
O Google, como maior mecanismo de busca do mundo, abriga um imenso tesouro de informações valiosas. No entanto, quando surgir a necessidade de raspar automática e extensivamente os resultados de pesquisa do Google, você poderá enfrentar alguns desafios. Neste artigo, iremos nos aprofundar na natureza desses desafios, explorar estratégias para superá-los e orientá-lo na extração bem-sucedida de resultados de pesquisa do Google em grande escala.
Em qualquer conversa sobre como extrair resultados de pesquisa do Google, você provavelmente encontrará a sigla “SERP”, que significa página de resultados do mecanismo de pesquisa. É a página que o cumprimenta após inserir uma consulta na barra de pesquisa. Já se foi o tempo em que o Google apenas apresentava uma lista de links; os SERPs de hoje são uma mistura dinâmica de recursos e elementos projetados para aprimorar sua experiência de pesquisa. Com vários componentes para navegar, vamos nos concentrar nos principais.
1. Trechos em destaque
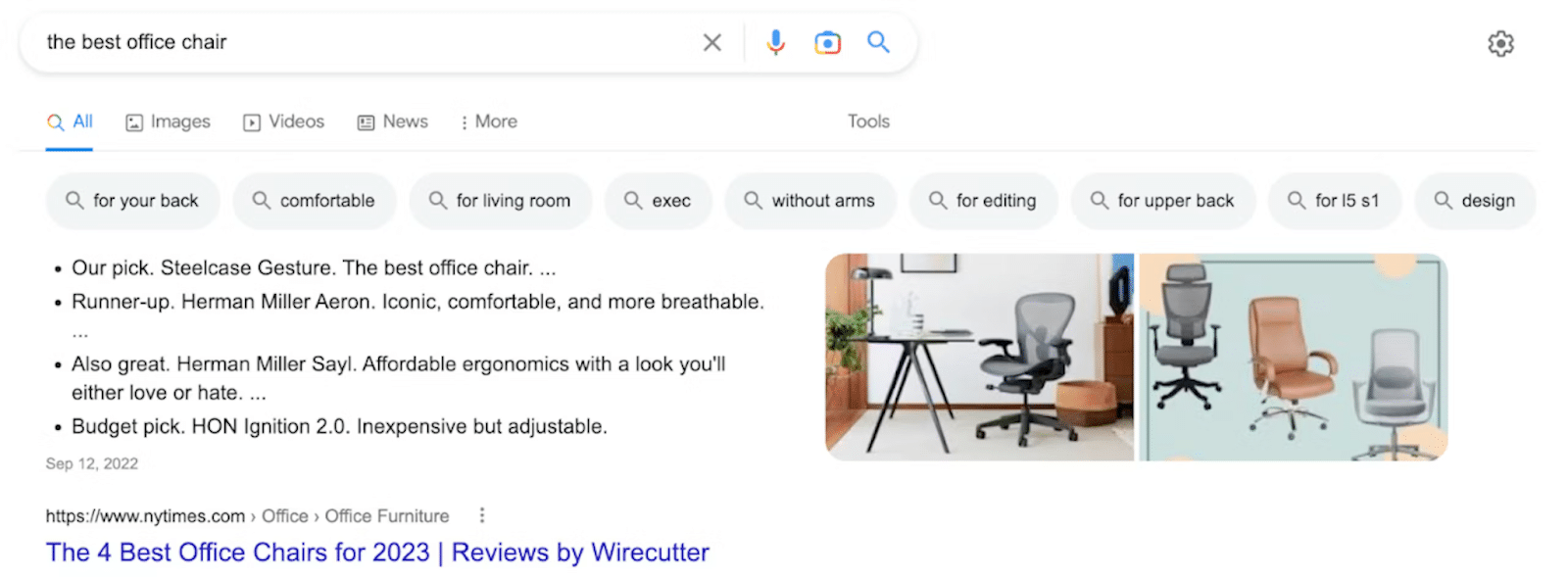
2. Anúncios
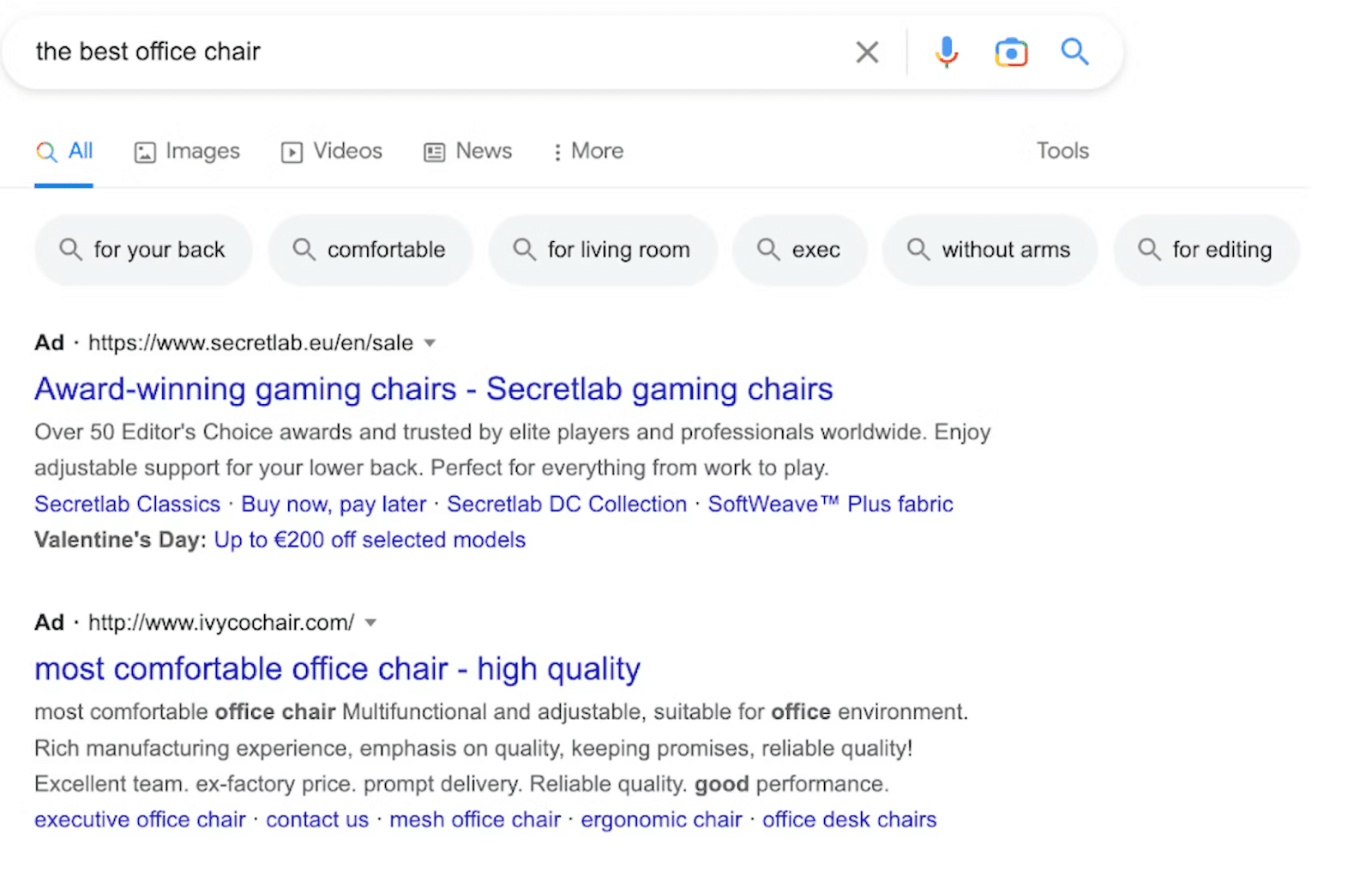
3. Carrossel de vídeos
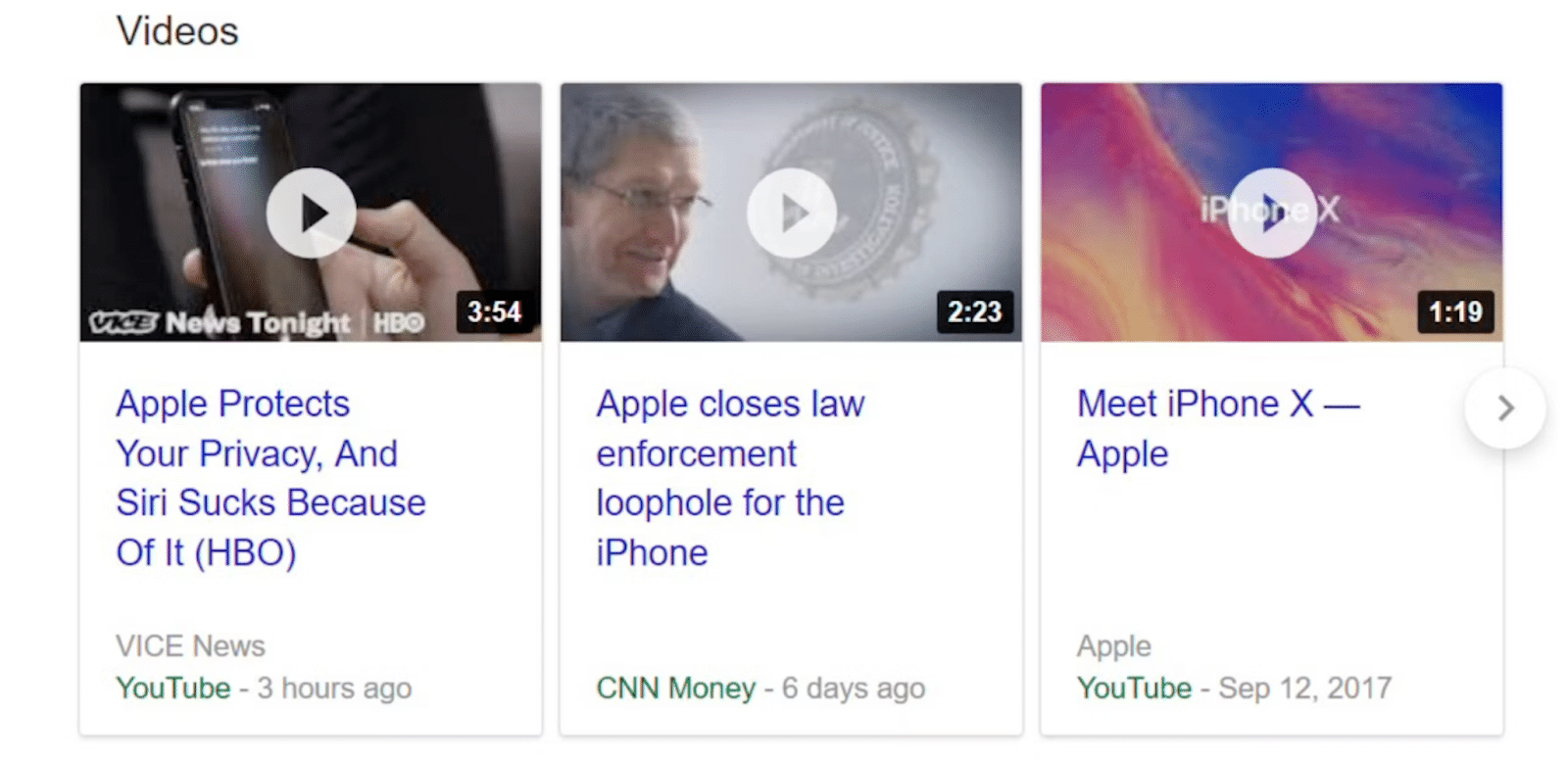
4. As pessoas também perguntam
5. Pacote local
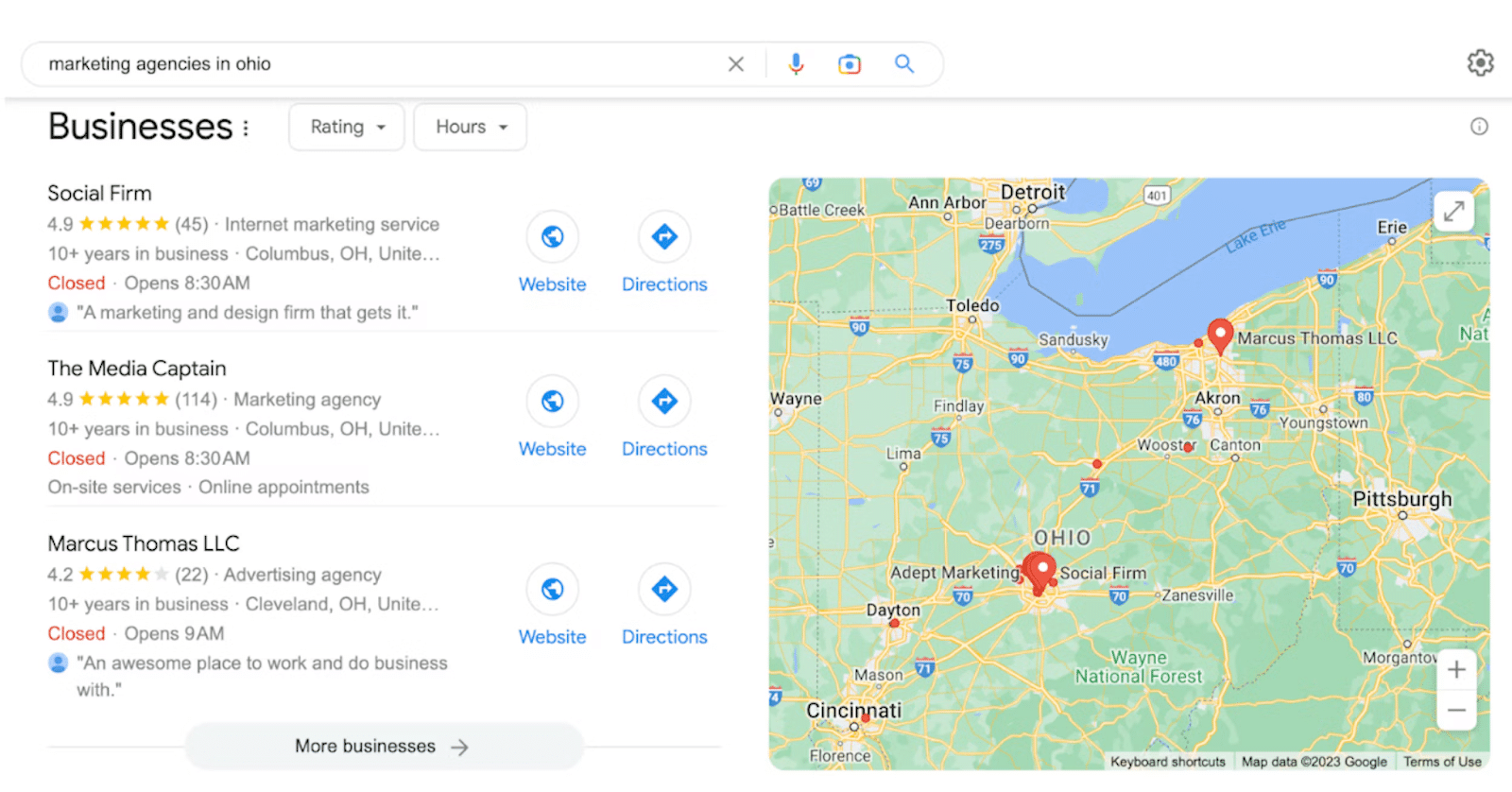
6. Pesquisas relacionadas
A legalidade de extrair resultados do Google
A questão de saber se a extração de dados de pesquisa do Google é legal é um tópico comum no domínio de web scraping. Em