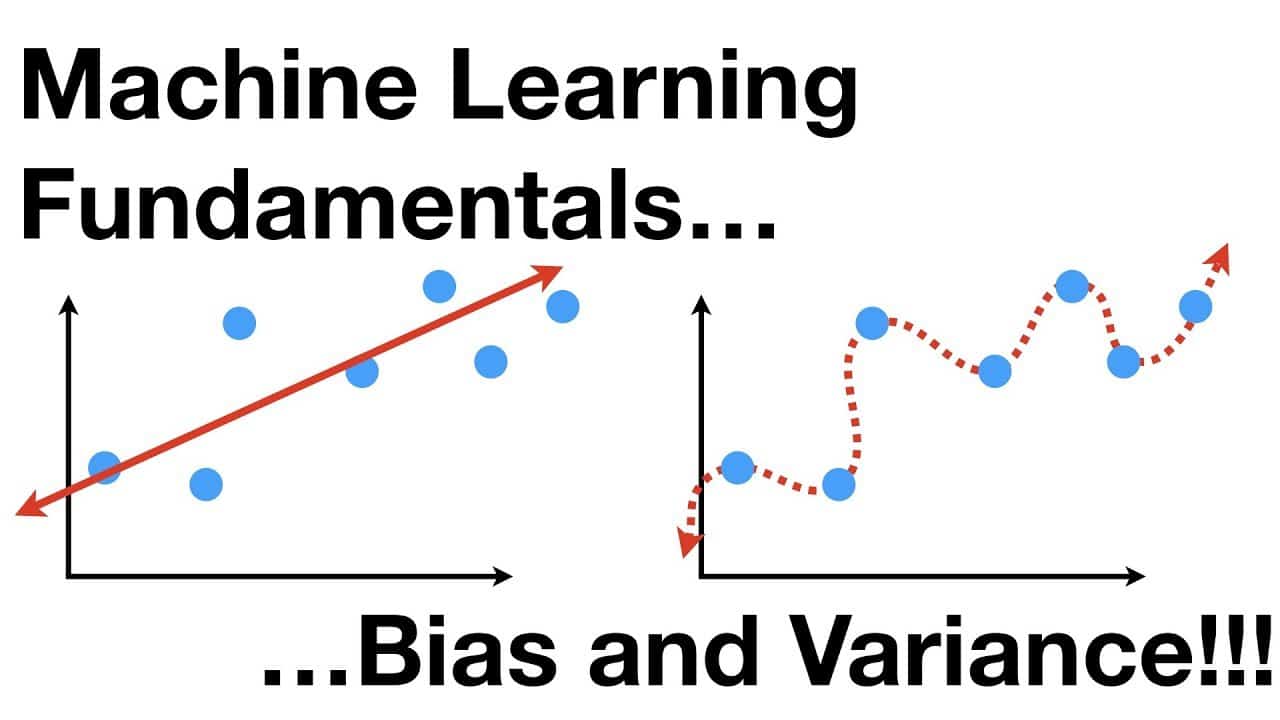
Bias and Variance is a Statistical concept used in computer programming, machinal learning, and related fields. The concept originates from the bias-variance tradeoff, where an algorithm can be tuned to minimize prediction error, the difference between the model’s prediction and the true value. Bias indicates the degree to which an algorithm favours a certain class or type of data. On the other hand, variance is a measure of how much the predictions of an algorithm can vary for different data sets. The bias-variance tradeoff concept is used to optimize the accuracy of prediction models.
A model that has high bias will not be very sensitive to new data. It is considered an underfitting problem as the algorithm does not take into account the complexity needed for better predictions. High bias leads to an algorithm which produces important errors from one data set to another, with no important performances. High variance can underestimate the amount of data needed and also overestimate the performance of a model. It is considered an overfitting problem, as the model tries to fit itself too closely to the data and fails to generalize as expected for a new data set.
In general, the goal is to optimize parameters to achieve an appropriate level of bias and variance — such that bias is low and variance is high for more accurate predictions. To do this, data scientists often apply regularization techniques, such as lasso or ridge, to prevent overfitting while simultaneously keeping bias low.
By understanding the concept of bias and variance, it is possible to design more efficient computer programs and accurately predict the outcome of machine learning algorithms.