
Google, jako największa wyszukiwarka na świecie, kryje w sobie ogromną skarbnicę cennych informacji. Jednak gdy zajdzie potrzeba automatycznego i obszernego przeglądania wyników wyszukiwania Google, możesz napotkać kilka wyzwań. W tym artykule zagłębimy się w naturę tych wyzwań, omówimy strategie ich przezwyciężenia i poprowadzimy Cię w skutecznym wyodrębnianiu wyników wyszukiwania Google na dużą skalę.
W każdej rozmowie na temat usuwania wyników wyszukiwania Google prawdopodobnie natkniesz się na akronim „SERP”, który oznacza stronę wyników wyszukiwania. To strona, która wita Cię po wpisaniu zapytania w pasku wyszukiwania. Dawno minęły czasy, gdy Google po prostu prezentował listę linków; dzisiejsze SERP to dynamiczna mieszanka funkcji i elementów zaprojektowanych w celu zwiększenia komfortu wyszukiwania. Mając do dyspozycji wiele komponentów do nawigacji, skupmy się na tych kluczowych.
1. Polecane fragmenty
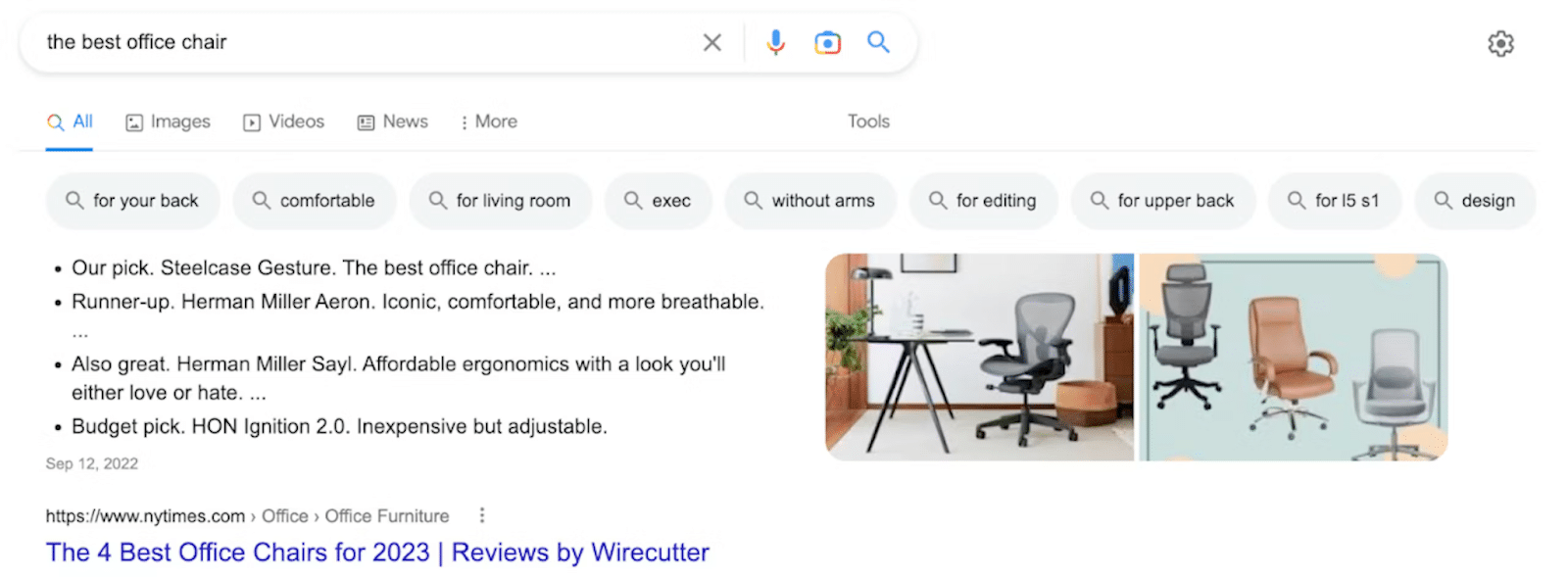
2. Reklamy
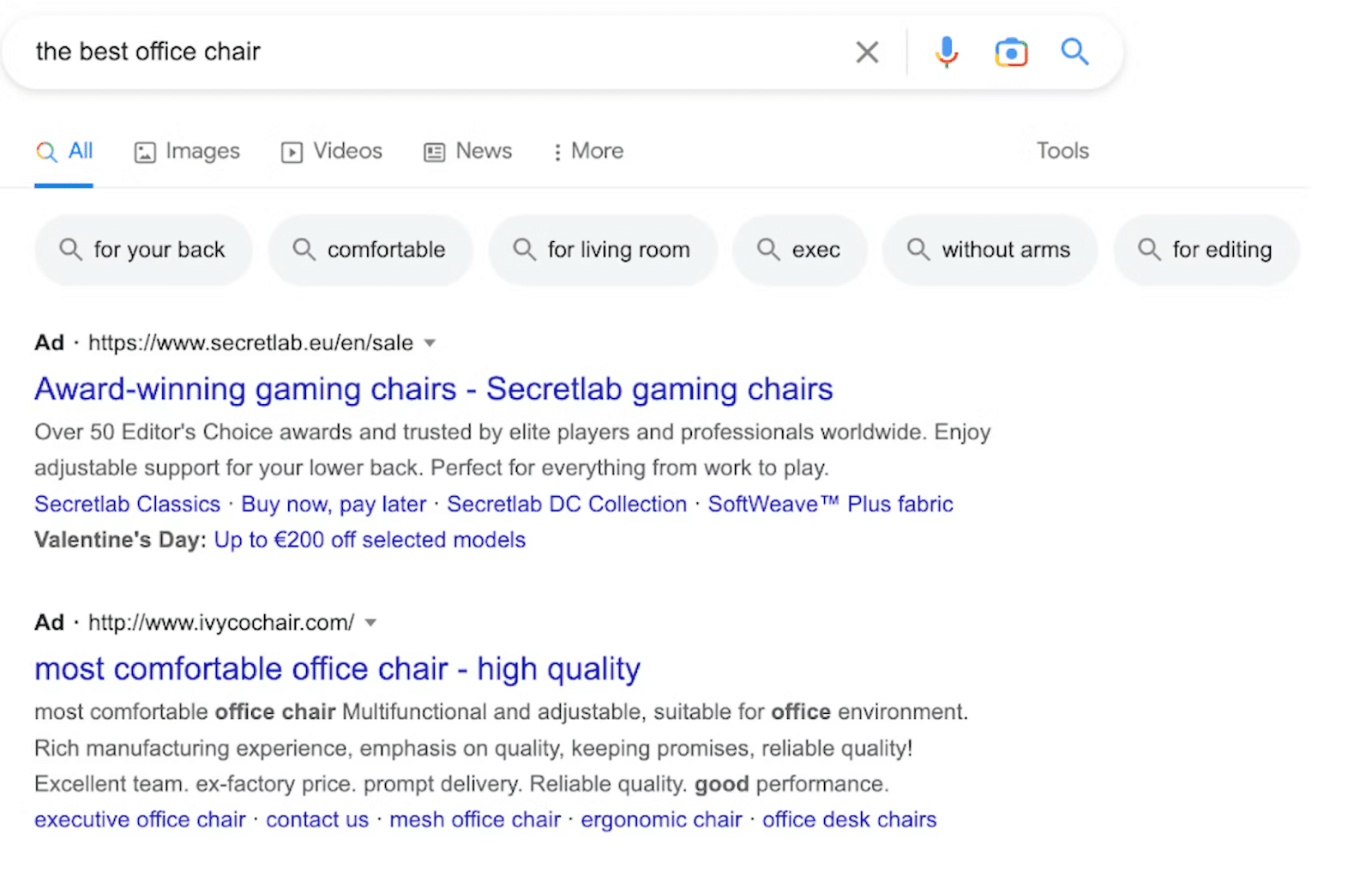
