
Google, en tant que plus grand moteur de recherche au monde, abrite un immense trésor d'informations précieuses. Pourtant, lorsque le besoin se fait sentir de supprimer automatiquement et de manière approfondie les résultats de recherche Google, vous pouvez être confronté à quelques défis. Dans cet article, nous examinerons la nature de ces défis, explorerons des stratégies pour les surmonter et vous guiderons pour réussir à extraire les résultats de recherche Google à grande échelle.
Dans toute conversation sur la récupération des résultats de recherche Google, vous rencontrerez probablement l'acronyme « SERP », qui signifie Search Engine Results Page. C'est la page qui vous accueille après avoir saisi une requête dans la barre de recherche. Il est révolu le temps où Google présentait simplement une liste de liens ; Les SERP d'aujourd'hui sont un mélange dynamique de fonctionnalités et d'éléments conçus pour améliorer votre expérience de recherche. Avec de nombreux composants à parcourir, concentrons-nous sur les principaux.
1. Extraits en vedette
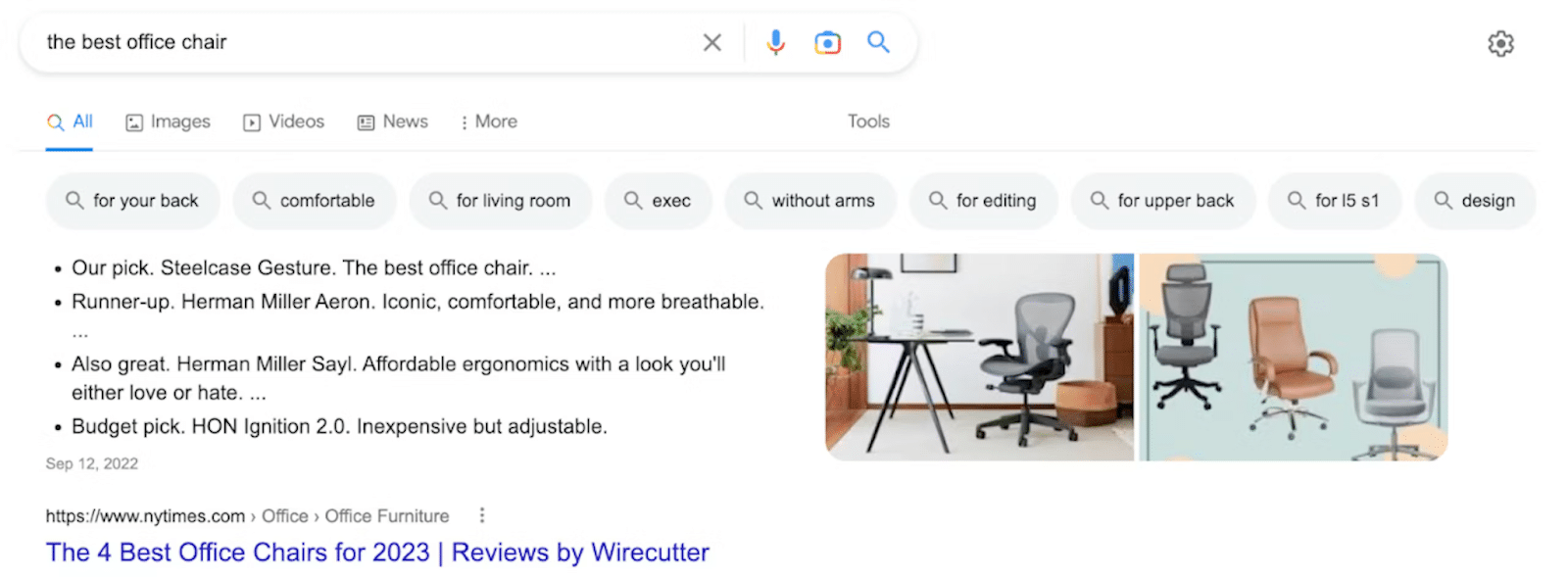
2. Annonces
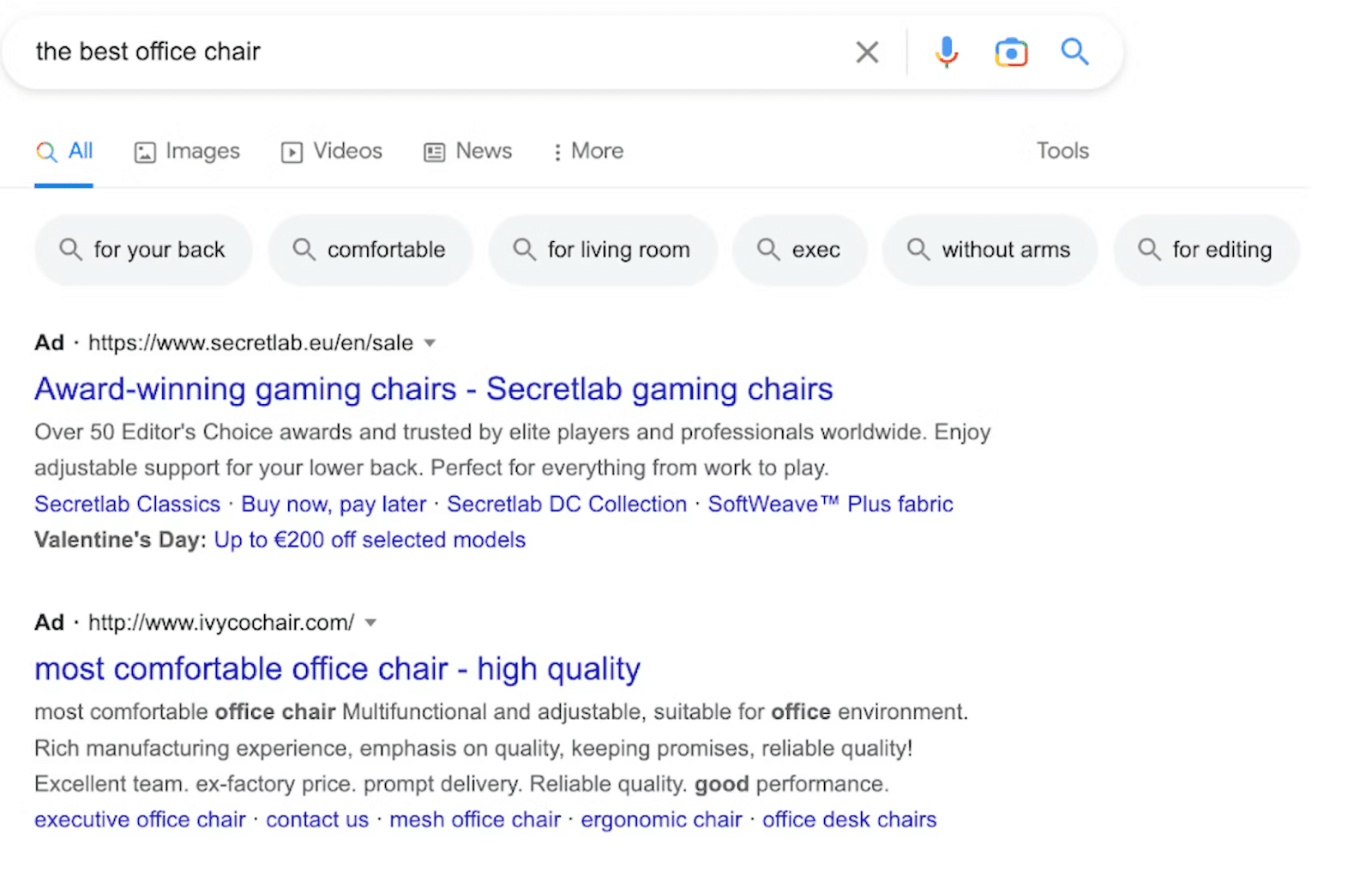
3. Carrousel vidéo
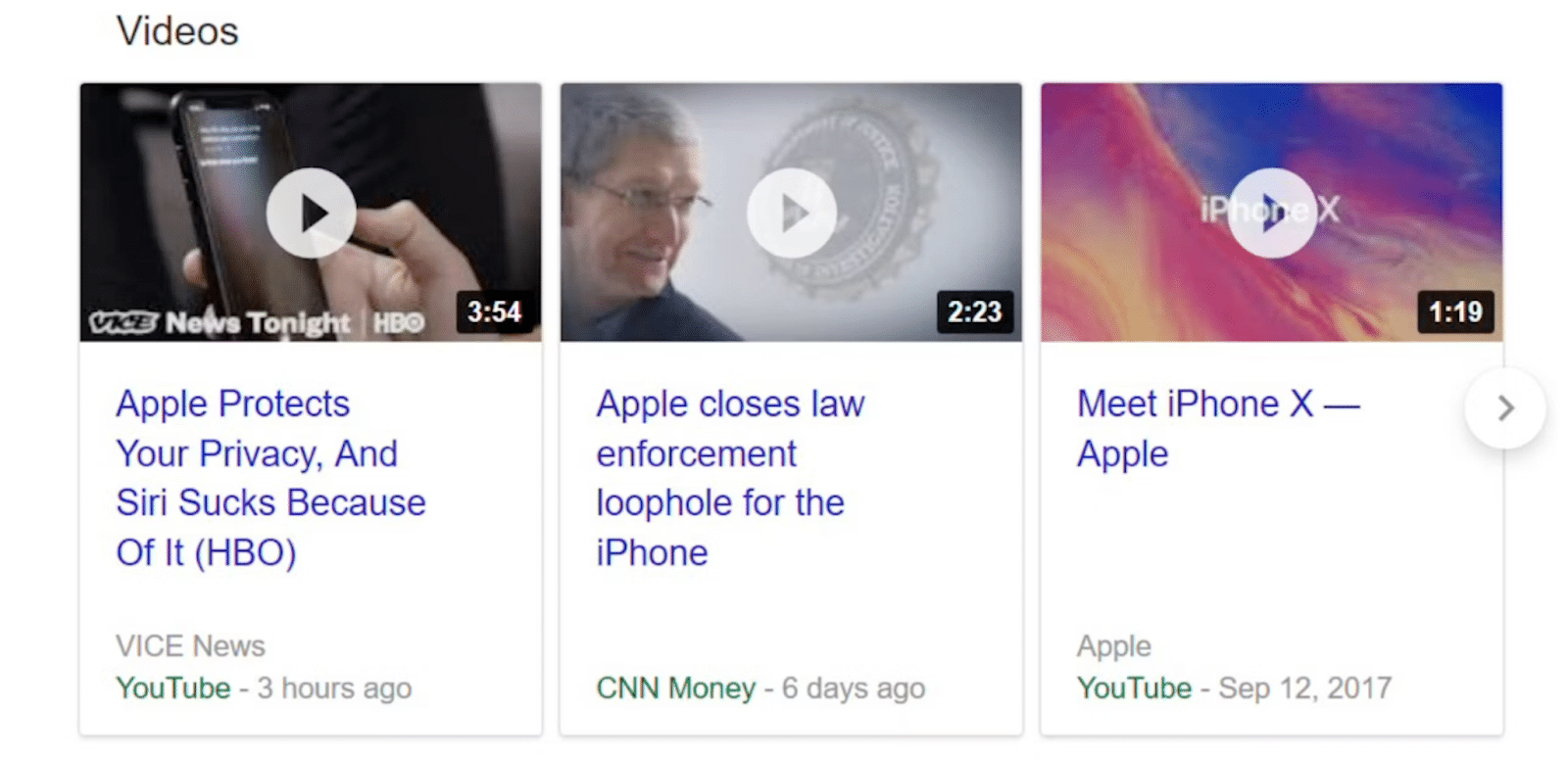
4. Les gens demandent aussi
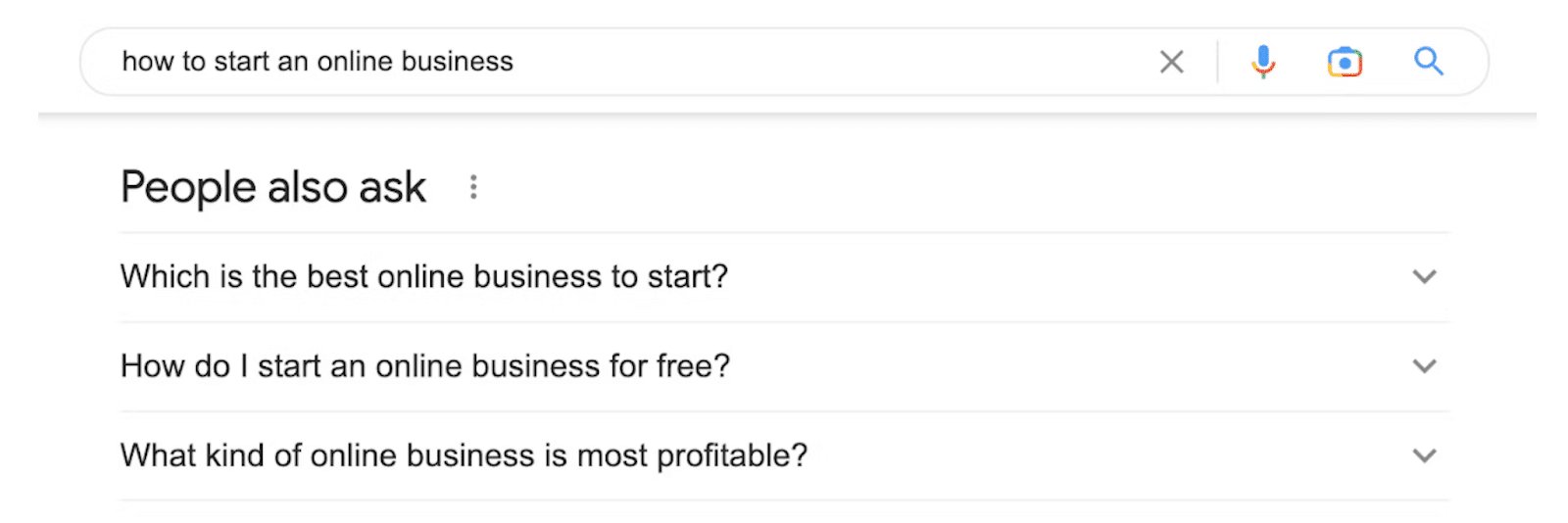
5. Pack local
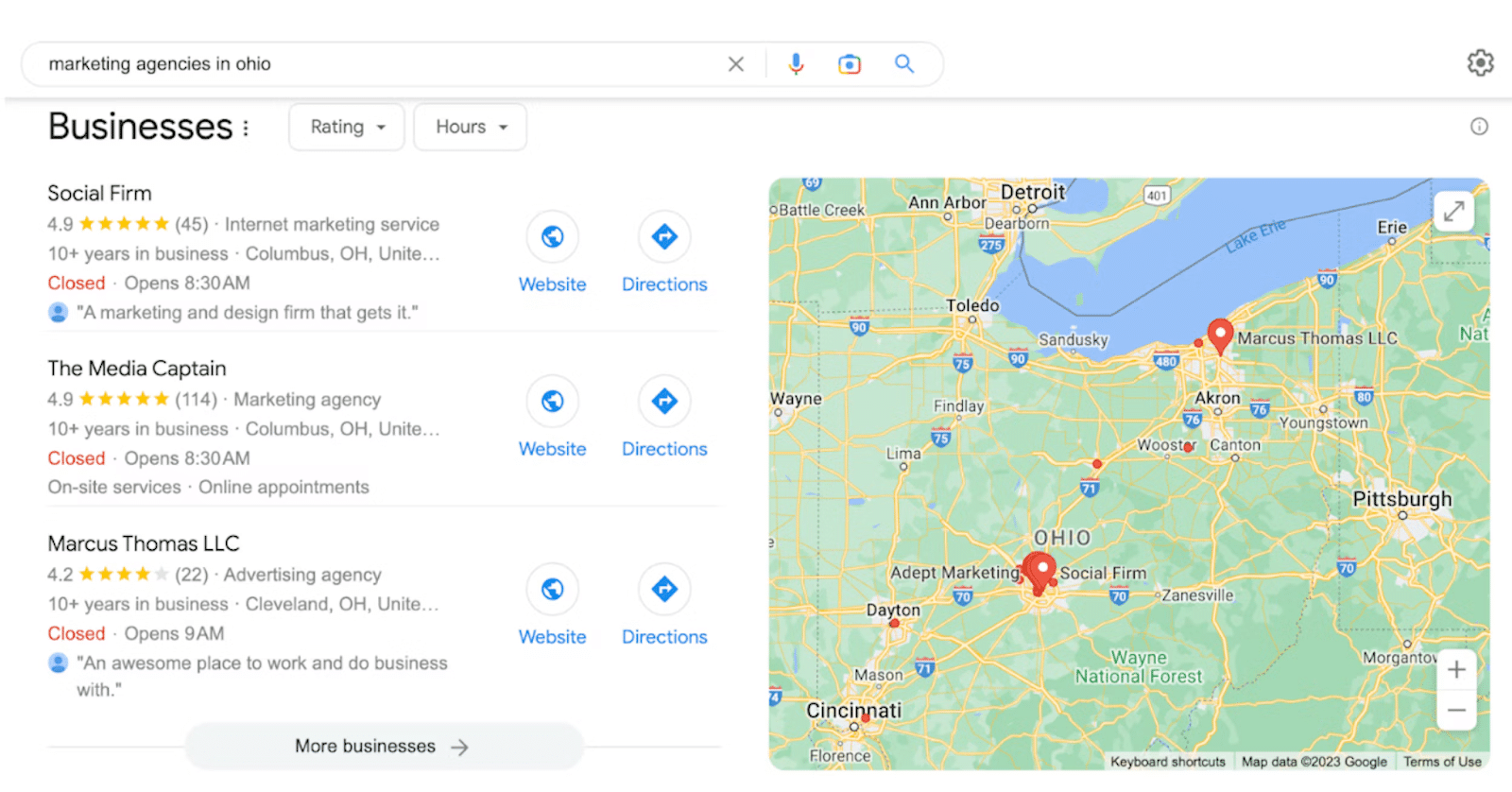
6. Recherches associées
La légalité de la suppression des résultats Google
La question de savoir si le scraping des données de recherche Google est légale est un sujet courant dans le domaine du web scraping. Essentiellement, la récupération de données accessibles au public sur Internet, y compris les données