MapReduce to model programowania używany do zadań przetwarzania rozproszonego. Opiera się na podejściu „dziel i rządź” do rozwiązywania złożonych problemów obliczeniowych poprzez podzielenie ich na mniejsze, łatwiejsze w zarządzaniu części. Model MapReduce jest używany głównie w przypadku dużych zbiorów danych i zwykle opiera się na klastrze standardowych serwerów pod względem mocy obliczeniowej.
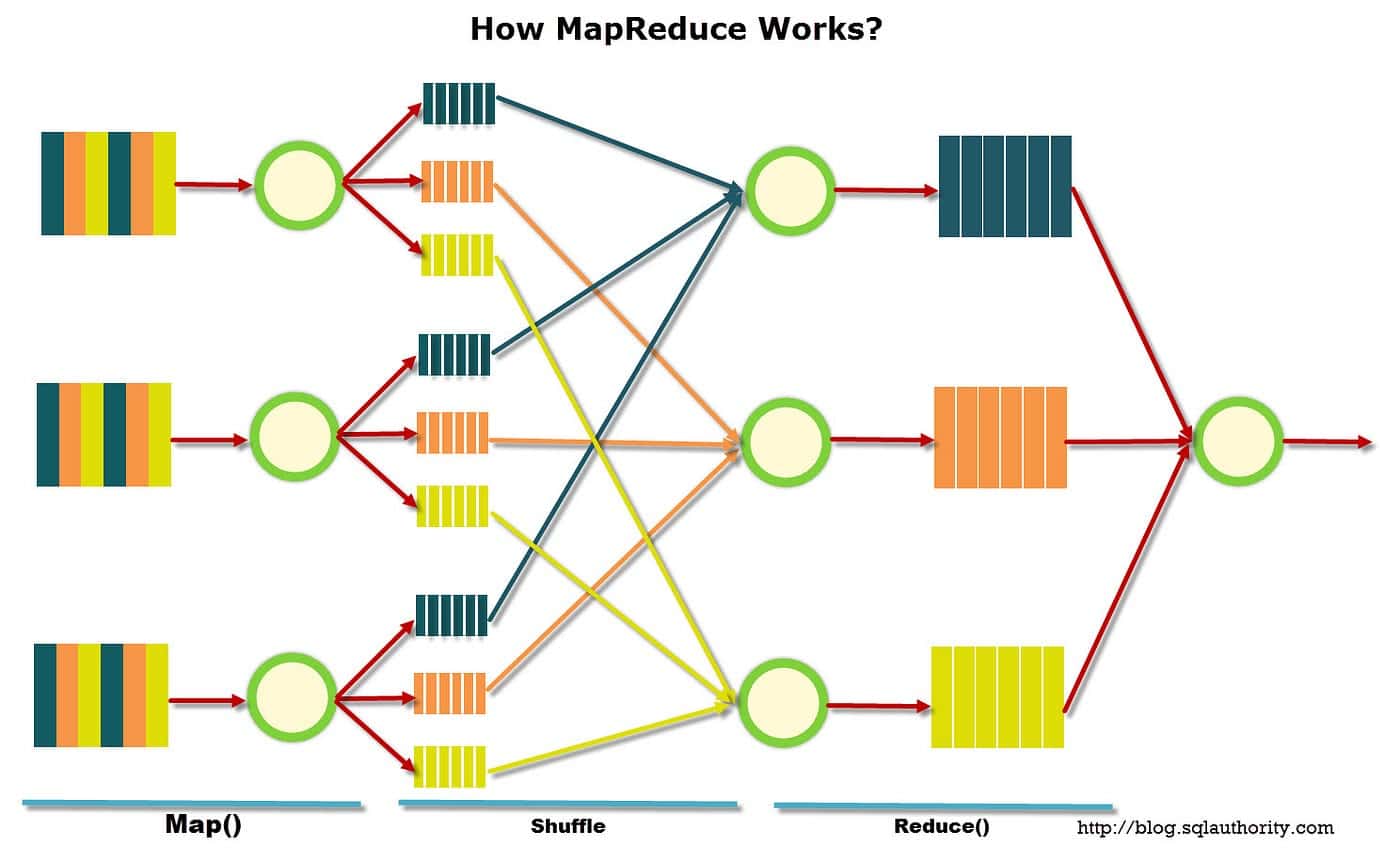
MapReduce został po raz pierwszy wprowadzony przez badaczy Google w 2004 roku i od tego czasu stał się popularnym narzędziem do analizy i przetwarzania danych. W modelu tym występują dwa odrębne etapy - faza mapowania i faza redukcji.
Na etapie mapy dane są dzielone na fragmenty zwane „podziałami”. Każdy podział jest przypisany do programu odwzorowującego, który przetwarza dane i generuje zestaw par klucz-wartość. Pary klucz-wartość są następnie wprowadzane do fazy redukcji, gdzie są sortowane i agregowane w jeden wynik.
Model MapReduce jest przydatny w wielu zadaniach, w tym eksploracji danych, uczeniu maszynowym i przetwarzaniu języka naturalnego. Najczęściej wykorzystuje się go do analizy dużych ilości danych, takich jak dzienniki sieciowe i logi serwerów, oraz do szybkiego przetwarzania dużych zbiorów danych.
MapReduce został zintegrowany z wieloma popularnymi językami programowania, takimi jak Java, Python i C#, i jest obsługiwany przez kilka popularnych platform, takich jak Hadoop i Apache Spark. W rezultacie stało się powszechnym narzędziem do przetwarzania i analizy danych i jest wykorzystywane przez wiele różnych organizacji, aby pomóc im czerpać wartość z dużych zbiorów danych.