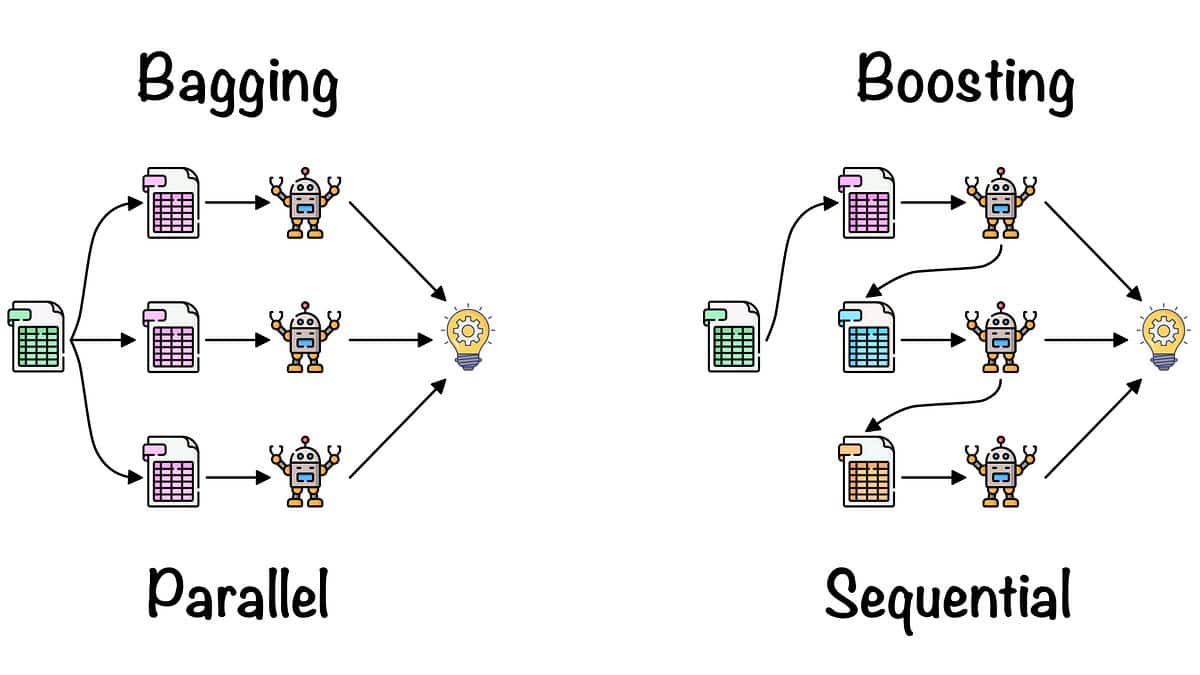
Le Bagging, également connu sous le nom de Bootstrap Aggregating, est un algorithme d'ensemble d'apprentissage automatique utilisé pour améliorer la précision et la stabilité des algorithmes d'apprentissage automatique connus sous le nom d'apprenants faibles. Il consiste à former plusieurs modèles sur différents sous-ensembles de données d'apprentissage sélectionnés au hasard, puis à combiner tous les modèles en prenant leur moyenne (ou moyenne pondérée). Cela permet d'améliorer à la fois la précision et la généralisation du modèle résultant, qui est généralement bien meilleur que les apprenants faibles.
Le Bagging a été développé par Tom Breiman en 1994 et est un type d'apprentissage d'ensemble, ce qui signifie qu'il combine plusieurs apprenants faibles pour créer un modèle fort. Nous utilisons cette méthode pour réduire la variance d'un modèle donné, sans augmenter de manière significative son biais, contrairement à des méthodes telles que le boosting.
Le terme "bagging" vient de l'idée de regrouper des échantillons de l'ensemble de données d'apprentissage, puisque différents modèles sont formés sur différents échantillons. Cette méthode est utile pour différents problèmes dans le domaine de l'apprentissage automatique et a été appliquée à divers algorithmes tels que Nave Bayes, les machines à vecteurs de support, les arbres de décision et la régression.
Le fonctionnement du bagging est simple. Vous commencez par prendre un sous-ensemble des données d'apprentissage disponibles. La taille du sous-ensemble peut généralement être de la même taille (ou plus petite) que l'ensemble d'apprentissage original. Vous créez ensuite un modèle basé sur ce sous-ensemble. C'est ce qu'on appelle un "apprenant faible". Ce processus est répété un certain nombre de fois avec différents sous-ensembles de données. Le résultat final est un ensemble d'apprenants faibles que nous appelons alors le "modèle de bagging". Ce modèle est ensuite testé sur des données inédites et produit une précision et une stabilité accrues par rapport à un modèle unique.
Le bagging est une méthode simple mais efficace pour améliorer la précision des apprenants faibles. Elle est rapide, s'adapte bien à la taille des données et est relativement facile à mettre en œuvre. C'est l'une des méthodes d'ensemble les plus utilisées dans l'apprentissage automatique, et elle est utilisée dans de nombreux algorithmes populaires tels que Random Forest, AdaBoost et Extra Trees.