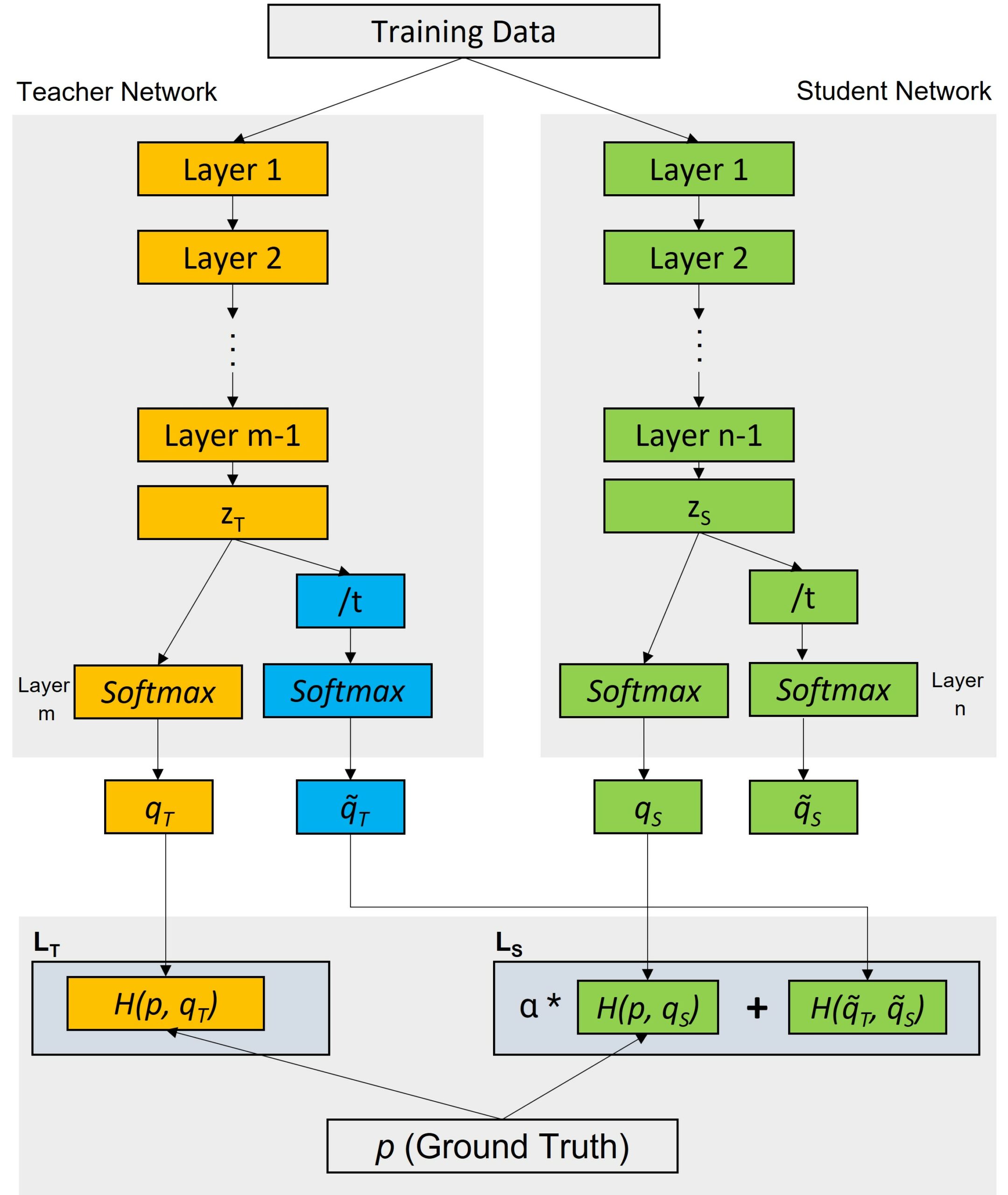
Knowledge distillation is a process for transferring information and knowledge from one source to another. It can be used to create new machine learning models by distilling existing ones, or to impart knowledge from expert to novice systems. It also refers to the practice of transferring knowledge, such as rules or models, from an original source to systems that are less powerful and have fewer resources.
Knowledge distillation processes can involve two main stages: a “teacher” model produces a softened version of the data, which is then used to train the “student” model. Knowledge distillation can help address the problem of over-fitting, where the model is overly specialized and performs poorly with new data. The “teacher” model produces a probabilistic view of the data to give the student an idea of how uncertain it is with respect to each prediction. During the “student” model’s training, soft targets are used instead of the actual labels, improving the generalization performance of the student model.
Knowledge distillation is used in both supervised and unsupervised learning. In supervised learning, knowledge distillation helps reduce the computational costs of model training by transferring knowledge between different architectures. For example, knowledge distillation can be used to compress models with costly annotations while maintaining accuracy. In unsupervised learning, knowledge distillation suggests parameter sharing amongst multiple sources with varying relationships to help enhance the model’s capacity to generate multiple representations of data.
Knowledge distillation can be implemented with a variety of techniques. One common approach is a “hint-based” approach, which involves providing limited information on the desired output to the student model. Another technique, the “fading factor” technique, is used to distribute the knowledge from the teacher to the student by slowly reducing the influence of the former over time.
Overall, knowledge distillation is a powerful tool for transferring complex information from a source to downstream systems or contexts. It has applications in both supervised and unsupervised learning, reducing training costs and improving the accuracy of models.