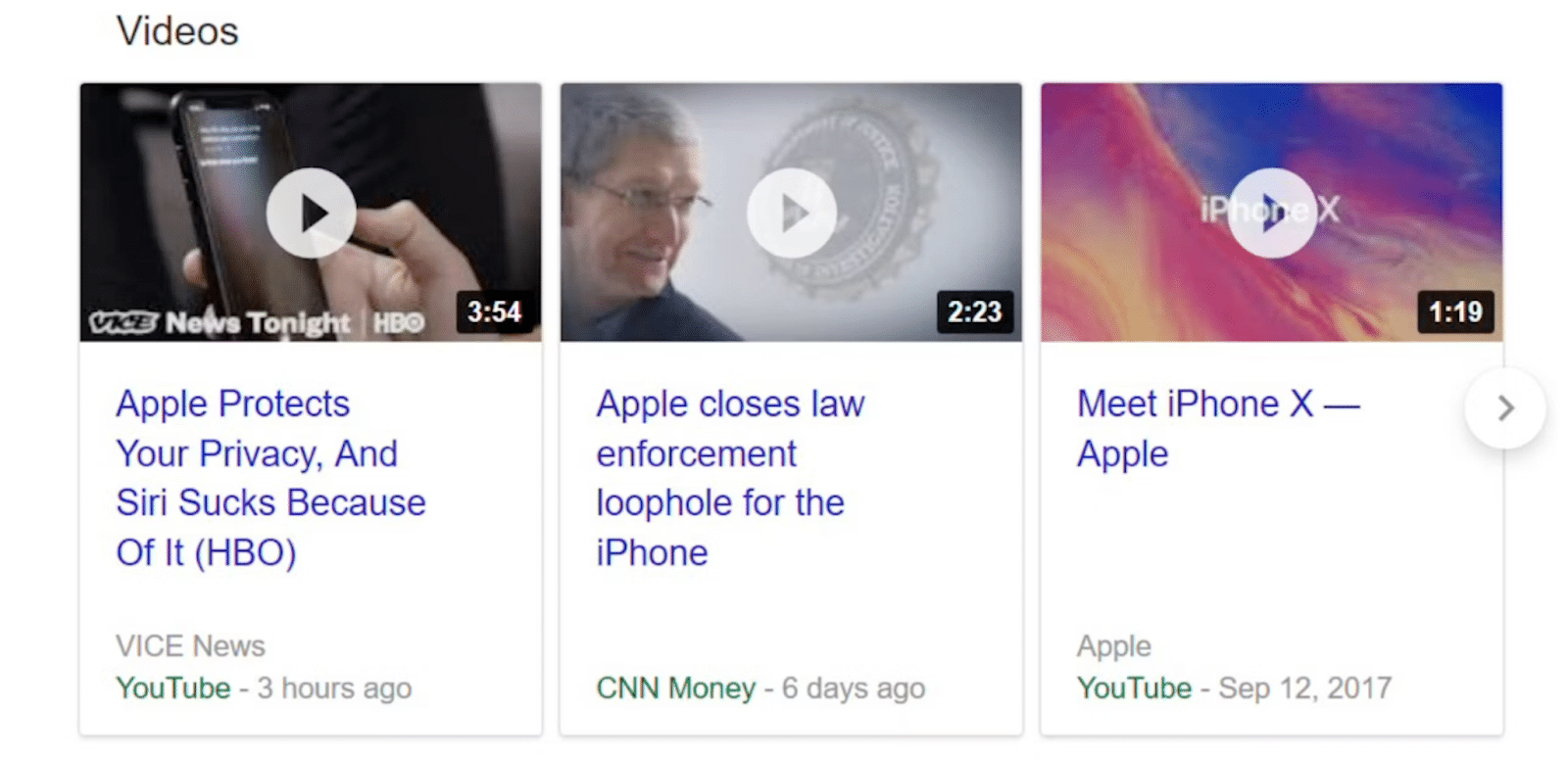
3. Karuzela wideo
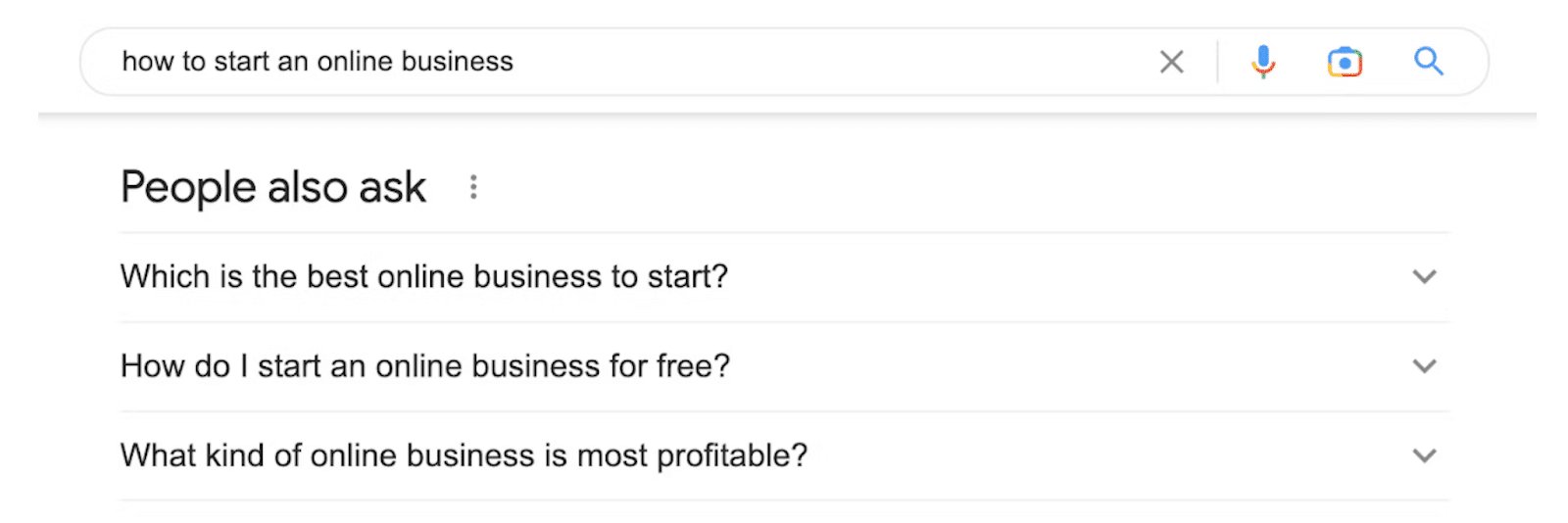
4. Ludzie też pytają
5. Pakiet lokalny
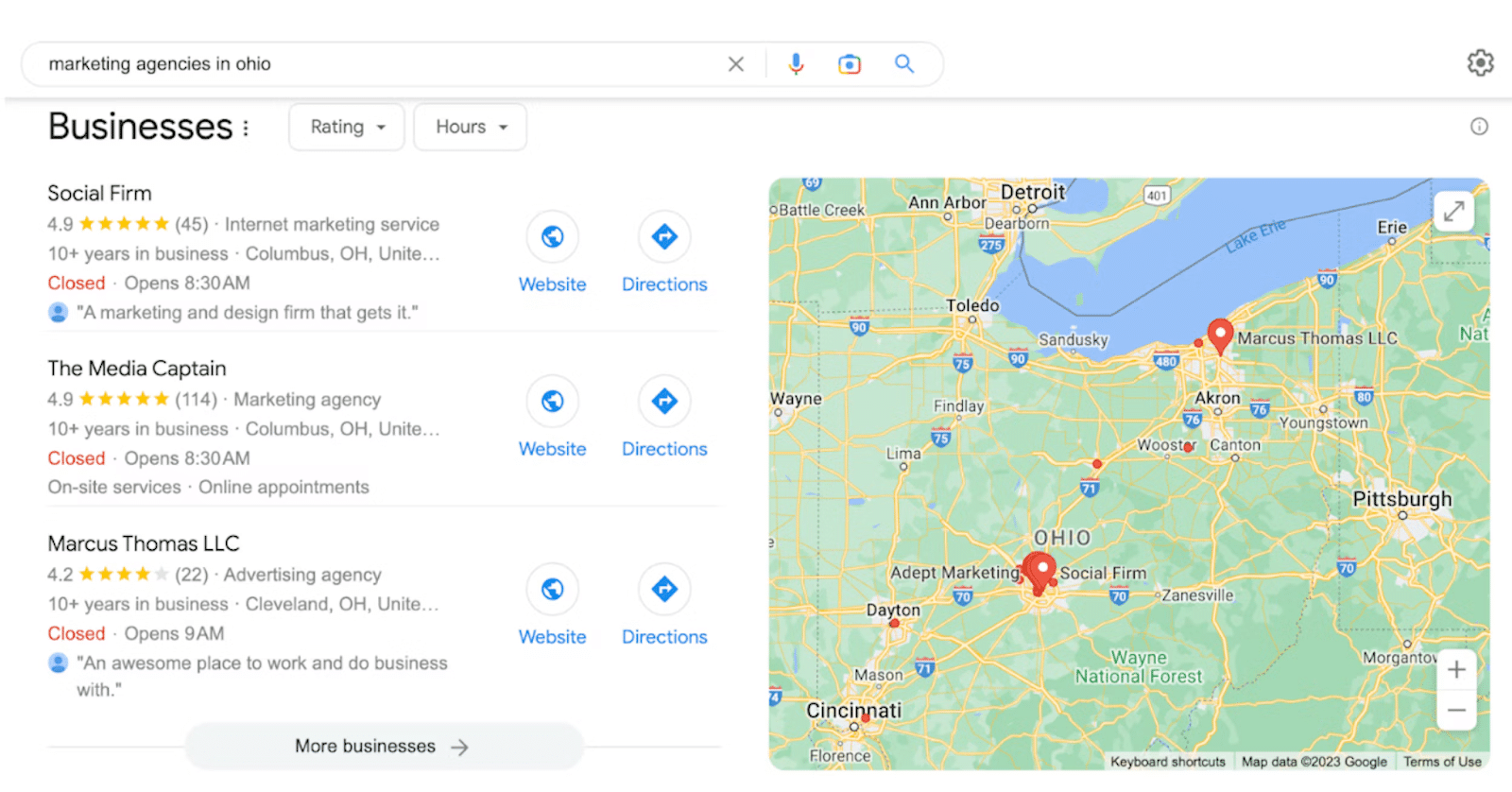
6. Powiązane wyszukiwania
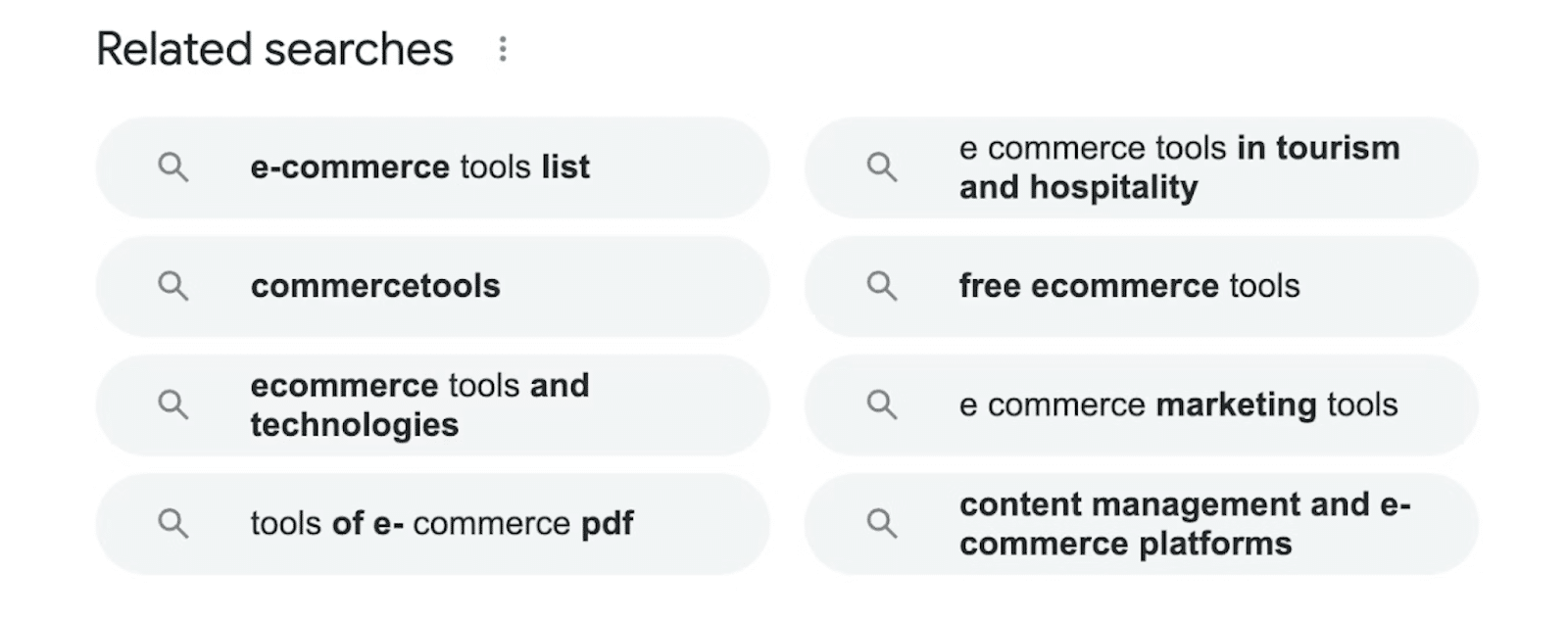
Legalność przeglądania wyników Google
Pytanie, czy skrobanie danych wyszukiwania Google jest legalne, jest częstym tematem w domenie skrobania sieci. Zasadniczo pobieranie publicznie dostępnych danych w Internecie, w tym danych Google SERP, jest ogólnie uważane za legalne. Jednakże zgodność z prawem może się różnić w zależności od konkretnych okoliczności, dlatego wskazane jest zasięgnięcie porady prawnej dostosowanej do Twojej wyjątkowej sytuacji.