essência, a coleta de dados acessíveis ao público na Internet, incluindo dados SERP do Google, é geralmente considerada legal. No entanto, a legalidade pode variar dependendo das circunstâncias específicas, sendo aconselhável procurar aconselhamento jurídico adequado à sua situação específica.
Desafios na extração dos resultados de pesquisa do Google
Conforme mencionado anteriormente, extrair dados dos resultados de pesquisa do Google apresenta desafios formidáveis. O Google emprega vários mecanismos para impedir que bots maliciosos coletem seus dados, levando a um cenário complexo para web scrapers. O principal problema surge da dificuldade em distinguir entre bots maliciosos e bots benignos, muitas vezes resultando na sinalização ou banimento de scrapers legítimos.
Para obter uma compreensão mais profunda, vamos nos aprofundar nos desafios específicos encontrados ao extrair resultados de pesquisa públicos do Google:
- CAPTCHAs
O Google implanta CAPTCHAs como meio de distinguir entre usuários reais e bots automatizados. Esses testes são intencionalmente projetados para serem desafiadores para os bots, mas relativamente simples de serem concluídos pelos humanos. Se um visitante não conseguir resolver um CAPTCHA após várias tentativas, ele poderá acionar bloqueios de IP. Felizmente, ferramentas avançadas de web scraping, como nossa API SERP Scraper, estão bem equipadas para lidar com CAPTCHAs sem encontrar blocos de IP.
