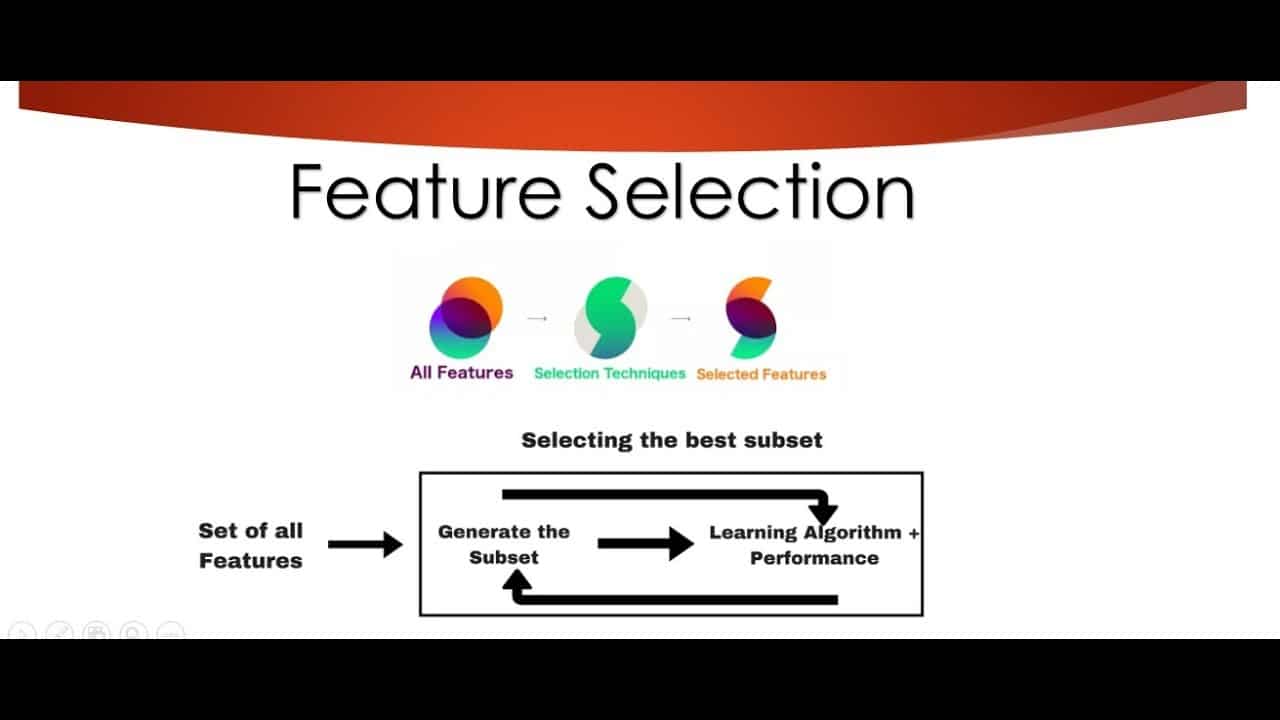
특징 선택은 알고리즘의 정확성과 신뢰성을 높이기 위해 데이터의 특징 하위 집합을 선택하는 프로세스입니다. 일반적으로 머신 러닝에서 예측 모델의 정확도를 향상시키기 위한 방법으로 사용됩니다. 특징 선택은 모델의 복잡성을 줄이고 모델을 더 효율적이고 해석하기 쉽게 만듭니다.
가장 간단한 형태로, 특징 선택은 주어진 데이터 세트에서 특징의 하위 집합을 선택하는 방법입니다. 이 프로세스에는 당면한 작업과 관련하여 가장 관련성이 높은 특징을 선택하고 관련성이 낮은 특징을 제거하는 과정이 포함됩니다. 예를 들어 이미지 데이터 세트에서 고양이 이미지를 감지하려는 경우, 가장 관련성이 높은 특징은 고양이와 관련된 특징(예: 털 색깔, 귀 모양 등)이 될 것입니다.
필터 방법, 래퍼 방법, 임베디드 방법, 하이브리드 방법 등 여러 가지 특징 선택 접근 방식을 사용할 수 있습니다. 필터 방법은 상관관계와 같은 메트릭에 따라 데이터 집합의 특징을 평가하고 상관관계가 가장 높은 특징을 선택하는 것입니다. 래퍼 방식은 예측 알고리즘을 사용하여 피처를 평가하는 방식이며, 임베디드 방식은 학습 과정에서 알고리즘을 사용하여 피처를 학습하는 방식입니다. 하이브리드 방식은 필터 방식과 래퍼 방식과 같은 여러 특징 선택 기법을 결합하여 사용하는 방식입니다.
기능 선택에는 몇 가지 장점이 있습니다. 더 효율적인 모델을 생성하고 결과를 더 쉽게 해석할 수 있습니다. 또한 모델이 너무 복잡하여 이전에 보지 못한 데이터에 대해 더 이상 정확한 예측을 할 수 없을 때 발생하는 과적합 문제를 방지하는 데 도움이 되는 방법이기도 합니다.
결론적으로, 특징 선택은 머신 러닝에서 사용되는 프로세스로, 주어진 데이터 세트에서 특징의 하위 집합을 선택하는 것을 포함합니다. 이는 복잡성과 과적합을 줄이고 보다 효율적이고 해석 가능한 모델을 만드는 방법입니다.