
Google kui maailma suurim otsingumootor sisaldab tohutut väärtuslikku teavet. Kui aga tekib vajadus Google'i otsingutulemuste automaatseks ja ulatuslikuks kraapimiseks, võite silmitsi seista mõne väljakutsega. Selles artiklis uurime nende väljakutsete olemust, uurime strateegiaid nende ületamiseks ja juhendame teid Google'i otsingutulemuste ulatuslikul hankimisel.
Igas Google'i otsingutulemuste kraapimist puudutavas vestluses kohtate tõenäoliselt akronüümi SERP, mis tähistab otsingumootori tulemuste lehte. See on leht, mis tervitab teid pärast päringu sisestamist otsinguribale. Möödas on ajad, mil Google esitas vaid linkide loendi; Tänapäeva SERP-id on dünaamiline kombinatsioon funktsioonidest ja elementidest, mis on loodud teie otsingukogemuse täiustamiseks. Kuna navigeerimiseks on palju komponente, keskendume peamistele.
1. Esiletõstetud katkendid
2. Reklaamid
3. Videokarussell
4. Inimesed küsivad ka
5. Kohalik pakk
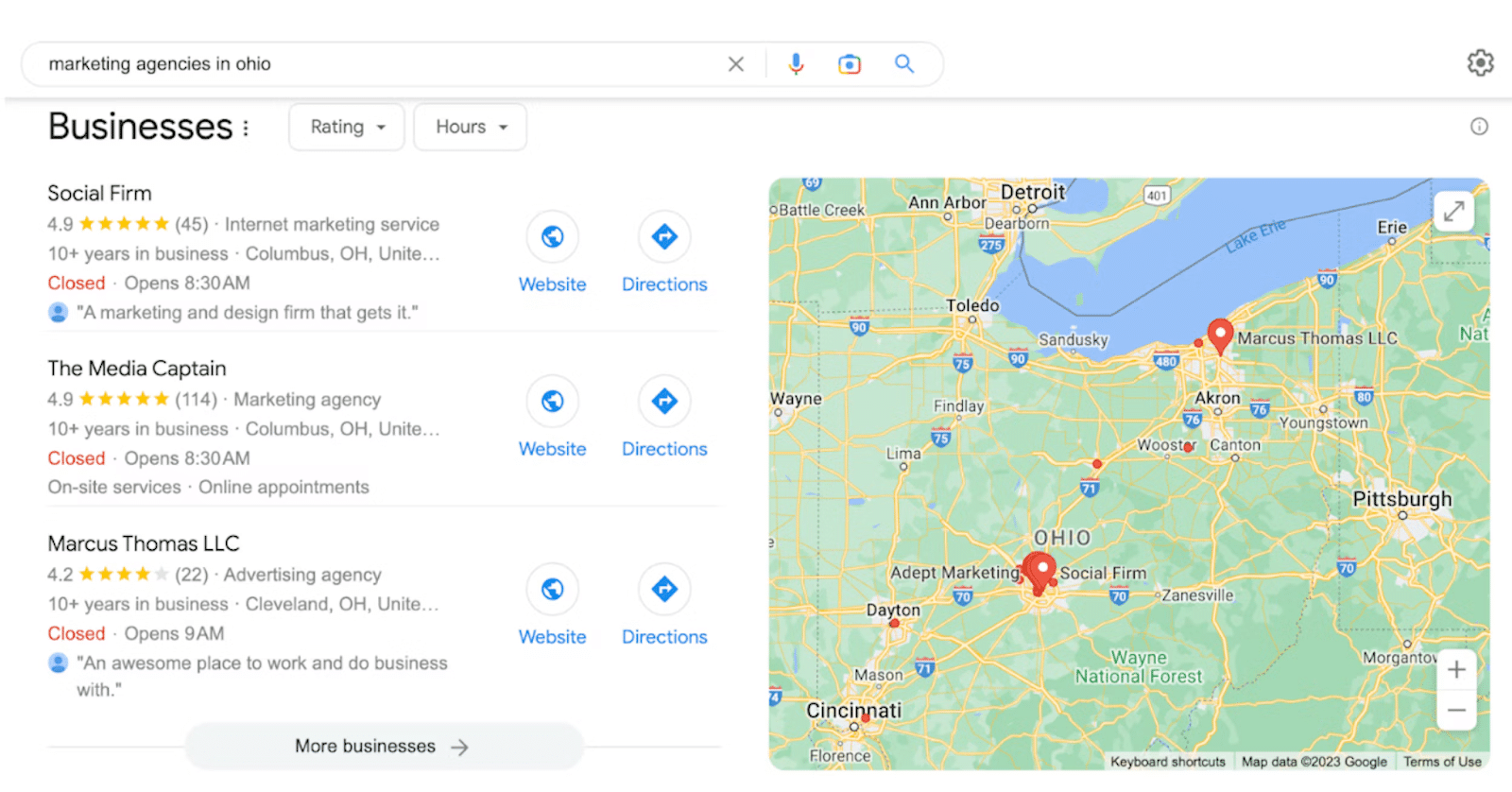
6. Seotud otsingud
Google'i tulemuste kraapimise seaduslikkus
Küsimus, kas Google'i otsinguandmete kraapimine on seaduslik, on veebi kraapimise domeenis tavaline teema. Sisuliselt peetakse Internetis avalikult juurdepääsetavate andmete, sealhulgas Google SERP-andmete kraapimist üldiselt seaduslikuks. Seaduslikkus võib aga olenevalt konkreetsetest asjaoludest erineda, mistõttu on soovitatav otsida teie ainulaadsele olukorrale kohandatud õigusnõu.
Väljakutsed Google'i otsingutulemuste kraapimisel
Nagu varem mainitud, on Google'i otsingutulemuste andmete kraapimine tohutu väljakutse. Google kasutab erinevaid mehhanisme, et takistada pahatahtlikke roboteid oma andmeid kogumast, mis viib veebikaabitsate jaoks keeruka maastikuni. Peamine probleem tuleneb raskustest teha vahet pahatahtlike robotite ja healoomuliste robotite vahel, mille tulemuseks on sageli seaduslike kaabitsate märgistamine või keelamine.
