
Google, como motor de búsqueda más grande del mundo, alberga un inmenso tesoro de información valiosa. Sin embargo, cuando surge la necesidad de extraer de forma automática y exhaustiva los resultados de búsqueda de Google, es posible que se enfrente a algunos desafíos. En este artículo, profundizaremos en la naturaleza de estos desafíos, exploraremos estrategias para superarlos y lo guiaremos para extraer con éxito resultados de búsqueda de Google a escala.
En cualquier conversación sobre la extracción de resultados de búsqueda de Google, es probable que encuentre el acrónimo "SERP", que significa página de resultados del motor de búsqueda. Es la página que te saluda después de ingresar una consulta en la barra de búsqueda. Atrás quedaron los días en que Google simplemente presentaba una lista de enlaces; Las SERP actuales son una combinación dinámica de características y elementos diseñados para mejorar su experiencia de búsqueda. Con numerosos componentes para navegar, centrémonos en los clave.
1. Fragmentos destacados
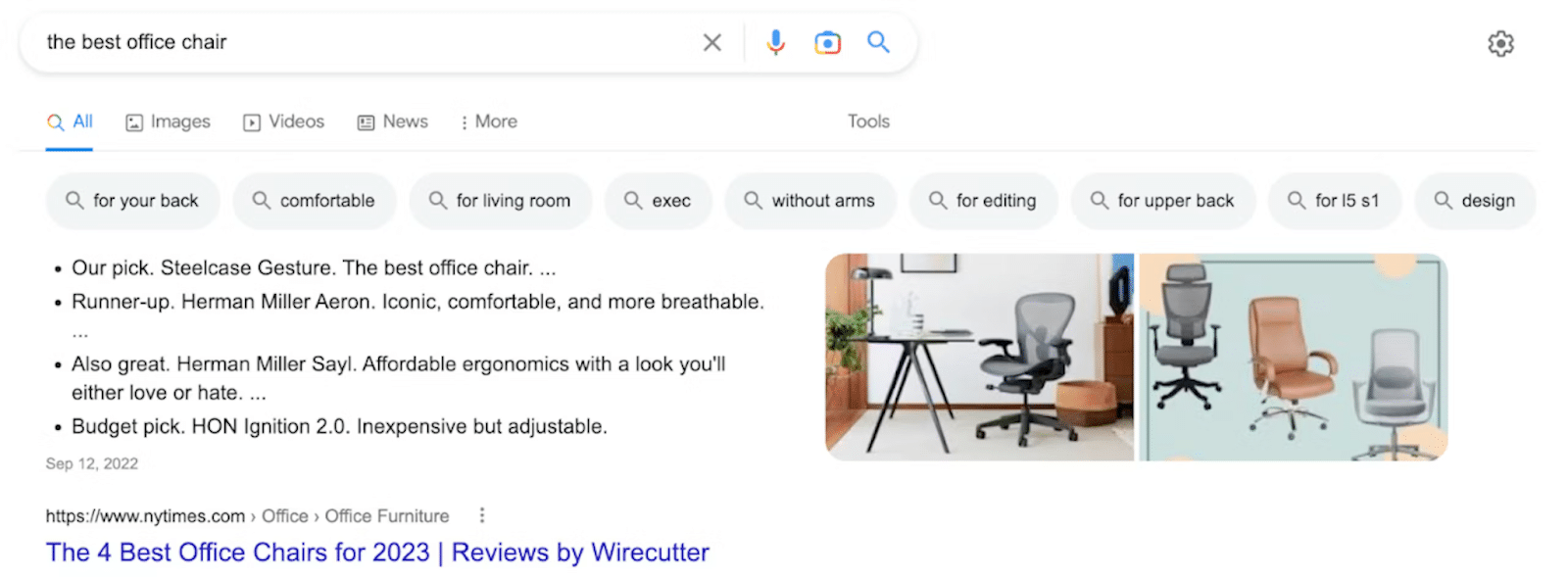
2. Anuncios
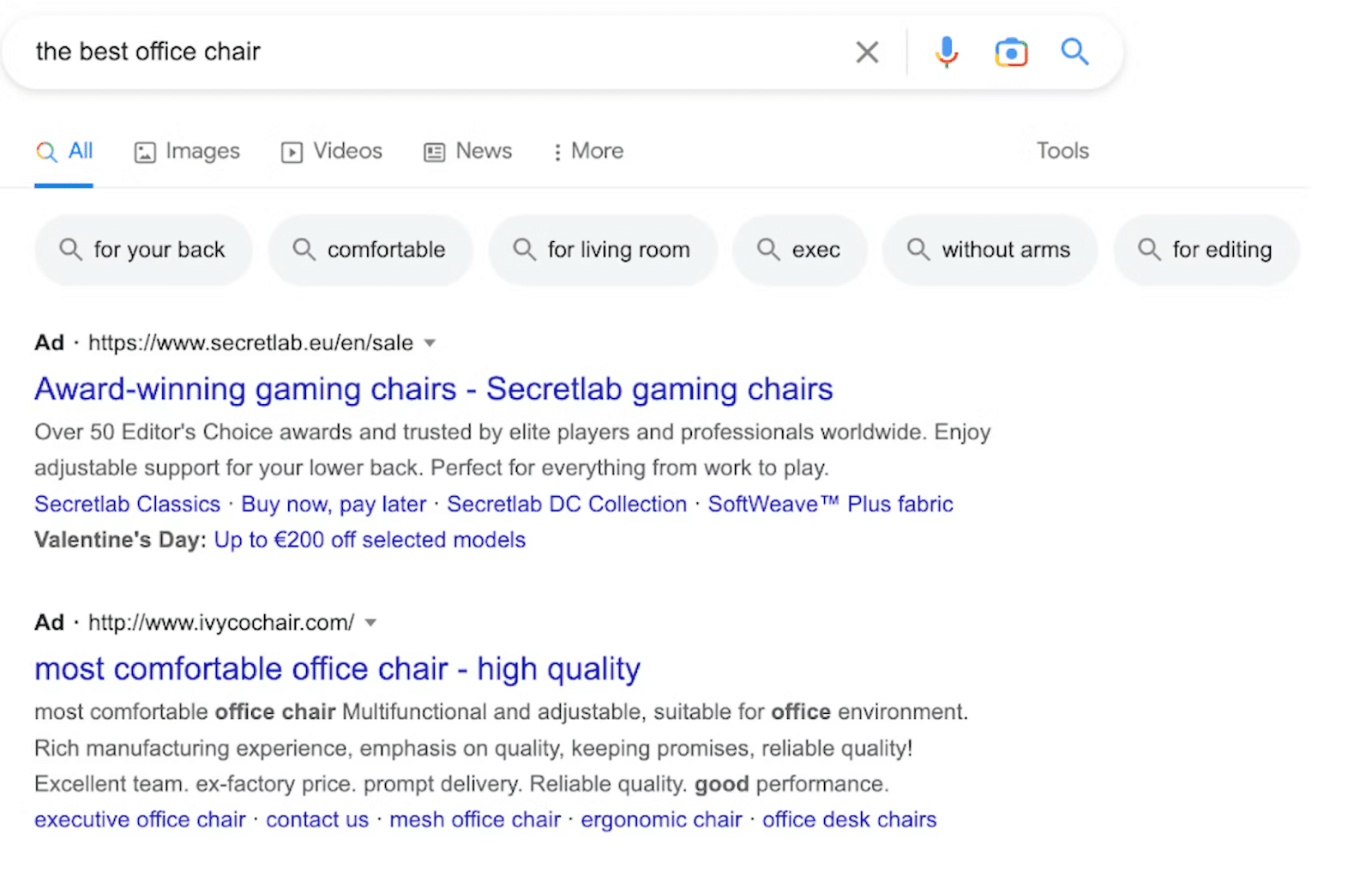
3. Carrusel de vídeos
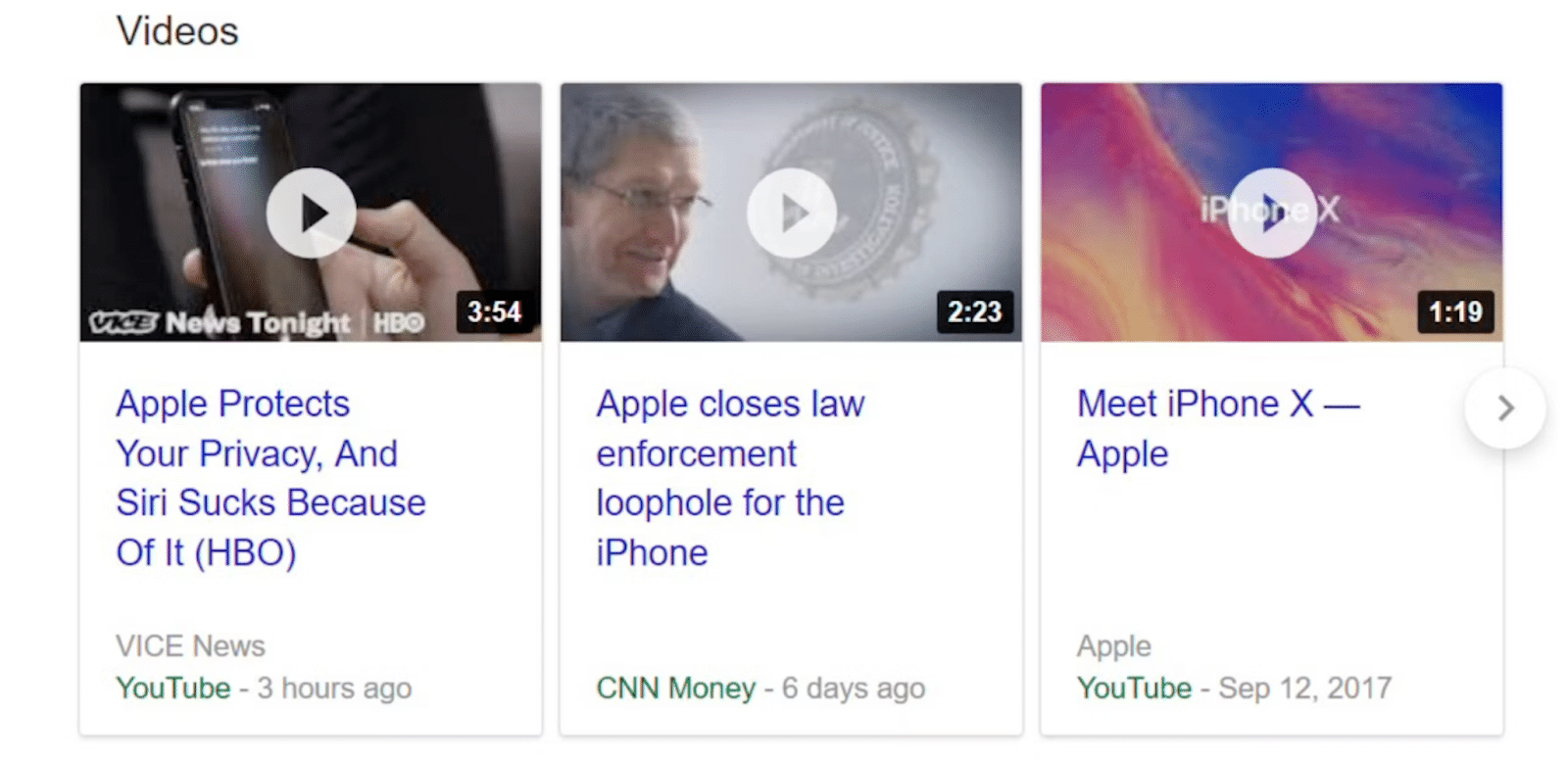
4. La gente también pregunta
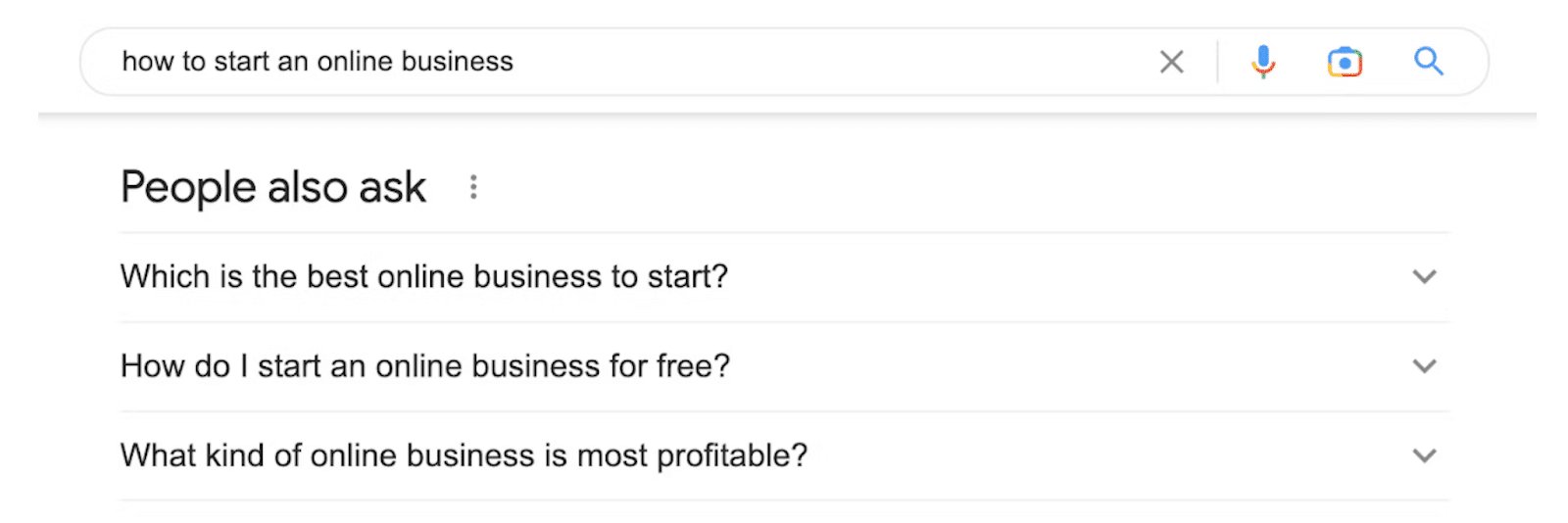
5. Paquete local
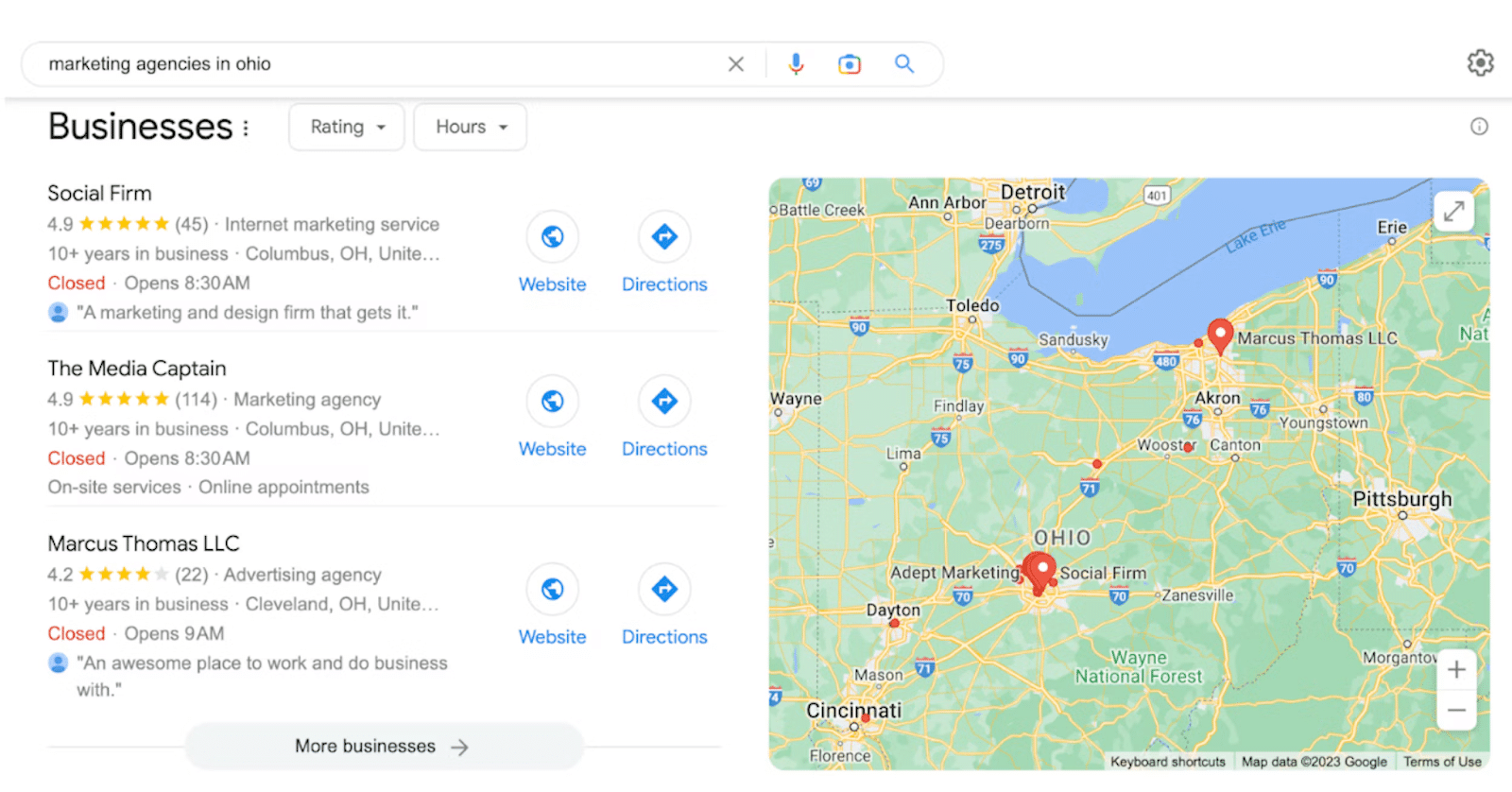
6. Búsquedas relacionadas
La legalidad de extraer resultados de Google