Google SERP, est généralement considérée comme légale. Cependant, la légalité peut varier en fonction des circonstances spécifiques, il est donc conseillé de rechercher un conseil juridique adapté à votre situation unique.
Défis liés à la récupération des résultats de recherche Google
Comme mentionné précédemment, l’extraction des données des résultats de recherche Google présente de formidables défis. Google utilise divers mécanismes pour dissuader les robots malveillants de récolter ses données, créant ainsi un paysage complexe pour les grattoirs Web. Le principal problème vient de la difficulté de faire la distinction entre les robots malveillants et les robots inoffensifs, ce qui entraîne souvent le signalement ou l'interdiction des scrapers légitimes.
Pour mieux comprendre, examinons les défis spécifiques rencontrés lors de la récupération des résultats de recherche publics Google :
- CAPTCHA
Google déploie des CAPTCHA comme moyen de distinguer les utilisateurs réels des robots automatisés. Ces tests sont intentionnellement conçus pour être difficiles pour les robots mais relativement simples à réaliser pour les humains. Si un visiteur ne parvient pas à résoudre un CAPTCHA après plusieurs tentatives, cela peut déclencher des blocages IP. Heureusement, les outils avancés de web scraping comme notre API SERP Scraper sont bien équipés pour gérer les CAPTCHA sans rencontrer de blocs IP.
- Blocs IP
Votre adresse IP est exposée aux sites Web que vous visitez chaque fois que vous vous engagez dans des activités en ligne, notamment en récupérant les données Google SERP ou les données d'autres sites Web. Lors du web scraping, votre script génère un volume important de requêtes. Cette activité accrue peut déclencher des soupçons du côté du site Web, conduisant potentiellement à une interdiction d'adresse IP, ce qui restreint effectivement l'accès au site.
- Données désorganisées
L’objectif principal de la collecte de données à grande échelle auprès de Google est d’effectuer une analyse approfondie et d’obtenir des informations précieuses. Ces données servent souvent de base à des tâches essentielles telles que la conception d’une solide stratégie d’optimisation des moteurs de recherche (SEO). Pour faciliter une analyse efficace, les données récupérées doivent être bien structurées et facilement compréhensibles. Cela nécessite la capacité de votre outil de collecte de données à renvoyer des informations dans un format organisé, tel que JSON ou CSV.
