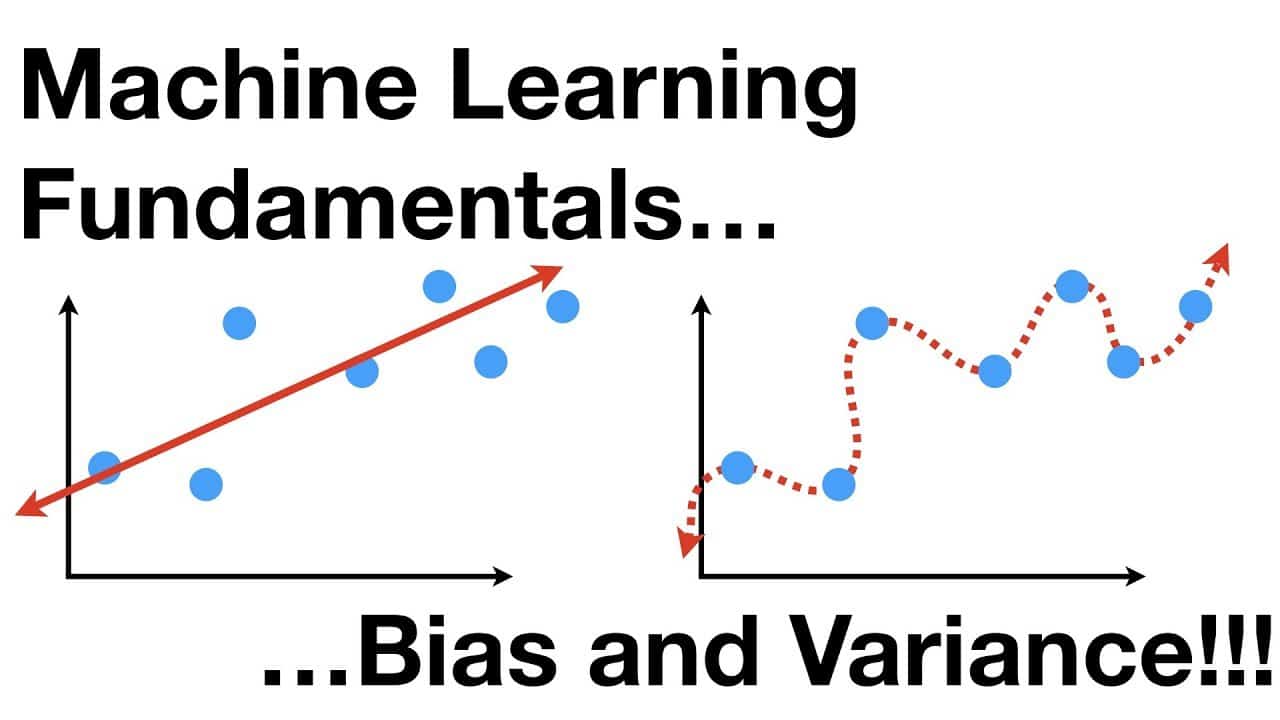
편향과 분산은 컴퓨터 프로그래밍, 기계 학습 및 관련 분야에서 사용되는 통계적 개념입니다. 이 개념은 모델의 예측과 실제 값 사이의 차이인 예측 오류를 최소화하도록 알고리즘을 조정할 수 있는 편향-분산 트레이드오프에서 유래했습니다. 편향성은 알고리즘이 특정 클래스 또는 데이터 유형을 선호하는 정도를 나타냅니다. 반면에 분산은 알고리즘의 예측이 데이터 세트에 따라 얼마나 달라질 수 있는지를 나타내는 척도입니다. 바이어스-분산도 트레이드오프 개념은 예측 모델의 정확도를 최적화하는 데 사용됩니다.
편향성이 높은 모델은 새로운 데이터에 그다지 민감하지 않습니다. 이는 알고리즘이 더 나은 예측을 위해 필요한 복잡성을 고려하지 않기 때문에 적합도 부족 문제로 간주됩니다. 편향성이 높으면 알고리즘이 한 데이터 세트에서 다른 데이터 세트로 중요한 오류를 발생시키지만 중요한 성능은 발휘하지 못합니다. 분산이 높으면 필요한 데이터의 양을 과소평가하고 모델의 성능을 과대평가할 수 있습니다. 과적합 문제는 모델이 데이터에 너무 가깝게 맞추려고 시도하여 새로운 데이터 세트에 대해 예상대로 일반화하지 못하기 때문에 과적합 문제로 간주됩니다.
일반적으로 목표는 매개변수를 최적화하여 적절한 수준의 편향과 분산에 도달하는 것입니다. 즉, 편향은 낮게, 분산은 높게 하여 보다 정확한 예측을 하는 것입니다. 이를 위해 데이터 과학자는 종종 올가미 또는 능선과 같은 정규화 기법을 적용하여 과적합을 방지하는 동시에 편향을 낮게 유지합니다.
편향과 분산 개념을 이해하면 보다 효율적인 컴퓨터 프로그램을 설계하고 머신러닝 알고리즘의 결과를 정확하게 예측할 수 있습니다.