La cuestión de si el scraping de datos de búsqueda de Google es legal es un tema común en el dominio del web scraping. En esencia, la extracción de datos de acceso público en Internet, incluidos los datos SERP de Google, generalmente se considera legal. Sin embargo, la legalidad puede variar según las circunstancias específicas, por lo que es recomendable buscar asesoramiento legal adaptado a su situación particular.
Desafíos al extraer resultados de búsqueda de Google
Como se mencionó anteriormente, extraer datos de los resultados de búsqueda de Google presenta desafíos formidables. Google emplea varios mecanismos para disuadir a los robots maliciosos de recopilar sus datos, lo que genera un panorama complejo para los web scrapers. El problema principal surge de la dificultad para distinguir entre bots maliciosos y benignos, lo que a menudo resulta en que los scrapers legítimos sean marcados o prohibidos.
Para obtener una comprensión más profunda, profundicemos en los desafíos específicos que se encuentran al extraer resultados de búsqueda públicos de Google:
- CAPTCHA
Google implementa CAPTCHA como medio para distinguir entre usuarios reales y bots automatizados. Estas pruebas están diseñadas intencionalmente para ser desafiantes para los robots, pero relativamente sencillas de completar para los humanos. Si un visitante no logra resolver un CAPTCHA después de varios intentos, puede provocar bloqueos de IP. Afortunadamente, las herramientas avanzadas de web scraping como nuestra API SERP Scraper están bien equipadas para manejar CAPTCHA sin encontrar bloques de IP.
- Bloques de IP
Su dirección IP está expuesta a los sitios web que visita cada vez que realiza actividades en línea, incluida la extracción de datos SERP de Google o datos de otros sitios web. Al realizar web scraping, su secuencia de comandos genera un volumen sustancial de solicitudes. Esta intensa actividad puede generar sospechas por parte del sitio web, lo que podría llevar a una prohibición de IP, lo que efectivamente restringe el acceso al sitio.