Sügavama arusaamise saamiseks süveneme konkreetsetesse väljakutsetesse, mis ilmnesid avalike Google'i otsingutulemuste kraapimisel.
- CAPTCHAd
Google kasutab CAPTCHA-sid tõeliste kasutajate ja automatiseeritud robotite eristamiseks. Need testid on sihilikult kavandatud nii, et need oleksid robotite jaoks keerulised, kuid inimestele suhteliselt lihtsad. Kui külastajal ei õnnestu pärast mitut katset CAPTCHA-d lahendada, võib see käivitada IP-blokeeringud. Õnneks on täiustatud veebikraapimise tööriistad, nagu meie SERP Scraper API, hästi varustatud CAPTCHA-de käsitlemiseks ilma IP-plokkideta.
- IP-blokid
Teie IP-aadress on avatud veebisaitidele, mida külastate alati, kui tegelete võrgutoimingutega, sealhulgas kraapides Google SERP-i andmeid või andmeid teistelt veebisaitidelt. Veebi kraapimisel genereerib teie skript märkimisväärse hulga taotlusi. See kõrgendatud tegevus võib vallandada veebisaidi lõpus kahtlusi, mis võib viia IP-keeluni, mis piirab tõhusalt juurdepääsu saidile.
- Korraldamata andmed
Google'i suuremahulise andmete kogumise peamine eesmärk on teha põhjalik analüüs ja saada väärtuslikku teavet. Need andmed on sageli aluseks olulistele ülesannetele, nagu näiteks tugeva otsingumootori optimeerimise (SEO) strateegia väljatöötamine. Tõhusa analüüsi hõlbustamiseks peaksid saadud andmed olema hästi struktureeritud ja kergesti arusaadavad. See nõuab teie andmete kogumistööriista võimet tagastada teavet organiseeritud vormingus, näiteks JSON- või CSV-vormingus.
Neid väljakutseid silmas pidades on täiustatud veebikraapimislahendus nende tõhusaks ületamiseks hädavajalik. Fineproxy Google Search API on asjatundlikult loodud Google'i rakendatud tehniliste tõkete navigeerimiseks ja nendest mööda hiilimiseks. See tagab sujuva juurdepääsu avalikele Google'i otsingutulemustele, välistades vajaduse kasutajal kaabitsat hooldada.
