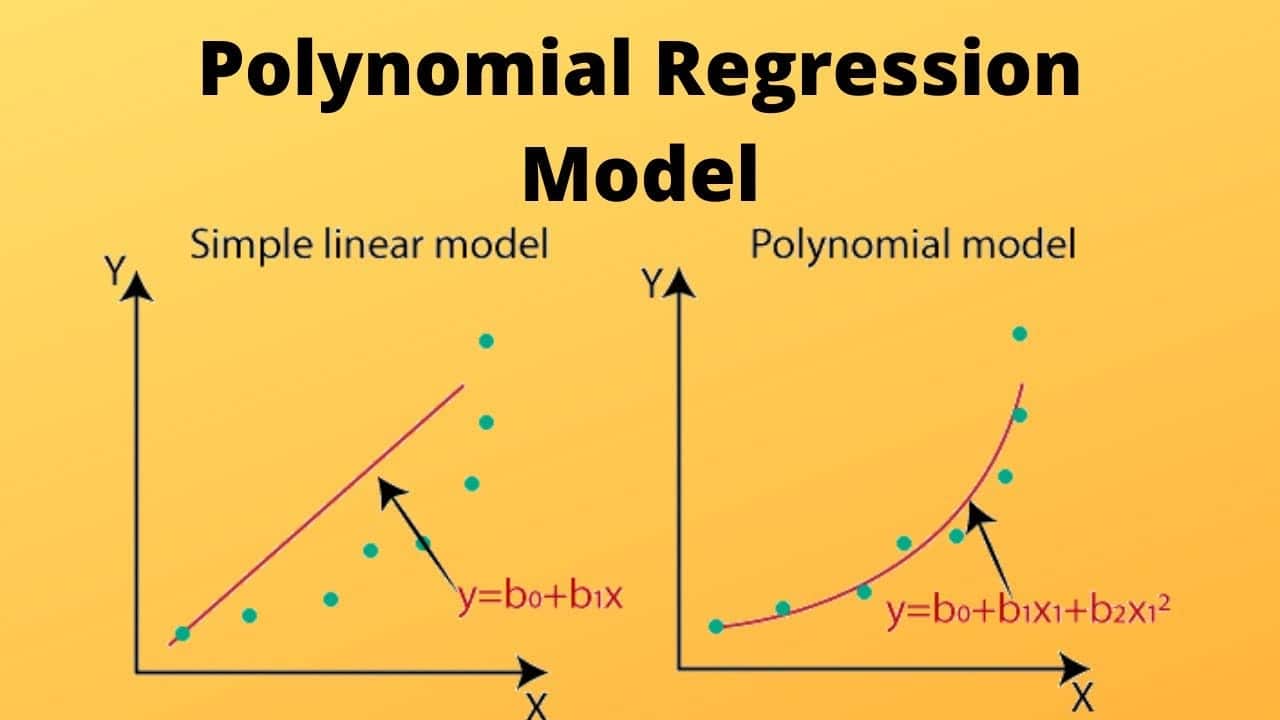
Regresja wielomianowa, znana również jako regresja nieliniowa, to zaawansowana technika uczenia maszynowego wykorzystywana do przewidywania ciągłych danych wyjściowych na podstawie danych wejściowych. Jest to rodzaj analizy regresji, w której zmienna zależna (przewidywana) jest wielomianem zmiennej niezależnej (używanej do przewidywania). W przeciwieństwie do regresji liniowej, która modeluje dane za pomocą linii prostej, regresja wielomianowa zamiast tego zakrzywia dane. Oznacza to, że regresja wielomianowa może uchwycić bardziej złożone relacje między zmiennymi w porównaniu do regresji liniowej.
Modele regresji wielomianowej są wykorzystywane w różnych zastosowaniach, w tym do przewidywania, prognozowania, optymalizacji i kwantyfikacji niepewności. Jest to szczególnie przydatne narzędzie do przewidywania wartości wykraczających poza zakres zebranych danych i może być wykorzystywane do modelowania nieliniowych zależności w danych.
Aby dopasować model regresji wielomianowej, użytkownik musi najpierw zdefiniować stopień wielomianu (najwyższą moc zmiennej niezależnej), a następnie wygenerować zestaw krzywych, z których każda modeluje dane o różnym stopniu złożoności. Następnie użytkownik wybierze model, który najlepiej pasuje do danych, używając wskaźników takich jak średni błąd kwadratowy (MSE) i R². Gdy znany jest stopień najlepiej dopasowanego wielomianu, można oszacować współczynniki dla każdego wyrażenia w równaniu.
Regresja wielomianowa jest zaawansowanym narzędziem do przewidywania i modelowania złożonych zależności w danych i jest powszechnie stosowana w szerokim zakresie zastosowań, w tym w inżynierii, ekonomii i finansach. Należy jednak pamiętać, że modele regresji wielomianowej powinny być używane tylko wtedy, gdy istnieje wystarczająca ilość danych do wygenerowania wiarygodnych modeli; w przeciwnym razie wyniki mogą być niewiarygodne.