- Datos desorganizados
El principal objetivo de recopilar datos a gran escala de Google es realizar análisis exhaustivos y obtener información valiosa. Estos datos a menudo sirven como base para tareas esenciales como diseñar una estrategia sólida de optimización de motores de búsqueda (SEO). Para facilitar un análisis eficaz, los datos recuperados deben estar bien estructurados y ser fácilmente comprensibles. Esto requiere la capacidad de su herramienta de recopilación de datos para devolver información en un formato organizado, como JSON o CSV.
A la luz de estos desafíos, una solución avanzada de web scraping es indispensable para superarlos de manera efectiva. La API de búsqueda de Google de Fineproxy está diseñada por expertos para navegar y sortear los obstáculos técnicos implementados por Google. Proporciona acceso fluido a los resultados públicos de búsqueda de Google, eliminando la necesidad de mantenimiento por parte del usuario.
De hecho, el proceso de extracción de resultados de búsqueda con nuestra API SERP es sencillo y eficiente. Exploremos este proceso con mayor detalle. Si tiene un interés específico en extraer resultados de Google Shopping, le recomendamos que consulte nuestra otra guía para obtener información y orientación.
Eliminación de resultados de búsqueda públicos de Google con Python usando API
El web scraping es una técnica valiosa para recopilar datos de Internet y los resultados de búsqueda de Google son una fuente principal de información. Sin embargo, extraer resultados de búsqueda de Google a escala puede ser una tarea desafiante debido a las medidas implementadas por Google para disuadir a los robots automatizados. En esta guía, exploraremos cómo extraer resultados de búsqueda públicos de Google utilizando Python y una API, lo que le permitirá superar las complejidades y limitaciones asociadas con los métodos tradicionales de extracción web.
1. Configure su entorno:
Antes de comenzar a extraer los resultados de búsqueda de Google, asegúrese de tener instaladas las herramientas y bibliotecas necesarias. Necesitará Python instalado en su sistema, así como las solicitudes y las bibliotecas json. Además, necesitará una clave API para acceder a los resultados de búsqueda de Google. Para obtener una clave API, siga las pautas de Google para crear un proyecto en Google Developers Console.
solicitudes de importación
importar json
# Reemplace 'YOUR_API_KEY' con su clave API real
API_KEY = 'TU_API_KEY'
# Definir la URL del punto final
ENDPOINT_URL = 'https://www.googleapis.com/customsearch/v1'
# Configurar parámetros
search_query = 'Su consulta de búsqueda aquí'
search_engine_id = 'Su ID de motor de búsqueda aquí'
# Crear la URL de solicitud
parámetros = {
'clave': API_KEY,
'cx': search_engine_id,
'q': consulta_búsqueda
}
2. Realice solicitudes de API:
Con su entorno configurado, ahora puede realizar solicitudes de API para obtener resultados de búsqueda de Google. Debe enviar una solicitud GET a la API JSON de búsqueda personalizada de Google y procesar la respuesta.
# Enviar una solicitud GET a la API
respuesta = solicitudes.get(ENDPOINT_URL, params=params)
# Analizar la respuesta como JSON
datos = respuesta.json()
# Comprobar si la solicitud fue exitosa
si hay 'elementos' en datos:
resultados_búsqueda = datos['elementos']
# Procesar y utilizar los resultados de la búsqueda según sea necesario
para obtener resultados en search_results:
título = resultado['título']
enlace = resultado['enlace']
fragmento = resultado['fragmento']
# Realice las acciones deseadas con los datos
imprimir(f'Título: {título}')
imprimir(f'Enlace: {enlace}')
imprimir(f'Fragmento: {fragmento}')
demás:
# Maneja errores o no hay resultados de búsqueda
print('No se encontraron resultados de búsqueda o se produjo un error.')
3. Manejar los límites de tarifas:
La API de Google tiene límites de velocidad, lo que puede afectar la cantidad de solicitudes que puede realizar dentro de un período de tiempo específico. Asegúrese de que su proceso de scraping cumpla con estos límites de velocidad. Considere implementar un retraso entre solicitudes para evitar alcanzar estos límites y recibir respuestas HTTP 429.
4. Procesamiento y Almacenamiento de Datos:
Después de recuperar los resultados de la búsqueda de Google, puede procesar y almacenar los datos según sea necesario para su caso de uso específico. Esto podría implicar guardar los resultados en un archivo local, una base de datos o realizar un análisis en tiempo real.