À la lumière de ces défis, une solution avancée de web scraping est indispensable pour les surmonter efficacement. L'API Fineproxy Google Search est conçue de manière experte pour naviguer et contourner les obstacles techniques mis en œuvre par Google. Il offre un accès transparent aux résultats de recherche publics de Google, éliminant ainsi le besoin de maintenance de grattoir de la part de l'utilisateur.
En fait, le processus de récupération des résultats de recherche avec notre API SERP est à la fois simple et efficace. Explorons ce processus plus en détail. Si vous souhaitez spécifiquement récupérer les résultats de Google Shopping, nous vous encourageons à vous référer à notre autre guide pour obtenir des informations et des conseils.
Récupérer les résultats de recherche publics Google avec Python à l'aide de l'API
Le web scraping est une technique précieuse pour collecter des données sur Internet, et les résultats de recherche Google sont une source d’informations primordiale. Cependant, extraire les résultats de recherche Google à grande échelle peut s'avérer une entreprise difficile en raison des mesures mises en œuvre par Google pour dissuader les robots automatisés. Dans ce guide, nous explorerons comment récupérer les résultats de recherche publics Google à l'aide de Python et d'une API, vous permettant ainsi de surmonter les complexités et les limites associées aux méthodes traditionnelles de scraping Web.
1. Configurez votre environnement :
Avant de commencer à extraire les résultats de recherche Google, assurez-vous que les outils et bibliothèques nécessaires sont installés. Vous aurez besoin de Python installé sur votre système, ainsi que des requêtes et des bibliothèques json. De plus, vous aurez besoin d'une clé API pour accéder aux résultats de recherche Google. Pour obtenir une clé API, suivez les instructions de Google pour créer un projet sur la Google Developers Console.
demandes d'importation
importer json
# Remplacez « VOTRE_API_KEY » par votre clé API actuelle
API_KEY = 'VOTRE_API_KEY'
# Définir l'URL du point de terminaison
ENDPOINT_URL = 'https://www.googleapis.com/customsearch/v1'
# Configurer les paramètres
search_query = 'Votre requête de recherche ici'
search_engine_id = 'Votre identifiant de moteur de recherche ici'
# Créer l'URL de la demande
paramètres = {
'clé' : API_KEY,
'cx' : search_engine_id,
'q' : requête_recherche
}
2. Effectuez des requêtes API :
Une fois votre environnement configuré, vous pouvez désormais effectuer des requêtes API pour récupérer les résultats de recherche Google. Vous devez envoyer une requête GET à l'API JSON de recherche personnalisée de Google et traiter la réponse.
# Envoyer une requête GET à l'API
réponse = requêtes.get(ENDPOINT_URL, params=params)
# Analyser la réponse au format JSON
données = réponse.json()
# Vérifiez si la demande a abouti
si « éléments » dans les données :
search_results = données['éléments']
# Traiter et utiliser les résultats de la recherche si nécessaire
pour le résultat dans search_results :
titre = résultat['titre']
lien = résultat['lien']
extrait = résultat['extrait']
# Effectuez les actions souhaitées avec les données
print(f'Titre : {titre}')
print(f'Lien : {lien}')
print(f'Extrait : {extrait}')
autre:
# Gérer les erreurs ou aucun résultat de recherche
print('Aucun résultat de recherche trouvé ou une erreur s'est produite.')
3. Gérer les limites de débit :
L'API de Google a mis en place des limites de débit, qui peuvent affecter le nombre de requêtes que vous pouvez effectuer dans un laps de temps spécifique. Assurez-vous que votre processus de scraping respecte ces limites de taux. Pensez à implémenter un délai entre les requêtes pour éviter d'atteindre ces limites et de recevoir des réponses HTTP 429.
4. Traitement et stockage des données :
Après avoir récupéré les résultats de recherche Google, vous pouvez traiter et stocker les données selon les besoins de votre cas d'utilisation spécifique. Cela peut impliquer de sauvegarder les résultats dans un fichier local, une base de données ou d'effectuer une analyse en temps réel.
