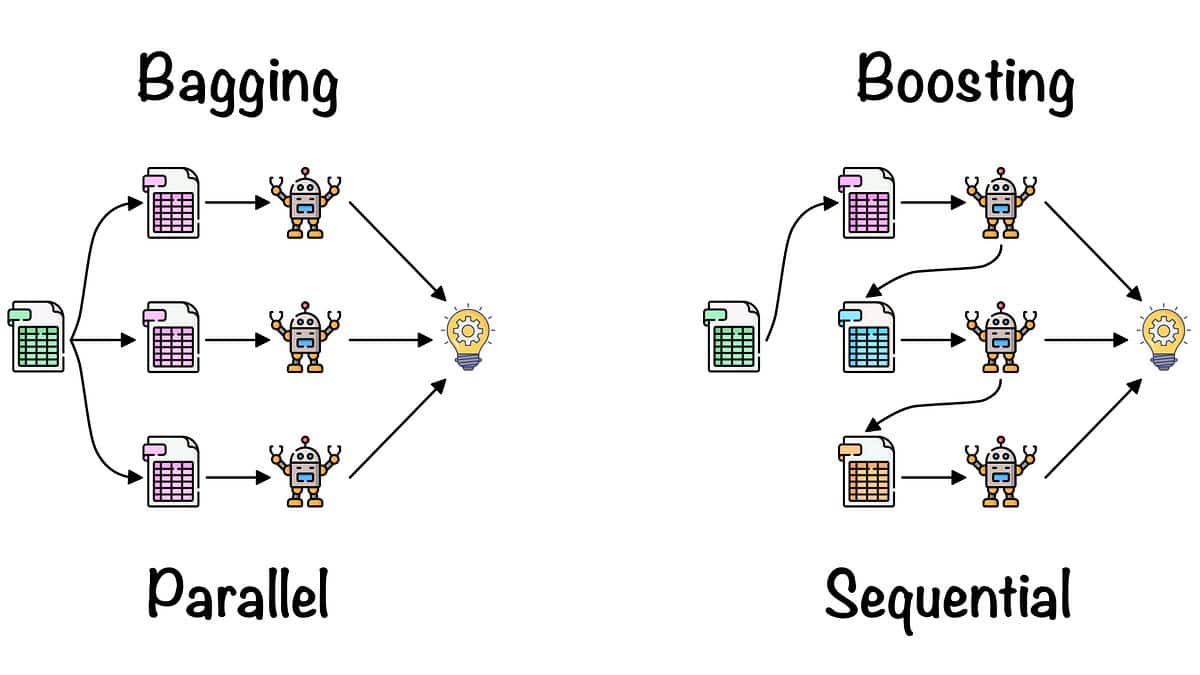
Bagging, também conhecido como Bootstrap Aggregating, é um algoritmo de conjunto de aprendizado de máquina usado para melhorar a precisão e a estabilidade dos algoritmos de aprendizado de máquina conhecidos como weak learners. Ele funciona treinando vários modelos em diferentes subconjuntos selecionados aleatoriamente dos dados de treinamento e, em seguida, combinando todos os modelos por meio de sua média (ou média ponderada). Isso melhora tanto a precisão quanto a generalização do modelo resultante, que geralmente é consideravelmente melhor do que os alunos fracos.
O Bagging foi desenvolvido por Tom Breiman em 1994 e é um tipo de aprendizado de conjunto, o que significa que ele combina vários alunos fracos para criar um modelo forte. Usamos esse método para reduzir a variação de um determinado modelo, sem aumentar significativamente sua tendência, ao contrário de métodos como o boosting.
O termo "ensacamento" vem da ideia de ensacar amostras do conjunto de dados de treinamento, já que diferentes modelos são treinados em diferentes amostras. Esse método é útil para diferentes problemas na área de aprendizado de máquina e tem sido aplicado a vários algoritmos, como Nave Bayes, Support Vector Machines, Decision Trees e Regression.
O funcionamento do bagging é simples. Você começa pegando um subconjunto dos dados de treinamento disponíveis. O tamanho do subconjunto pode ser geralmente do mesmo tamanho (ou menor) que o conjunto de treinamento original. Em seguida, você cria um modelo com base nesse subconjunto. Isso é chamado de "aprendiz fraco". Esse processo é repetido várias vezes com diferentes subconjuntos de dados. O resultado final é um conjunto de alunos fracos que chamamos de "modelo de ensacamento". Esse modelo é então testado em dados não vistos e produz maior precisão e estabilidade em comparação com um único modelo.
O ensacamento é um método simples, porém eficaz, para melhorar a precisão de alunos fracos. Ele é rápido, se adapta bem ao tamanho dos dados e é bastante fácil de implementar. É um dos métodos de conjunto mais usados no aprendizado de máquina e é usado em muitos algoritmos populares, como Random Forest, AdaBoost e Extra Trees.