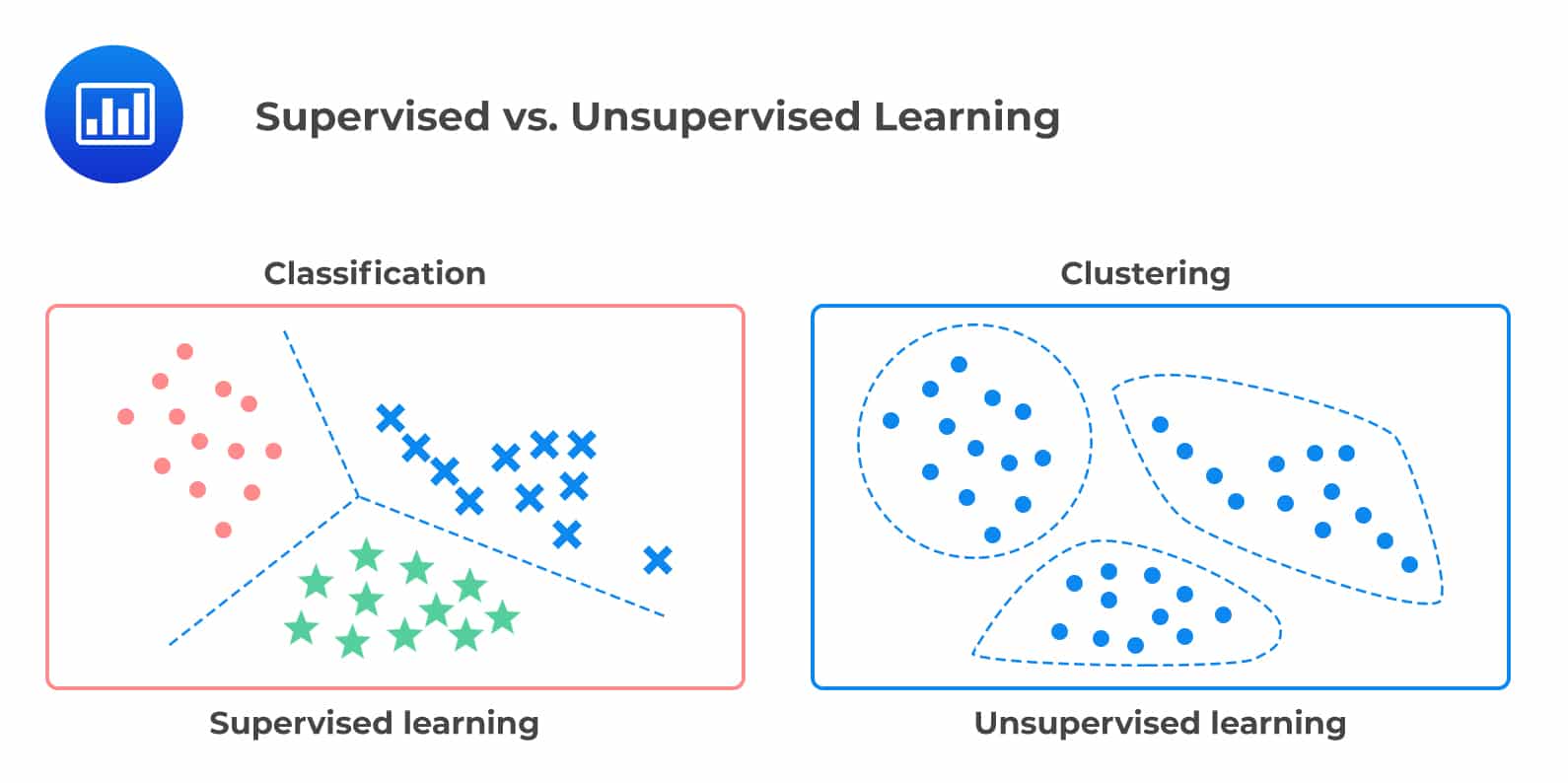
비지도 학습은 레이블이나 다른 형태의 피드백에 의존하지 않고 작동하는 머신 러닝의 한 유형입니다. 알고리즘에 원시 입력 데이터를 제공한 다음 통계 분석을 사용하여 공통 패턴이나 특징을 감지합니다. 비지도 학습은 기존 데이터에서 새로운 정보를 추출하거나 유사한 데이터를 함께 그룹화하는 클러스터링 분석을 수행하는 데 사용됩니다.
지도 학습에 필요한 레이블이 부족하기 때문에 비지도 학습 모델은 데이터의 패턴을 감지하기 위해 더 많은 처리 능력이 필요합니다. 이러한 형태의 머신 러닝은 유사한 데이터 포인트 그룹을 식별하고 불규칙성이나 이상값을 감지할 수 있어 컴퓨터 비전, 자연어 처리, 텍스트 마이닝 등의 작업에 매우 유용합니다. 마케팅 및 금융과 같은 분야에서는 비지도 학습을 활용하여 알려지지 않은 고객 세그먼트를 발견하고 사기 행위를 탐지할 수 있습니다.
비지도 학습 방법에 가장 많이 사용되는 알고리즘은 K-평균 및 계층적 클러스터링과 같은 클러스터링 방법, 주성분 분석(PCA), Apriori와 같은 연관 방법입니다. 이러한 방법을 통해 기계는 서로 다른 데이터 간의 관계나 연관성을 찾을 수 있습니다. 이러한 알고리즘은 각각 고유한 장점과 사용 사례를 가지고 있으므로 당면한 작업에 적합한 알고리즘을 선택하는 것이 중요합니다.
비지도 학습은 데이터 집합을 더 잘 이해하기 위한 중요한 도구입니다. 데이터의 구조와 패턴을 식별하는 방법을 이해함으로써 기계는 사용 가능한 데이터에서 더 많은 정보에 입각한 결정을 내리고 더 정확한 결과를 도출할 수 있습니다. 이러한 유형의 기술이 지속적으로 개선됨에 따라 기계가 데이터와 상호 작용하는 방식에 혁명을 일으킬 수 있으며, 여러 분야에서 필수적인 도구가 될 수 있습니다.