5. Respectez les conditions d'utilisation de Google :
Il est essentiel de respecter les conditions d'utilisation de Google lors de la suppression de leurs résultats de recherche. Assurez-vous que votre utilisation des données est conforme à leurs politiques et envisagez d'inclure une attribution appropriée lors de l'affichage des résultats de recherche Google.
En résumé, l'extraction des résultats de recherche publics Google à l'aide de Python et d'une API est une approche plus efficace et plus fiable que les méthodes traditionnelles d'extraction de sites Web. Avec la bonne clé API et le bon code en place, vous pouvez collecter des données précieuses auprès de Google à diverses fins, telles que des études de marché, des analyses SEO ou la génération de contenu.
FAQ
Le Web Scraping de Google est-il autorisé ?
Lorsqu'il s'agit de scraper Google, vous vous interrogez peut-être sur les aspects juridiques. En règle générale, les résultats de recherche Google sont considérés comme des données accessibles au public, ce qui rend leur suppression acceptable. Cependant, il existe des restrictions, principalement concernant les informations personnelles et le contenu protégé par le droit d'auteur. Pour garantir le respect, il est conseillé de consulter au préalable un professionnel du droit.
Pouvez-vous récupérer les données d'événements Google ?
Certes, vous pouvez parcourir Google pour obtenir des informations relatives à des événements, tels que des concerts, des festivals, des expositions et des rassemblements à travers le monde. En saisissant des mots-clés spécifiques à un événement, vous rencontrerez un tableau supplémentaire d'événements sur la page de résultats du moteur de recherche, fournissant des détails tels que le lieu, les titres des événements, les groupes ou artistes en vedette et les dates. Il est possible de récupérer ces données publiques. Néanmoins, il est essentiel de souligner que l'extraction des données de Google doit être effectuée dans le respect de toutes les réglementations en vigueur. Il est prudent de faire appel à un conseiller juridique, surtout lorsqu'il s'agit d'une collecte de données à grande échelle.
La récupération des résultats locaux de Google est-elle autorisée ?
Google utilise un mélange de paramètres de pertinence et de proximité pour fournir des résultats de recherche optimaux. Par exemple, lors de la recherche de cafés locaux, Google présente des options à proximité et propose même des itinéraires. Ces résultats de recherche spécifiques sont classés dans la catégorie des résultats Google Local et sont distincts des résultats Google Maps, qui se concentrent sur la navigation. À condition que vous respectiez les réglementations en vigueur, vous pouvez effectivement récupérer les résultats publics Google Local pour votre projet. Il est recommandé de demander conseil à un expert juridique pour garantir une bonne conformité.
Pouvez-vous extraire des informations des sections « À propos de ce résultat » ?
Google offre des informations supplémentaires sur un site Web sur lequel se trouve un résultat de recherche en cliquant sur les trois points adjacents à droite du résultat de recherche. Vous pouvez certainement récupérer ces données accessibles au public, mais il est essentiel de suivre strictement les règles et réglementations applicables. Surtout lorsqu’on envisage une extraction de données approfondie, consulter un professionnel du droit est une ligne de conduite prudente.
Récupérer les résultats vidéo Google : est-ce autorisé ?
La suppression des résultats publics de Google Video est généralement considérée comme légale. Il est toutefois impératif de souligner que le strict respect des réglementations et règles en vigueur est essentiel. Cette pratique peut être bénéfique pour accumuler des méta-titres, des descriptions de vidéos, des URL et bien plus encore dans votre cas d'utilisation spécifique. Néanmoins, avant de se lancer dans une vaste collecte de données, consulter un expert juridique est un choix judicieux.
Principales méthodes pour supprimer les pages de recherche Google
Pour récolter des données à partir des pages de recherche Google, vous disposez de deux méthodes principales : l'extraction basée sur les URL et l'extraction basée sur les requêtes de recherche. L'approche basée sur l'URL consiste à obtenir des données à partir d'une page de résultats de recherche Google à l'aide d'une URL copiée, que ce soit à partir d'un domaine Google de n'importe quel pays (par exemple, google.co.uk). Vous bénéficiez de la flexibilité d’incorporer autant d’URL que nécessaire pour atteindre vos objectifs.







Commentaires (0)
Il n'y a pas encore de commentaires ici, vous pouvez être le premier !