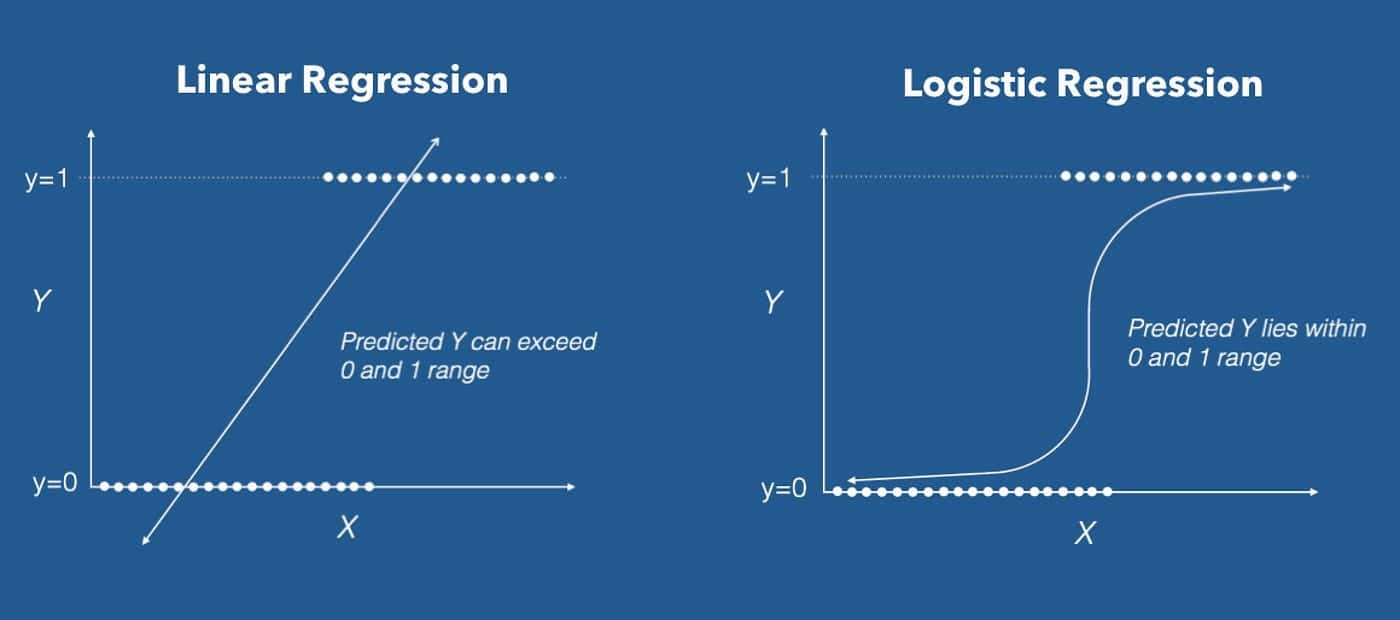
La regresión logística es un algoritmo utilizado principalmente para tareas de aprendizaje supervisado, como la predicción de resultados binarios, por ejemplo, si se aprobará un préstamo a un solicitante. El término "regresión logística" se refiere al método de maximizar la probabilidad de que se produzca un determinado resultado dado un conjunto de variables independientes o predictoras. Para ello, se optimiza una ecuación matemática que expresa las probabilidades de la variable dependiente positiva en función de las variables independientes.
La regresión logística es uno de los algoritmos más utilizados para el aprendizaje supervisado, ya que ofrece poder predictivo con flexibilidad y escalabilidad. Esto se debe a su capacidad para incorporar diferentes tipos de variables predictoras con facilidad y proporcionar interpretaciones para las probabilidades estimadas. Además, la regresión logística tiene la flexibilidad de poder aplicarse a casos de problemas de clasificación de uno o varios niveles y a problemas de regresión no lineal.
En cuanto a sus aplicaciones informáticas, la regresión logística se utiliza sobre todo en el aprendizaje automático y la minería de datos, donde se emplea para clasificar datos. Algunas de sus aplicaciones más populares son el análisis predictivo de la pérdida de clientes, la medición de la calidad de las decisiones de préstamo, la predicción de diagnósticos médicos, la detección de actividades fraudulentas, etcétera. También se utiliza en analítica web para detectar la tasa de clics y en herramientas de procesamiento del lenguaje natural (PLN) para distinguir entre distintos tipos de documentos.
La regresión logística se puede implementar en una variedad de entornos de programación, como R, Python y Java, y mediante el uso de diferentes bibliotecas como scikit-learn, Spark MLlib y Weka. Entre los métodos comunes utilizados para implementar este algoritmo se incluyen el descenso de gradiente, el método de Newton y los métodos de dirección conjugada. Además, este algoritmo puede aumentarse con técnicas de regularización para reducir el sobreajuste.
En términos de ciberseguridad, la regresión logística puede utilizarse para la detección de anomalías en la actividad y la detección de fraudes. La detección de anomalías es el proceso de identificación de patrones inusuales en los datos que difieren significativamente del comportamiento normal del sistema. La regresión logística se utiliza para clasificar los datos en comportamiento normal o anormal, basándose en los predictores. La detección de fraudes es el proceso de identificar actividades maliciosas en los datos. En este caso, la regresión logística se utiliza para identificar la probabilidad de fraude basándose en los valores de los predictores.
En general, la regresión logística es un algoritmo eficaz utilizado en muchas áreas de la informática y la ciberseguridad, que ofrece un poder predictivo fiable. Su escalabilidad y flexibilidad para incorporar distintos predictores lo convierten en un método de uso común en muchas tareas de análisis de datos.