Tegelikult on meie SERP API-ga otsingutulemuste kraapimise protsess nii lihtne kui ka tõhus. Uurime seda protsessi üksikasjalikumalt. Kui teil on konkreetne huvi Google Shoppingu tulemuste kogumise vastu, soovitame teil ülevaate ja juhiste saamiseks vaadata meie teist juhendit.
Avalike Google'i otsingutulemuste kraapimine Pythoni abil API abil
Veebi kraapimine on väärtuslik tehnika Internetist andmete kogumiseks ja Google'i otsingutulemused on peamine teabeallikas. Google'i otsingutulemuste ulatuslik kraapimine võib aga olla keeruline ettevõtmine Google'i automatiseeritud robotite ärahoidmiseks rakendatud meetmete tõttu. Selles juhendis uurime, kuidas kraapida avalikke Google'i otsingutulemusi Pythoni ja API abil, mis võimaldab teil ületada traditsiooniliste veebikraapimismeetoditega seotud keerukusi ja piiranguid.
1. Seadistage oma keskkond:
Enne Google'i otsingutulemuste kraapimist veenduge, et teil on installitud vajalikud tööriistad ja teegid. Peate oma süsteemi installima Pythonit, samuti päringuid ja jsoni teeke. Lisaks vajate Google'i otsingutulemustele juurdepääsuks API-võtit. API-võtme hankimiseks järgige Google'i juhiseid projekti loomise kohta Google Developers Console'is.
imporditaotlused
importida json
# Asenda 'YOUR_API_KEY' oma tegeliku API võtmega
API_KEY = 'SINU_API_KEY'
# Määrake lõpp-punkti URL
ENDPOINT_URL = 'https://www.googleapis.com/customsearch/v1'
# Seadistage parameetrid
search_query = 'Teie otsingupäring siin'
search_engine_id = 'Teie otsingumootori ID siin'
# Looge päringu URL
params = {
'võti': API_KEY,
'cx': search_engine_id,
'q': search_query
}
2. Esitage API taotlusi:
Kui teie keskkond on seadistatud, saate nüüd teha API taotlusi Google'i otsingutulemuste toomiseks. Peate saatma Google'i kohandatud otsingu JSON API-le GET-päringu ja töötlema vastust.
# Saatke API-le GET-i päring
vastus = requests.get(ENDPOINT_URL, params=params)
# Parsige vastust JSON-vormingus
andmed = vastus.json()
# Kontrollige, kas taotlus oli edukas
kui andmetes on "üksused":
search_results = andmed['üksused']
# Töötle ja kasuta otsingutulemusi vastavalt vajadusele
tulemuste jaoks otsingutulemustes:
pealkiri = tulemus['pealkiri']
link = tulemus['link']
katkend = tulemus['jupp']
# Tehke andmetega soovitud toimingud
print(f'Title: {title}')
print(f'Link: {link}')
print(f'Snippet: {snippet}')
muu:
# Käsitlege vigu või otsingutulemuste puudumist
print('Otsingutulemusi ei leitud või ilmnes viga.')
3. Käsitsemiskiiruse piirangud:
Google'i API-l on piirangud, mis võivad mõjutada konkreetse aja jooksul esitatavate taotluste arvu. Veenduge, et teie kraapimisprotsess järgiks neid kiiruse piiranguid. Kaaluge taotluste vahelise viivituse rakendamist, et vältida nende piirangute ületamist ja HTTP 429 vastuste saamist.
4. Andmete töötlemine ja säilitamine:
Pärast Google'i otsingutulemuste hankimist saate andmeid töödelda ja salvestada vastavalt teie konkreetsele kasutusjuhtumile. See võib hõlmata tulemuste salvestamist kohalikku faili, andmebaasi või reaalajas analüüsi.
5. Järgige Google'i teenusetingimusi:
Otsingutulemuste kraapimisel on oluline järgida Google'i teenusetingimusi. Veenduge, et teie andmete kasutamine oleks kooskõlas nende eeskirjadega, ja kaaluge Google'i otsingutulemuste kuvamisel õige omistamise kaasamist.