5. Respete los Términos de servicio de Google:
Es esencial cumplir con los términos de servicio de Google al extraer sus resultados de búsqueda. Asegúrese de que el uso de los datos cumpla con sus políticas y considere incluir la atribución adecuada al mostrar los resultados de búsqueda de Google.
En resumen, extraer resultados de búsqueda públicos de Google utilizando Python y una API es un enfoque más eficiente y confiable en comparación con los métodos tradicionales de extracción web. Con la clave API y el código correctos, puede recopilar datos valiosos de Google para diversos fines, como investigación de mercado, análisis SEO o generación de contenido.
PREGUNTAS FRECUENTES
¿Está permitido el web scraping de Google?
Cuando se trata de eliminar datos de Google, es posible que te preguntes acerca de los aspectos legales. Los resultados de búsqueda de Google, como regla general, se consideran datos disponibles públicamente, por lo que su extracción es aceptable. Sin embargo, existen restricciones, principalmente en lo que respecta a la información personal y al contenido protegido por derechos de autor. Para garantizar el cumplimiento, es recomendable consultar previamente a un profesional del derecho.
¿Se pueden extraer datos de eventos de Google?
Ciertamente, puedes buscar en Google información relacionada con eventos, como conciertos, festivales, exposiciones y reuniones en todo el mundo. Al ingresar palabras clave específicas del evento, encontrará una tabla complementaria de eventos en la página de resultados del motor de búsqueda, que proporciona detalles como ubicación, títulos de eventos, bandas o artistas destacados y fechas. Es factible eliminar estos datos públicos. Sin embargo, es fundamental destacar que la extracción de datos de Google debe realizarse cumpliendo con todas las normas pertinentes. Es prudente buscar asesoramiento legal, especialmente cuando se trata de recopilación de datos a gran escala.
¿Se permite extraer resultados locales de Google?
Google emplea una combinación de parámetros de relevancia y proximidad para ofrecer resultados de búsqueda óptimos. Por ejemplo, al buscar cafeterías locales, Google presenta opciones cercanas e incluso ofrece direcciones. Estos resultados de búsqueda específicos se clasifican como resultados de Google Local y son distintos de los resultados de Google Maps, que se centran en la navegación. Siempre que cumpla con las regulaciones pertinentes, puede eliminar los resultados públicos de Google Local para su proyecto. Se recomienda buscar asesoramiento de un experto legal para garantizar el cumplimiento adecuado.
¿Puede extraer información de las secciones "Acerca de este resultado"?
Google ofrece información adicional sobre un sitio web donde se encuentra un resultado de búsqueda haciendo clic en los tres puntos adyacentes al lado derecho del resultado de búsqueda. Ciertamente puedes eliminar estos datos disponibles públicamente, pero es vital seguir estrictamente las reglas y regulaciones aplicables. Especialmente cuando se considera una extracción extensa de datos, consultar con un profesional legal es un curso de acción prudente.
Extracción de resultados de vídeos de Google: ¿está permitido?
La extracción de resultados públicos de Google Video generalmente se considera legal. Sin embargo, es imperativo enfatizar que el estricto cumplimiento de las normas y reglamentos vigentes es esencial. Esta práctica puede ser beneficiosa para acumular metatítulos, descripciones de videos, URL y más en su caso de uso específico. Sin embargo, antes de embarcarse en una recopilación exhaustiva de datos, consultar a un experto jurídico es una buena opción.
Métodos principales para extraer páginas de búsqueda de Google
Para recopilar datos de las páginas de búsqueda de Google, tiene dos métodos principales a su disposición: extracción basada en URL y extracción basada en consultas de búsqueda. El enfoque basado en URL implica obtener datos de una página de resultados de la Búsqueda de Google utilizando una URL copiada, ya sea de un dominio de Google de cualquier país (por ejemplo, google.co.uk). Disfruta de la flexibilidad de incorporar tantas URL como sea necesario para cumplir sus objetivos.







Comentarios (0)
Aún no hay comentarios aquí, ¡tú puedes ser el primero!