
Google, as the world’s largest search engine, houses an immense treasure trove of valuable information. Yet, when the need arises to automatically and extensively scrape Google search results, you may face a few challenges. In this article, we will delve into the nature of these challenges, explore strategies to overcome them, and guide you in successfully extracting Google search results at scale.
In any conversation about scraping Google search results, you’re likely to encounter the acronym “SERP,” which stands for Search Engine Results Page. It’s the page that greets you after entering a query into the search bar. Gone are the days when Google merely presented a list of links; today’s SERPs are a dynamic blend of features and elements designed to enhance your search experience. With numerous components to navigate, let’s focus on the key ones.
1. Featured snippets
2. Ads
3. Video carousel
4. People also ask
5. Local pack
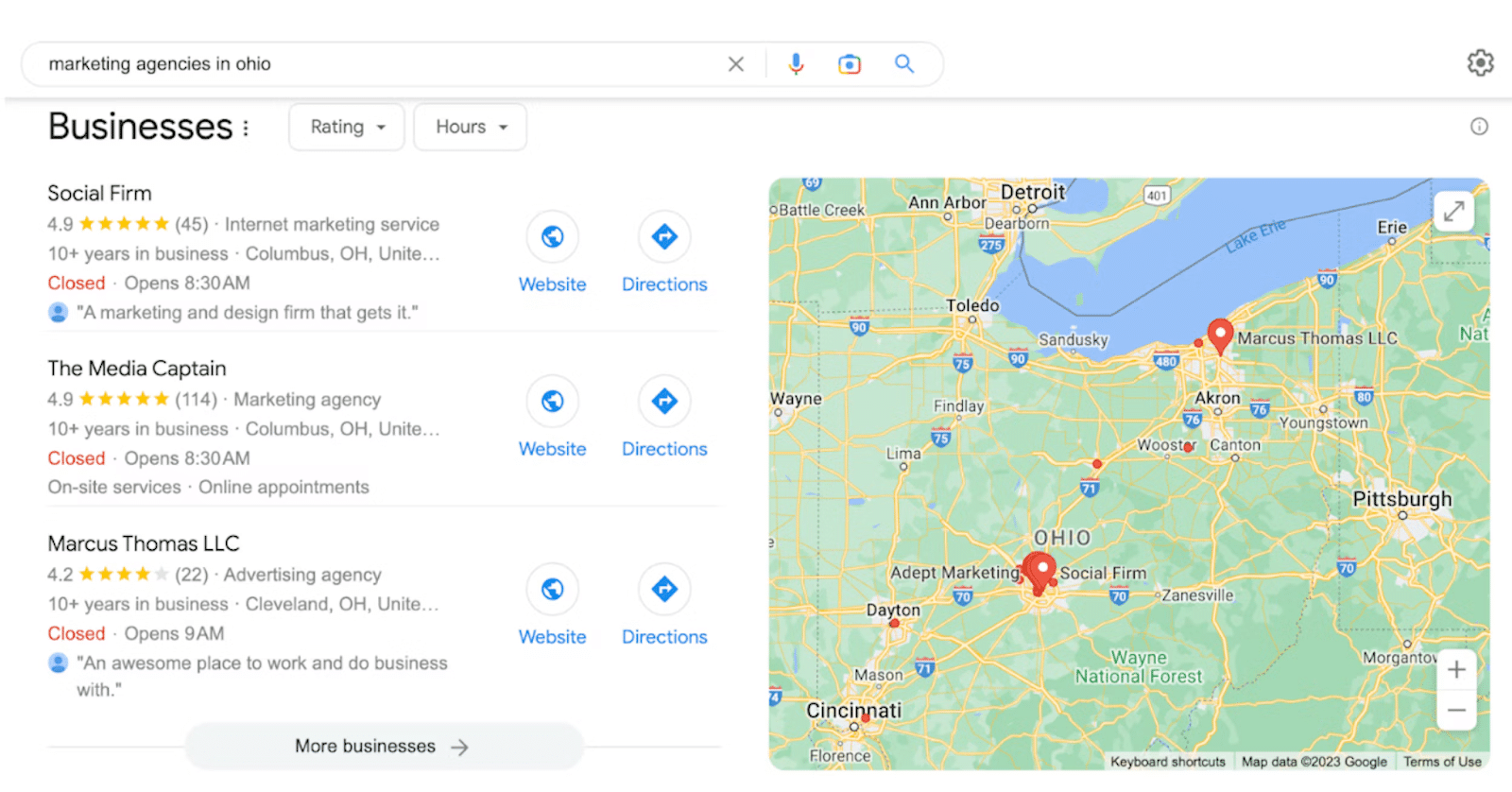
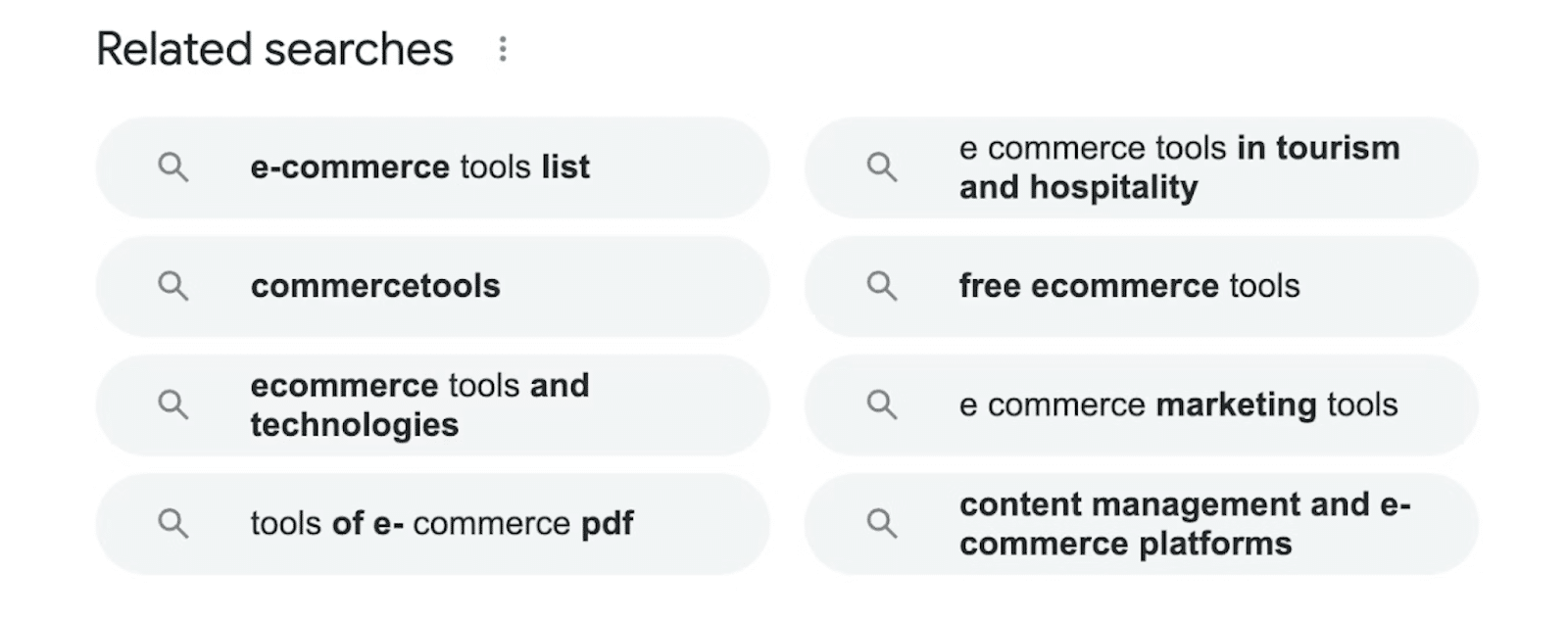
6. Related searches
The Legality of Scraping Google Results
The question of whether scraping Google search data is legal is a common topic in the web scraping domain. In essence, scraping publicly accessible data on the internet, including Google SERP data, is generally considered legal. However, the legality may vary depending on the specific circumstances, making it advisable to seek legal counsel tailored to your unique situation.
Challenges in Scraping Google Search Results
As mentioned earlier, scraping Google search results data presents formidable challenges. Google employs various mechanisms to deter malicious bots from harvesting its data, leading to a complex landscape for web scrapers. The primary issue arises from the difficulty in distinguishing between malicious bots and benign ones, often resulting in legitimate scrapers getting flagged or banned.
To gain a deeper understanding, let’s delve into the specific challenges encountered while scraping public Google search results:
