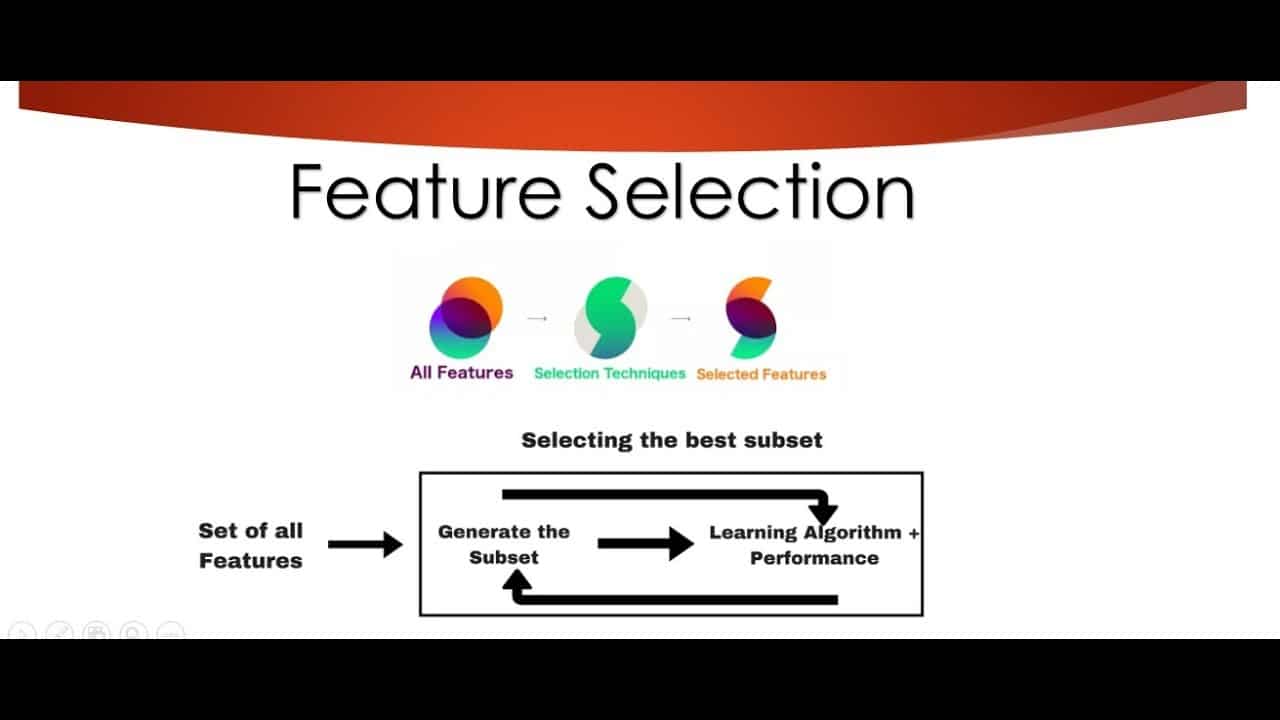
La selección de características es el proceso de seleccionar un subconjunto de características de los datos para que un algoritmo sea más preciso y fiable. Suele utilizarse en el aprendizaje automático para mejorar la precisión de los modelos predictivos. La selección de características reduce la complejidad del modelo y lo hace más eficaz y fácil de interpretar.
En su forma más simple, la selección de características es un método para seleccionar un subconjunto de características de un conjunto de datos determinado. El proceso consiste en seleccionar las características más relevantes para la tarea y eliminar las irrelevantes. Por ejemplo, si se tratara de detectar imágenes de gatos en un conjunto de datos de imágenes, las características más relevantes serían las relacionadas con los gatos (por ejemplo, el color del pelaje, la forma de las orejas, etc.).
Existen varios enfoques para la selección de características que pueden utilizarse, como los métodos de filtro, los métodos de envoltura, los métodos integrados y los métodos híbridos. Los métodos de filtro consisten en evaluar las características del conjunto de datos en función de una métrica, como la correlación, y seleccionar las que tengan la correlación más alta. Los métodos de envoltura implican el uso de un algoritmo predictivo para evaluar las características, mientras que los métodos integrados implican el uso de un algoritmo para aprender de las características durante el proceso de entrenamiento. Los métodos híbridos implican el uso combinado de varias técnicas de selección de características, como los métodos de filtro y de envoltura.
La selección de características tiene varias ventajas. Permite crear modelos más eficaces e interpretar más fácilmente los resultados. También es una forma de ayudar a prevenir el problema del sobreajuste, que se produce cuando un modelo es tan complejo que ya no puede hacer predicciones precisas sobre datos que no ha visto antes.
En conclusión, la selección de características es un proceso utilizado en el aprendizaje automático que consiste en seleccionar un subconjunto de características de un conjunto de datos determinado. Es una forma de reducir la complejidad y el sobreajuste y de crear modelos más eficientes e interpretables.