- Blocos de IP
Seu endereço IP é exposto aos sites que você visita sempre que participa de atividades on-line, incluindo a coleta de dados SERP do Google ou de outros sites. Ao fazer web scraping, seu script gera um volume substancial de solicitações. Essa atividade intensificada pode gerar suspeitas no site, levando potencialmente a um banimento de IP, o que efetivamente restringe o acesso ao site.
- Dados desorganizados
O principal objetivo de acumular dados em grande escala do Google é realizar análises completas e obter insights valiosos. Esses dados geralmente servem como base para tarefas essenciais, como a elaboração de uma estratégia robusta de otimização de mecanismos de pesquisa (SEO). Para facilitar uma análise eficaz, os dados recuperados devem ser bem estruturados e facilmente compreensíveis. Isso exige que sua ferramenta de coleta de dados seja capaz de retornar informações em um formato organizado, como JSON ou CSV.
À luz desses desafios, uma solução avançada de web scraping é indispensável para superá-los de forma eficaz. A API Fineproxy Google Search foi habilmente projetada para navegar e contornar os obstáculos técnicos implementados pelo Google. Ele fornece acesso contínuo aos resultados de pesquisa públicos do Google, eliminando a necessidade de manutenção do raspador por parte do usuário.
Na verdade, o processo de obtenção de resultados de pesquisa com nossa API SERP é simples e eficiente. Vamos explorar esse processo com mais detalhes. Se você tiver um interesse específico em obter resultados do Google Shopping, recomendamos que você consulte nosso outro guia para obter informações e orientações.
Extraindo resultados de pesquisa públicos do Google com Python usando API
Web scraping é uma técnica valiosa para coletar dados da Internet, e os resultados de pesquisa do Google são uma excelente fonte de informações. No entanto, extrair resultados de pesquisa do Google em grande escala pode ser uma tarefa desafiadora devido às medidas implementadas pelo Google para deter bots automatizados. Neste guia, exploraremos como extrair resultados de pesquisa públicos do Google usando Python e uma API, permitindo superar as complexidades e limitações associadas aos métodos tradicionais de web scraping.
1. Configure seu ambiente:
Antes de começar a extrair os resultados de pesquisa do Google, certifique-se de ter as ferramentas e bibliotecas necessárias instaladas. Você precisará do Python instalado em seu sistema, bem como das solicitações e das bibliotecas json. Além disso, você precisará de uma chave API para acessar os resultados de pesquisa do Google. Para obter uma chave de API, siga as diretrizes do Google para criar um projeto no Google Developers Console.
solicitações de importação
importar JSON
# Substitua 'YOUR_API_KEY' pela sua chave API real
API_KEY = 'SUA_API_KEY'
# Defina o URL do terminal
ENDPOINT_URL = 'https://www.googleapis.com/customsearch/v1'
Parâmetros de configuração #
search_query = 'Sua consulta de pesquisa aqui'
search_engine_id = 'Seu ID do mecanismo de pesquisa aqui'
# Crie o URL de solicitação
parâmetros = {
'chave': API_KEY,
'cx': search_engine_id,
'q': consulta_pesquisa
}
2. Faça solicitações de API:
Com seu ambiente configurado, agora você pode fazer solicitações de API para buscar resultados de pesquisa do Google. Você precisa enviar uma solicitação GET para a API JSON de pesquisa personalizada do Google e processar a resposta.
# Envie uma solicitação GET para a API
resposta = solicitações.get(ENDPOINT_URL, params=params)
# analisa a resposta como JSON
dados = resposta.json()
# Verifique se a solicitação foi bem-sucedida
se 'itens' nos dados:
resultados_de_pesquisa = dados['itens']
# Processe e use os resultados da pesquisa conforme necessário
para resultado em search_results:
título = resultado['título']
link = resultado['link']
trecho = resultado['trecho']
# Execute as ações desejadas com os dados
imprimir(f'Título: {título}')
imprimir(f'Link: {link}')
imprimir(f'Trecho: {snippet}')
outro:
# Lida com erros ou nenhum resultado de pesquisa
print('Nenhum resultado de pesquisa encontrado ou ocorreu um erro.')
3. Lidar com limites de taxa:
A API do Google possui limites de taxa, o que pode afetar o número de solicitações que você pode fazer em um período específico. Certifique-se de que seu processo de scraping atenda a esses limites de taxa. Considere implementar um atraso entre as solicitações para evitar atingir esses limites e receber respostas HTTP 429.