- CAPTCHAs
Google deploys CAPTCHAs as a means of distinguishing between real users and automated bots. These tests are intentionally designed to be challenging for bots but relatively straightforward for humans to complete. If a visitor fails to solve a CAPTCHA after several attempts, it can trigger IP blocks. Fortunately, advanced web scraping tools like our SERP Scraper API are well-equipped to handle CAPTCHAs without encountering IP blocks.
- IP Blocks
Your IP address is exposed to websites you visit whenever you engage in online activities, including scraping Google SERP data or data from other websites. When web scraping, your script generates a substantial volume of requests. This heightened activity can trigger suspicions on the website’s end, potentially leading to an IP ban, which effectively restricts access to the site.
- Disorganized Data
The main objective of amassing data on a large scale from Google is to perform thorough analysis and gain valuable insights. This data often serves as the foundation for essential tasks like devising a robust search engine optimization (SEO) strategy. To facilitate effective analysis, the data retrieved should be well-structured and easily comprehensible. This necessitates the ability of your data-gathering tool to return information in an organized format, such as JSON or CSV.
In light of these challenges, an advanced web scraping solution is indispensable to overcome them effectively. Fineproxy Google Search API is expertly designed to navigate and bypass the technical hurdles implemented by Google. It provides seamless access to public Google search results, eliminating the need for scraper maintenance on the user’s end.
In fact, the process of scraping search results with our SERP API is both straightforward and efficient. Let’s explore this process in greater detail. If you have a specific interest in scraping Google Shopping results, we encourage you to refer to our other guide for insights and guidance.