Kokkuvõttes on avalike Google'i otsingutulemuste kraapimine Pythoni ja API abil tõhusam ja usaldusväärsem lähenemine võrreldes traditsiooniliste veebikraapimismeetoditega. Õige API võtme ja koodiga saate koguda Google'ilt väärtuslikke andmeid erinevatel eesmärkidel, näiteks turu-uuringuteks, SEO analüüsiks või sisu genereerimiseks.
KKK
Kas Google'i veebikraapimine on lubatud?
Kui tegemist on Google'i kraapimisega, võite küsida juriidiliste aspektide üle. Google'i otsingutulemusi peetakse üldreeglina avalikult kättesaadavaks, mistõttu on nende kraapimine vastuvõetav. Siiski on piiranguid, mis puudutavad peamiselt isikuandmeid ja autoriõigustega kaitstud sisu. Nõuetele vastavuse tagamiseks on soovitatav eelnevalt konsulteerida juristiga.
Kas saate Google'i sündmuste andmeid kraapida?
Kindlasti saate Google'ist otsida sündmustega seotud teavet, nagu kontserdid, festivalid, näitused ja kogunemised üle kogu maailma. Sisestades sündmusepõhised märksõnad, näete otsingumootori tulemuste lehel täiendavat sündmuste tabelit, mis sisaldab üksikasju, nagu asukoht, sündmuste pealkirjad, esiletõstetud bändid või artistid ja kuupäevad. Neid avalikke andmeid on võimalik kraapida. Sellegipoolest on oluline rõhutada, et Google'ist andmete hankimine peab toimuma kooskõlas kõigi asjakohaste eeskirjadega. Mõistlik on otsida õigusnõu, eriti kui tegemist on suuremahulise andmete kogumisega.
Kas Google'i kohalike tulemuste kraapimine on lubatud?
Google kasutab optimaalsete otsingutulemuste pakkumiseks asjakohasuse ja läheduse parameetrite segu. Näiteks kohalikke kohvikuid otsides pakub Google valikuvõimalusi vahetus läheduses ja pakub isegi juhiseid. Need konkreetsed otsingutulemused liigitatakse Google Locali tulemuste alla ja erinevad Google Mapsi tulemustest, mis keskenduvad navigeerimisele. Eeldusel, et järgite asjakohaseid eeskirju, saate tõepoolest koguda oma projekti jaoks avalikud Google Locali tulemused. Nõuetekohase täitmise tagamiseks on soovitatav küsida nõu õiguseksperdilt.
Kas saate jaotistest "Selle tulemuse kohta" teavet välja võtta?
Google pakub täiendavat teavet veebisaidi kohta, kus otsingutulemus asub, klõpsates otsingutulemuse paremal küljel asuval kolmel punktil. Kindlasti saate neid avalikult kättesaadavaid andmeid kraapida, kuid on ülioluline järgida rangelt kehtivaid eeskirju ja eeskirju. Eriti kui kaaluda ulatuslikku andmete hankimist, on juristiga konsulteerimine mõistlik tegevus.
Google'i videotulemuste kraapimine: kas see on lubatud?
Avalike Google Video tulemuste kraapimist peetakse üldiselt seaduslikuks. Siiski tuleb kindlasti rõhutada, et kehtivate eeskirjade ja reeglite range järgimine on hädavajalik. See tava võib olla kasulik metapealkirjade, videokirjelduste, URL-ide ja muu kogumisel teie konkreetsel kasutusjuhul. Sellegipoolest on enne ulatusliku andmete kogumise alustamist õiguseksperdiga konsulteerimine mõistlik valik.
Peamised meetodid Google'i otsingulehtede kraapimiseks
Google'i otsingulehtedelt andmete kogumiseks on teie käsutuses kaks peamist meetodit: URL-ipõhine ekstraktimine ja otsingupäringupõhine eraldamine. URL-ipõhine lähenemine hõlmab andmete hankimist Google'i otsingutulemuste lehelt kopeeritud URL-i abil, olgu see siis mis tahes riigi Google'i domeenist (nt google.co.uk). Teile meeldib paindlikult lisada nii palju URL-e, kui on teie eesmärkide saavutamiseks vaja.







Kommentaarid (0)
Siin pole veel kommentaare, võite olla esimene!