Wyzwania związane ze skrobaniem wyników wyszukiwania Google
Jak wspomniano wcześniej, pobieranie danych z wyników wyszukiwania Google stwarza ogromne wyzwania. Google stosuje różne mechanizmy, aby uniemożliwić złośliwym botom zbieranie danych, co prowadzi do złożonego środowiska programów do skrobania sieci. Główny problem wynika z trudności w odróżnieniu botów złośliwych od botów łagodnych, co często skutkuje oznaczaniem lub blokowaniem legalnych skrobaków.
Aby uzyskać głębsze zrozumienie, przyjrzyjmy się konkretnym wyzwaniom napotykanym podczas przeglądania publicznych wyników wyszukiwania Google:
- CAPTCHA
Google wdraża kody CAPTCHA, aby odróżnić prawdziwych użytkowników od zautomatyzowanych botów. Testy te zostały celowo zaprojektowane tak, aby stanowiły wyzwanie dla botów, ale były stosunkowo łatwe do ukończenia przez ludzi. Jeśli odwiedzający nie rozwiąże problemu CAPTCHA po kilku próbach, może to spowodować blokadę adresu IP. Na szczęście zaawansowane narzędzia do przeglądania stron internetowych, takie jak nasze API SERP Scraper, są dobrze wyposażone do obsługi CAPTCHA bez napotykania blokad IP.
- Bloki IP
Twój adres IP jest ujawniany stronom internetowym, które odwiedzasz za każdym razem, gdy angażujesz się w działania online, w tym pobierasz dane Google SERP lub dane z innych stron internetowych. Podczas skrobania sieci Twój skrypt generuje znaczną liczbę żądań. Ta wzmożona aktywność może wzbudzić podejrzenia po stronie witryny, co może prowadzić do blokady adresu IP, co skutecznie ogranicza dostęp do witryny.
- Zdezorganizowane dane
Głównym celem gromadzenia na dużą skalę danych z Google jest dokonanie dokładnej analizy i zdobycie cennych spostrzeżeń. Dane te często służą jako podstawa do kluczowych zadań, takich jak opracowanie solidnej strategii optymalizacji wyszukiwarek (SEO). Aby ułatwić skuteczną analizę, pozyskiwane dane powinny być dobrze zorganizowane i łatwo zrozumiałe. Wymaga to możliwości narzędzia do gromadzenia danych do zwracania informacji w zorganizowanym formacie, takim jak JSON lub CSV.
W świetle tych wyzwań, aby skutecznie je pokonać, niezbędne jest zaawansowane rozwiązanie do skrobania sieci. Fineproxy Google Search API zostało fachowo zaprojektowane do nawigacji i omijania przeszkód technicznych wdrażanych przez Google. Zapewnia bezproblemowy dostęp do publicznych wyników wyszukiwania Google, eliminując potrzebę konserwacji skrobaka po stronie użytkownika.
W rzeczywistości proces przeglądania wyników wyszukiwania za pomocą naszego SERP API jest zarówno prosty, jak i wydajny. Przyjrzyjmy się temu procesowi bardziej szczegółowo. Jeśli szczególnie interesuje Cię zbieranie wyników Zakupów Google, zachęcamy do zapoznania się z naszym innym przewodnikiem, w którym znajdziesz statystyki i wskazówki.
