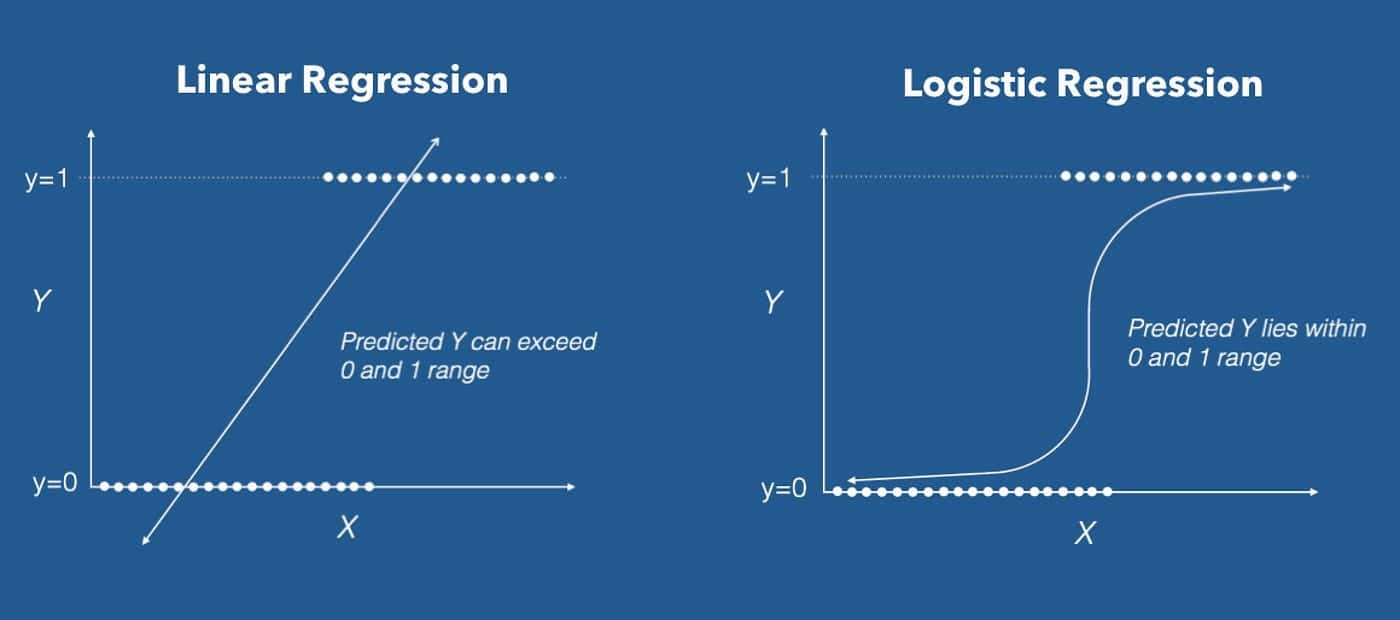
La régression logistique est un algorithme utilisé principalement pour des tâches d'apprentissage supervisé telles que la prédiction de résultats binaires, comme l'obtention d'un prêt par un demandeur. Le terme "régression logistique" fait référence à la méthode consistant à maximiser la probabilité qu'un certain résultat se produise compte tenu d'un ensemble de variables indépendantes ou prédictives. Pour ce faire, on optimise une équation mathématique qui exprime les probabilités de la variable dépendante positive en fonction des variables indépendantes.
La régression logistique est l'un des algorithmes les plus utilisés pour l'apprentissage supervisé, car elle offre un pouvoir prédictif tout en étant flexible et évolutive. Cela est dû à sa capacité à incorporer facilement différents types de variables prédictives et à fournir des interprétations pour les probabilités estimées. En outre, la régression logistique a la souplesse nécessaire pour être appliquée aux problèmes de classification à un ou plusieurs niveaux et aux problèmes de régression non linéaire.
En ce qui concerne ses applications informatiques, la régression logistique est le plus souvent utilisée dans l'apprentissage machine (ML) et l'exploration de données, où elle sert à classer les données. Parmi les applications les plus courantes, on peut citer l'analyse prédictive du taux de désabonnement des clients, la mesure de la qualité des décisions de prêt, la prédiction des diagnostics médicaux, la détection des activités frauduleuses, etc. Elle est également utilisée dans l'analyse web pour détecter le taux de clics et dans les outils de traitement du langage naturel (NLP) pour faire la distinction entre différents types de documents.
La régression logistique peut être mise en œuvre dans divers environnements de programmation, tels que R, Python et Java, et en utilisant différentes bibliothèques telles que scikit-learn, Spark MLlib et Weka. Les méthodes couramment utilisées pour mettre en œuvre cet algorithme comprennent la descente de gradient, la méthode de Newton et les méthodes de direction conjuguée. En outre, cet algorithme peut être complété par des techniques de régularisation afin de réduire l'ajustement excessif.
En termes de cybersécurité, la régression logistique peut être utilisée pour la détection d'anomalies dans les activités et la détection des fraudes. La détection d'anomalies est le processus d'identification de modèles inhabituels dans les données qui diffèrent de manière significative du comportement normal du système. La régression logistique est utilisée pour classer les données en comportement normal ou anormal, sur la base des prédicteurs. La détection des fraudes est le processus d'identification des activités malveillantes dans les données. Dans ce cas, la régression logistique est utilisée pour identifier la probabilité de fraude en fonction des valeurs des prédicteurs.
Dans l'ensemble, la régression logistique est un algorithme efficace utilisé dans de nombreux domaines de l'informatique et de la cybersécurité, car elle offre un pouvoir prédictif fiable. Son évolutivité et sa souplesse d'intégration de différents prédicteurs en font une méthode couramment utilisée dans de nombreuses tâches d'analyse de données.