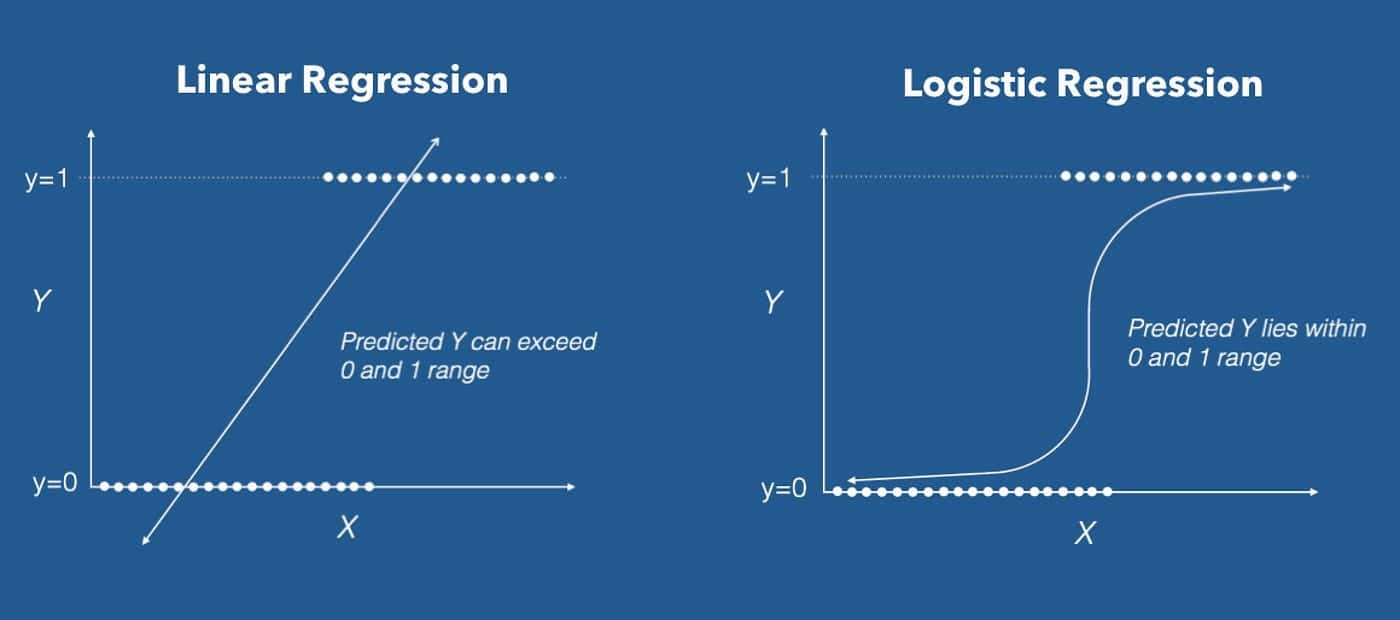
A regressão logística é um algoritmo usado principalmente para tarefas de aprendizado supervisionado, como a previsão de resultados binários, por exemplo, se um candidato será aprovado para um empréstimo. O termo "regressão logística" refere-se ao método de maximizar a probabilidade de ocorrência de um determinado resultado em um conjunto de variáveis independentes ou preditoras. Isso é feito por meio da otimização de uma equação matemática que expressa as probabilidades da variável dependente positiva como uma função das variáveis independentes.
A regressão logística é um dos algoritmos mais usados no aprendizado supervisionado, pois oferece poder de previsão com flexibilidade e escalabilidade. Isso se deve à sua capacidade de incorporar diferentes tipos de variáveis preditoras com facilidade e fornecer interpretações para as probabilidades estimadas. Além disso, a regressão logística tem a flexibilidade de ser aplicada a casos de problemas de classificação em um ou vários níveis e problemas de regressão não linear.
Quando se trata de suas aplicações em computação, a regressão logística é mais comumente usada em aprendizado de máquina (ML) e mineração de dados, onde é usada para classificar dados. Algumas aplicações populares incluem a análise preditiva da rotatividade de clientes, a medição da qualidade das decisões de empréstimo, a previsão de diagnósticos médicos, a detecção de atividades fraudulentas e assim por diante. Também é usado na análise da Web para detectar a taxa de cliques e em ferramentas de processamento de linguagem natural (NLP) para distinguir entre diferentes tipos de documentos.
A regressão logística pode ser implementada em uma variedade de ambientes de programação, como R, Python e Java, e usando diferentes bibliotecas, como scikit-learn, Spark MLlib e Weka. Os métodos comuns usados para implementar esse algoritmo incluem descida de gradiente, método de Newton e métodos de direção conjugada. Além disso, esse algoritmo pode ser ampliado com técnicas de regularização para reduzir o excesso de ajuste.
Em termos de segurança cibernética, a regressão logística pode ser usada para detecção de anomalias de atividades e detecção de fraudes. A detecção de anomalias é o processo de identificação de padrões incomuns nos dados que diferem significativamente do comportamento normal do sistema. A regressão logística é usada para classificar os dados em comportamento normal ou anormal, com base nos preditores. A detecção de fraudes é o processo de identificação de atividades maliciosas nos dados. Nesse caso, a regressão logística é usada para identificar a probabilidade de fraude com base nos valores dos preditores.
Em geral, a regressão logística é um algoritmo eficaz usado em muitas áreas da computação e da segurança cibernética, oferecendo um poder de previsão confiável. Sua escalabilidade e flexibilidade para incorporar diferentes preditores faz com que seja um método comumente usado em muitas tarefas de análise de dados.