Skrobanie publicznych wyników wyszukiwania Google za pomocą Pythona przy użyciu API
Web scraping to cenna technika gromadzenia danych z Internetu, a wyniki wyszukiwania Google są głównym źródłem informacji. Jednak sortowanie wyników wyszukiwania Google na dużą skalę może być trudnym przedsięwzięciem ze względu na środki wdrożone przez Google w celu odstraszenia automatycznych botów. W tym przewodniku przyjrzymy się, jak pobierać publiczne wyniki wyszukiwania Google przy użyciu języka Python i interfejsu API, co pozwala pokonać złożoność i ograniczenia związane z tradycyjnymi metodami skrobania sieci.
1. Skonfiguruj swoje środowisko:
Zanim zaczniesz przeglądać wyniki wyszukiwania Google, upewnij się, że masz zainstalowane niezbędne narzędzia i biblioteki. Będziesz potrzebował Pythona zainstalowanego w swoim systemie, a także żądań i bibliotek json. Ponadto, aby uzyskać dostęp do wyników wyszukiwania Google, będziesz potrzebować klucza API. Aby uzyskać klucz API, postępuj zgodnie ze wskazówkami Google dotyczącymi tworzenia projektu w Google Developers Console.
żądania importu
importuj jsona
# Zastąp „YOUR_API_KEY” rzeczywistym kluczem API
API_KEY = 'TWÓJ_KLUCZ_API'
# Zdefiniuj adres URL punktu końcowego
ENDPOINT_URL = 'https://www.googleapis.com/customsearch/v1'
# Ustawianie parametrów
search_query = 'Tutaj Twoje wyszukiwane hasło'
search_engine_id = 'Tutaj identyfikator Twojej wyszukiwarki'
# Utwórz adres URL żądania
parametry = {
„klucz”: API_KEY,
„cx”: identyfikator_wyszukiwarki,
„q”: zapytanie_wyszukiwania
}
2. Złóż żądanie API:
Po skonfigurowaniu środowiska możesz teraz wysyłać żądania API w celu pobrania wyników wyszukiwania Google. Musisz wysłać żądanie GET do interfejsu API JSON wyszukiwarki niestandardowej Google i przetworzyć odpowiedź.
# Wyślij żądanie GET do API
odpowiedź = żądania.get(ENDPOINT_URL, params=params)
# Przeanalizuj odpowiedź jako JSON
dane = odpowiedź.json()
# Sprawdź, czy żądanie powiodło się
jeśli „elementy” w danych:
search_results = dane['elementy']
# Przetwarzaj i korzystaj z wyników wyszukiwania według potrzeb
dla wyniku w search_results:
tytuł = wynik['tytuł']
link = wynik['link']
fragment = wynik ['fragment']
# Wykonaj żądane działania na danych
print(f'Tytuł: {tytuł}')
print(f'Link: {link}')
print(f'Snippet: {snippet}')
w przeciwnym razie:
# Obsługa błędów lub brak wyników wyszukiwania
print('Nie znaleziono wyników wyszukiwania lub wystąpił błąd.')
3. Limity szybkości obsługi:
Interfejs API Google ma ograniczenia szybkości, które mogą mieć wpływ na liczbę żądań, które możesz wysłać w określonym przedziale czasu. Upewnij się, że proces zgarniania jest zgodny z tymi limitami. Rozważ wdrożenie opóźnienia między żądaniami, aby uniknąć przekroczenia tych limitów i otrzymania odpowiedzi HTTP 429.
4. Przetwarzanie i przechowywanie danych:
Po pobraniu wyników wyszukiwania Google możesz przetwarzać i przechowywać dane zgodnie z potrzebami konkretnego przypadku użycia. Może to obejmować zapisanie wyników w pliku lokalnym, bazie danych lub przeprowadzenie analizy w czasie rzeczywistym.
5. Przestrzegaj Warunków korzystania z usług Google:
Podczas przeglądania wyników wyszukiwania konieczne jest przestrzeganie warunków korzystania z usług Google. Upewnij się, że wykorzystujesz dane zgodnie z ich zasadami i rozważ uwzględnienie odpowiedniego przypisania podczas wyświetlania wyników wyszukiwania Google.
Podsumowując, skrobanie publicznych wyników wyszukiwania Google przy użyciu Pythona i interfejsu API jest bardziej wydajnym i niezawodnym podejściem w porównaniu z tradycyjnymi metodami skrobania sieci. Mając odpowiedni klucz i kod API, możesz zbierać cenne dane od Google do różnych celów, takich jak badania rynku, analiza SEO czy generowanie treści.
