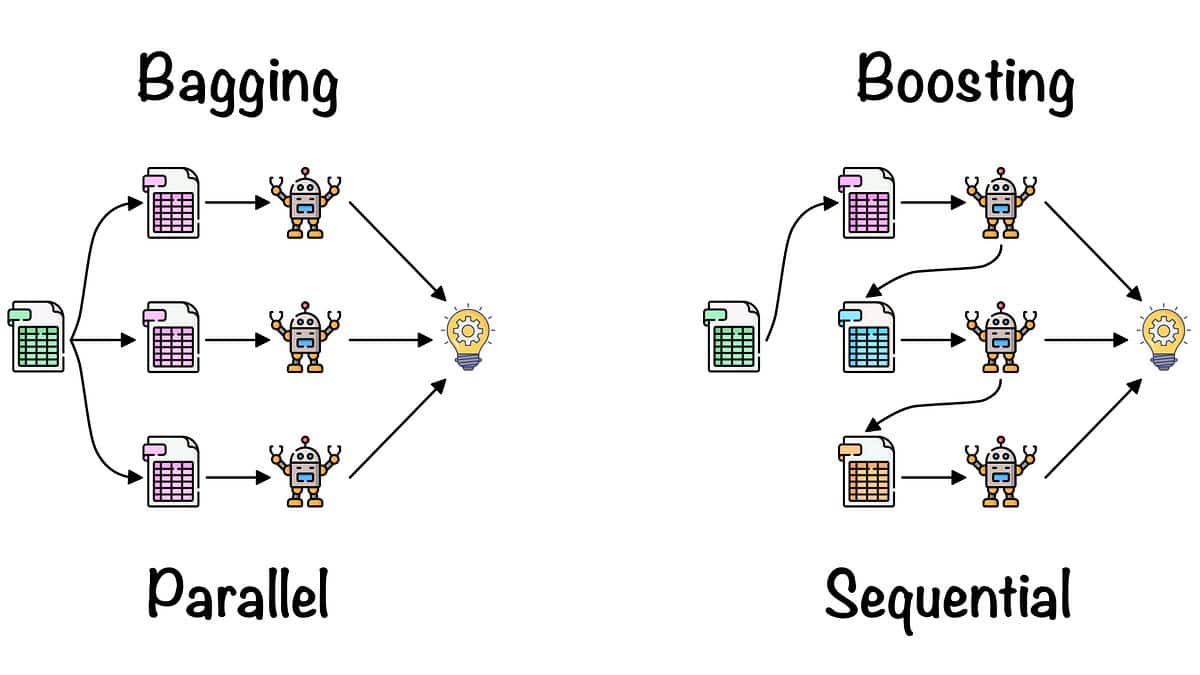
El ensamblaje, también conocido como agregación Bootstrap, es un algoritmo de aprendizaje automático utilizado para mejorar la precisión y la estabilidad de los algoritmos de aprendizaje automático conocidos como aprendices débiles. Funciona entrenando múltiples modelos en diferentes subconjuntos seleccionados aleatoriamente de los datos de entrenamiento y, a continuación, combinando todos los modelos tomando su media (o media ponderada). Esto mejora tanto la precisión como la generalización del modelo resultante, que suele ser considerablemente mejor que el de los aprendices débiles.
El bagging fue desarrollado por Tom Breiman en 1994 y es un tipo de aprendizaje por conjuntos, lo que significa que combina varios aprendices débiles para crear un modelo fuerte. Utilizamos este método para reducir la varianza de un modelo dado, sin aumentar significativamente su sesgo, a diferencia de métodos como el boosting.
El término "ensacado" procede de la idea de ensacar muestras del conjunto de datos de entrenamiento, ya que los distintos modelos se entrenan con muestras diferentes. Este método es útil para diferentes problemas en el ámbito del aprendizaje automático y se ha aplicado a varios algoritmos, como Nave Bayes, Support Vector Machines, Decision Trees y Regression.
El funcionamiento del ensacado es sencillo. Se empieza tomando un subconjunto de los datos de entrenamiento disponibles. El tamaño del subconjunto suele ser del mismo tamaño (o menor) que el del conjunto de entrenamiento original. A continuación, se crea un modelo basado en este subconjunto. Esto se denomina "aprendizaje débil". Este proceso se repite varias veces con distintos subconjuntos de datos. El resultado final es un conjunto de aprendices débiles que denominamos "modelo de ensacado". Este modelo se pone a prueba con datos no observados y mejora la precisión y la estabilidad en comparación con un modelo único.
El ensacado es un método sencillo pero eficaz para mejorar la precisión de los aprendices débiles. Es rápido, se adapta bien al tamaño de los datos y es bastante fácil de aplicar. Es uno de los métodos de ensamblaje más utilizados en el aprendizaje automático y se emplea en muchos algoritmos populares, como Random Forest, AdaBoost y Extra Trees.