Scraping public Google search results with Python using API
Web scraping is a valuable technique for collecting data from the internet, and Google search results are a prime source of information. However, scraping Google search results at scale can be a challenging endeavor due to the measures implemented by Google to deter automated bots. In this guide, we’ll explore how to scrape public Google search results using Python and an API, allowing you to overcome the complexities and limitations associated with traditional web scraping methods.
1. Set Up Your Environment:
Before you begin scraping Google search results, ensure you have the necessary tools and libraries installed. You’ll need Python installed on your system, as well as the requests and json libraries. Additionally, you’ll require an API key to access Google search results. To obtain an API key, follow Google’s guidelines for creating a project on the Google Developers Console.
import requests
import json
# Replace ‘YOUR_API_KEY’ with your actual API key
API_KEY = ‘YOUR_API_KEY’
# Define the endpoint URL
ENDPOINT_URL = ‘https://www.googleapis.com/customsearch/v1’
# Set up parameters
search_query = ‘Your search query here’
search_engine_id = ‘Your search engine ID here’
# Create the request URL
params = {
‘key’: API_KEY,
‘cx’: search_engine_id,
‘q’: search_query
}
2. Make API Requests:
With your environment set up, you can now make API requests to fetch Google search results. You need to send a GET request to Google’s Custom Search JSON API and process the response.
# Send a GET request to the API
response = requests.get(ENDPOINT_URL, params=params)
# Parse the response as JSON
data = response.json()
# Check if the request was successful
if ‘items’ in data:
search_results = data[‘items’]
# Process and use the search results as needed
for result in search_results:
title = result[‘title’]
link = result[‘link’]
snippet = result[‘snippet’]
# Perform your desired actions with the data
print(f’Title: {title}’)
print(f’Link: {link}’)
print(f’Snippet: {snippet}’)
else:
# Handle errors or no search results
print(‘No search results found or an error occurred.’)
3. Handle Rate Limits:
Google’s API has rate limits in place, which can affect the number of requests you can make within a specific time frame. Ensure that your scraping process adheres to these rate limits. Consider implementing a delay between requests to avoid hitting these limits and receiving HTTP 429 responses.
4. Data Processing and Storage:
After retrieving Google search results, you can process and store the data as needed for your specific use case. This might involve saving the results to a local file, a database, or performing real-time analysis.
5. Respect Google’s Terms of Service:
It’s essential to adhere to Google’s terms of service when scraping their search results. Ensure your use of the data is compliant with their policies and consider including proper attribution when displaying Google search results.
In summary, scraping public Google search results using Python and an API is a more efficient and reliable approach compared to traditional web scraping methods. With the right API key and code in place, you can gather valuable data from Google for various purposes, such as market research, SEO analysis, or content generation.
FAQ
Is Web Scraping Google Permissible?
When it comes to scraping Google, you might wonder about the legal aspects. Google search results, as a general rule, are considered publicly available data, making scraping them acceptable. However, there are restrictions, primarily concerning personal information and copyrighted content. To ensure compliance, it’s advisable to consult a legal professional beforehand.
Can You Scrape Google Events Data?
Certainly, you can scour Google for event-related information, such as concerts, festivals, exhibitions, and gatherings across the globe. By inputting event-specific keywords, you’ll encounter a supplementary table of events on the search engine results page, providing details like location, event titles, featured bands or artists, and dates. It is feasible to scrape this public data. Nevertheless, it is essential to emphasize that extracting data from Google must be done in compliance with all pertinent regulations. It’s prudent to seek legal counsel, especially when dealing with large-scale data collection.
Is Scraping Google Local Results Allowed?
Google employs a blend of relevance and proximity parameters to deliver optimal search results. For instance, when searching for local coffee places, Google presents options in close proximity and even offers directions. These specific search results are categorized as Google Local results and are distinct from Google Maps results, which focus on navigation. Provided you adhere to relevant regulations, you can indeed scrape public Google Local results for your project. Seeking advice from a legal expert is recommended to ensure proper compliance.
Can You Extract Information from the “About this Result” Sections?
Google offers additional insights about a website where a search result is located by clicking on the three dots adjacent to the right side of the search result. You can certainly scrape this publicly available data, but it is vital to strictly follow the applicable rules and regulations. Especially when considering extensive data extraction, consulting with a legal professional is a prudent course of action.
Scraping Google Video Results: Is It Permissible?
Scraping public Google Video results is generally considered legal. However, it is imperative to emphasize that strict adherence to the prevailing regulations and rules is essential. This practice can be beneficial for accumulating meta titles, video descriptions, URLs, and more in your specific use case. Nevertheless, before embarking on extensive data collection, consulting a legal expert is a sound choice.
Primary Methods for Scraping Google Search Pages
To harvest data from Google search pages, you have two primary methods at your disposal: URL-based extraction and search query-based extraction. The URL-based approach entails obtaining data from a Google Search results page using a copied URL, whether from a Google domain of any country (e.g., google.co.uk). You enjoy the flexibility to incorporate as many URLs as required to fulfill your objectives.







Comments (0)
There are no comments here yet, you can be the first!