FAQ
Czy skrobanie sieci w Google jest dozwolone?
Jeśli chodzi o skrobanie Google, możesz zastanawiać się nad aspektami prawnymi. Wyniki wyszukiwania Google z reguły są uważane za dane publicznie dostępne, dlatego ich skrobanie jest akceptowalne. Istnieją jednak ograniczenia, dotyczące przede wszystkim danych osobowych i treści chronionych prawem autorskim. Aby zapewnić zgodność, zaleca się wcześniej skonsultować się z prawnikiem.
Czy możesz zeskrobać dane dotyczące wydarzeń Google?
Oczywiście możesz przeszukiwać Google w poszukiwaniu informacji związanych z wydarzeniami, takimi jak koncerty, festiwale, wystawy i spotkania na całym świecie. Po wprowadzeniu słów kluczowych właściwych dla wydarzenia na stronie wyników wyszukiwania wyświetli się dodatkowa tabela wydarzeń zawierająca szczegółowe informacje, takie jak lokalizacja, tytuły wydarzeń, polecane zespoły lub artyści oraz daty. Wymazanie tych danych publicznych jest wykonalne. Niemniej jednak należy podkreślić, że pobieranie danych z Google musi odbywać się zgodnie ze wszystkimi obowiązującymi przepisami. Rozsądnie jest zasięgnąć porady prawnej, zwłaszcza w przypadku gromadzenia danych na dużą skalę.
Czy skrobanie lokalnych wyników Google jest dozwolone?
Google wykorzystuje połączenie parametrów trafności i bliskości, aby zapewnić optymalne wyniki wyszukiwania. Na przykład, szukając lokalnych kawiarni, Google prezentuje opcje w najbliższej okolicy, a nawet podaje wskazówki dojazdu. Te konkretne wyniki wyszukiwania są klasyfikowane jako wyniki Google Local i różnią się od wyników Map Google, które skupiają się na nawigacji. Pod warunkiem, że będziesz przestrzegać odpowiednich przepisów, rzeczywiście możesz pobrać publiczne wyniki Google Local dla swojego projektu. W celu zapewnienia właściwej zgodności zaleca się zasięgnięcie porady eksperta prawnego.
Czy możesz wyodrębnić informacje z sekcji „Informacje o tym wyniku”?
Google oferuje dodatkowe informacje na temat witryny, w której znajduje się wynik wyszukiwania, klikając trzy kropki sąsiadujące z prawą stroną wyniku wyszukiwania. Z pewnością możesz usunąć te publicznie dostępne dane, ale ważne jest, aby ściśle przestrzegać obowiązujących zasad i przepisów. Szczególnie w przypadku rozważania obszernej ekstrakcji danych rozważnym rozwiązaniem jest konsultacja z prawnikiem.
Skrobanie wyników z Google Video: czy jest to dozwolone?
Pobieranie publicznych wyników wyszukiwania w serwisie Google Video jest ogólnie uważane za legalne. Należy jednak podkreślić, że istotne jest ścisłe przestrzeganie obowiązujących przepisów i zasad. Ta praktyka może być korzystna przy gromadzeniu metatytułów, opisów filmów, adresów URL i innych informacji w konkretnym przypadku użycia. Niemniej jednak przed rozpoczęciem obszernego gromadzenia danych dobrym wyborem jest konsultacja z ekspertem prawnym.
Podstawowe metody skrobania stron wyszukiwania Google
Aby zebrać dane ze stron wyszukiwania Google, masz do dyspozycji dwie podstawowe metody: ekstrakcję w oparciu o adres URL i ekstrakcję w oparciu o wyszukiwane hasło. Podejście oparte na adresach URL polega na uzyskiwaniu danych ze strony wyników wyszukiwania Google przy użyciu skopiowanego adresu URL, niezależnie od tego, czy pochodzi on z domeny Google dowolnego kraju (np. google.co.uk). Cieszysz się możliwością dodania dowolnej liczby adresów URL, ile jest wymagane do osiągnięcia Twoich celów.







Komentarze (0)
Nie ma tu jeszcze żadnych komentarzy, możesz być pierwszy!