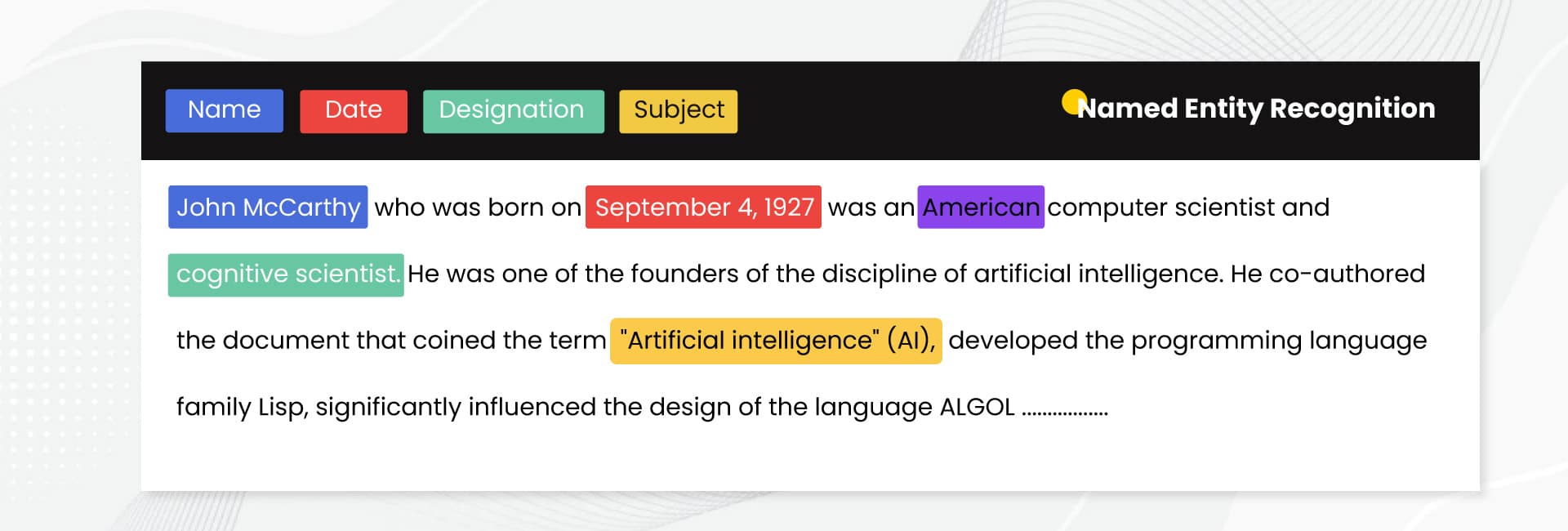
Rozpoznávání pojmenovaných entit (NER) je forma zpracování přirozeného jazyka (NLP), která se používá k identifikaci a klasifikaci pojmenovaných entit v textu, jako jsou lidé, místa, organizace a další. NER je nezbytnou součástí textové analýzy a pomáhá extrahovat a rozpoznávat entity z nestrukturovaného textu.
NER se používá k uspořádání velkého množství nestrukturovaných dat do strukturovanějších forem a ke zlepšení přesnosti vyhledávačů, systémů odpovědí na otázky a klasifikace textu pro aplikace, jako jsou souhrny dokumentů. To poskytuje datovým vědcům a vývojářům strojového učení výkonný nástroj pro rychlé a přesné zpracování a rozlišení mezi entitami, jako jsou organizace, místa, lidé, produkty a další.
NER lze použít k analýze zpětné vazby od zákazníků k identifikaci klíčových témat, extrahování dat z dokumentů a webových stránek pro použití v další analýze a k automatizaci úloh správy zákaznických zkušeností.
Vzhledem k tomu, že poptávka po lepším vyhledávání, odpovídání na otázky a schopnostech porozumění přirozenému jazyku roste, očekává se, že používání NLP ve formě NER bude stále více přijímáno v různých oblastech. NER může zlepšit přesnost a rychlost úkolů a vyřešit mnoho skutečných problémů v oblasti datové vědy a strojového učení.