4. Processamento e armazenamento de dados:
Depois de recuperar os resultados de pesquisa do Google, você pode processar e armazenar os dados conforme necessário para seu caso de uso específico. Isso pode envolver salvar os resultados em um arquivo local, um banco de dados ou realizar análises em tempo real.
5. Respeite os Termos de Serviço do Google:
É essencial aderir aos termos de serviço do Google ao extrair os resultados da pesquisa. Certifique-se de que o uso dos dados esteja em conformidade com as políticas e considere incluir a atribuição adequada ao exibir os resultados de pesquisa do Google.
Em resumo, extrair resultados de pesquisa públicos do Google usando Python e uma API é uma abordagem mais eficiente e confiável em comparação com os métodos tradicionais de web scraping. Com a chave de API e o código corretos, você pode coletar dados valiosos do Google para diversos fins, como pesquisa de mercado, análise de SEO ou geração de conteúdo.
PERGUNTAS FREQUENTES
O Web Scraping do Google é permitido?
Quando se trata de raspar o Google, você pode se perguntar sobre os aspectos legais. Os resultados de pesquisa do Google, como regra geral, são considerados dados disponíveis publicamente, tornando aceitável a sua extração. No entanto, existem restrições, principalmente no que diz respeito a informações pessoais e conteúdo protegido por direitos autorais. Para garantir a conformidade, é aconselhável consultar previamente um profissional jurídico.
Você pode extrair dados de eventos do Google?
Certamente, você pode pesquisar no Google informações relacionadas a eventos, como concertos, festivais, exposições e encontros em todo o mundo. Ao inserir palavras-chave específicas do evento, você encontrará uma tabela suplementar de eventos na página de resultados do mecanismo de pesquisa, fornecendo detalhes como localização, títulos dos eventos, bandas ou artistas em destaque e datas. É viável extrair esses dados públicos. No entanto, é fundamental ressaltar que a extração de dados do Google deve ser feita obedecendo a todas as regulamentações pertinentes. É prudente procurar aconselhamento jurídico, especialmente quando se trata de recolha de dados em grande escala.
A extração de resultados locais do Google é permitida?
O Google emprega uma combinação de parâmetros de relevância e proximidade para fornecer resultados de pesquisa ideais. Por exemplo, ao pesquisar cafeterias locais, o Google apresenta opções próximas e até oferece direções. Esses resultados de pesquisa específicos são categorizados como resultados locais do Google e são distintos dos resultados do Google Maps, que se concentram na navegação. Desde que você cumpra os regulamentos relevantes, você pode realmente obter resultados públicos do Google Local para o seu projeto. Recomenda-se buscar aconselhamento de um especialista jurídico para garantir o cumprimento adequado.
Você pode extrair informações das seções “Sobre este resultado”?
O Google oferece informações adicionais sobre um site onde um resultado de pesquisa está localizado clicando nos três pontos adjacentes ao lado direito do resultado da pesquisa. Você certamente pode extrair esses dados disponíveis publicamente, mas é vital seguir rigorosamente as regras e regulamentos aplicáveis. Especialmente quando se considera a extração extensiva de dados, consultar um profissional jurídico é uma ação prudente.
Extrair resultados de vídeos do Google: é permitido?
A coleta de resultados públicos do Google Video geralmente é considerada legal. No entanto, é imperativo enfatizar que a adesão estrita aos regulamentos e regras vigentes é essencial. Essa prática pode ser benéfica para acumular metatítulos, descrições de vídeos, URLs e muito mais em seu caso de uso específico. No entanto, antes de iniciar uma extensa recolha de dados, consultar um perito jurídico é uma boa escolha.
Métodos primários para raspar páginas de pesquisa do Google
Para coletar dados das páginas de pesquisa do Google, você tem dois métodos principais à sua disposição: extração baseada em URL e extração baseada em consulta de pesquisa. A abordagem baseada em URL envolve a obtenção de dados de uma página de resultados de pesquisa do Google usando um URL copiado, seja de um domínio do Google de qualquer país (por exemplo, google.co.uk). Você aproveita a flexibilidade para incorporar quantos URLs forem necessários para cumprir seus objetivos.







Comentários (0)
Ainda não há comentários aqui, você pode ser o primeiro!