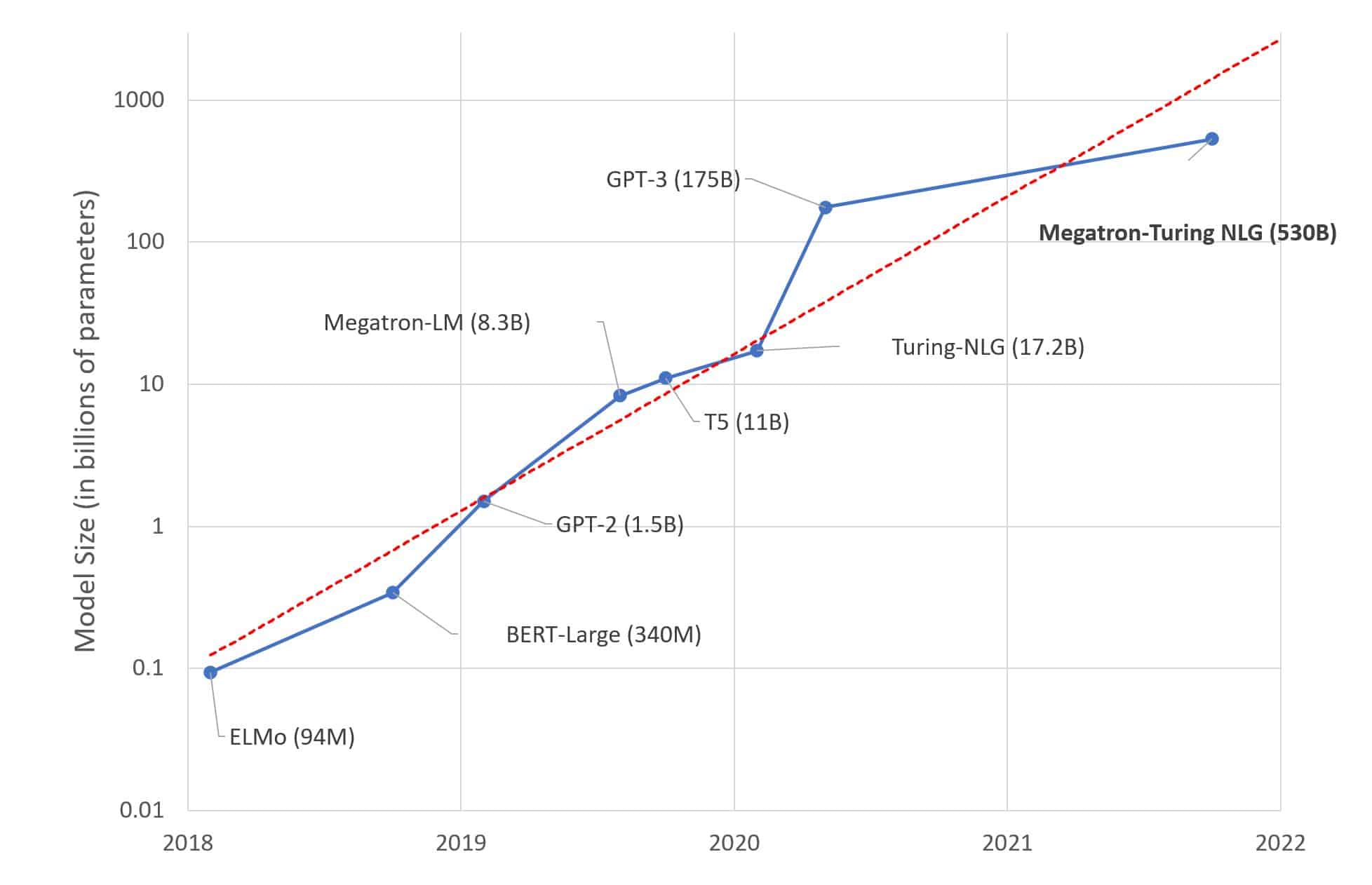
Velké jazykové modely jsou typem umělé inteligence (AI) používané v aplikacích pro zpracování přirozeného jazyka (NLP). Tyto modely jsou vyškoleny a optimalizovány tak, aby efektivně a přesně zpracovávaly velké množství textových dat. Používají se pro různé úkoly související s porozuměním přirozenému jazyku, jako je klasifikace textu, sumarizace textu, generování textu a analýza sentimentu.
Velké jazykové modely využívají typ strojového učení nazývaného hluboké učení. To zahrnuje použití neuronových sítí k učení složitých vzorců z velkého množství dat. Tyto modely jsou trénovány na objemech textových dat, jako jsou knihy, zpravodajské články a konverzace. Pomocí těchto dat se mohou naučit rozumět přirozenému jazyku a generovat jej.
Na rozdíl od tradičních přístupů NLP mohou velké jazykové modely zpracovávat textové toky jako celek bez nutnosti ručního předzpracování. Modely se spíše učí z daného úkolu a mohou předpovídat a generovat text s vyšší přesností a vyšší rychlostí. Jako takové se stávají stále populárnějšími v mnoha aplikacích AI.
Velké jazykové modely byly použity v mnoha aplikacích, od analýzy obsahu přes zodpovězení otázek až po automatizovaný dialog. Byly také použity k identifikaci podezřelého online chování v kontextu kybernetické bezpečnosti.
Stručně řečeno, velké jazykové modely jsou typem umělé inteligence používané k porozumění přirozenému jazyku. Díky učení z velkého množství textových dat mohou tyto modely přesně zpracovávat a generovat text rychleji a efektivněji než tradiční přístupy. V důsledku toho se stávají stále oblíbenějšími v mnoha aplikacích umělé inteligence, včetně kybernetické bezpečnosti.