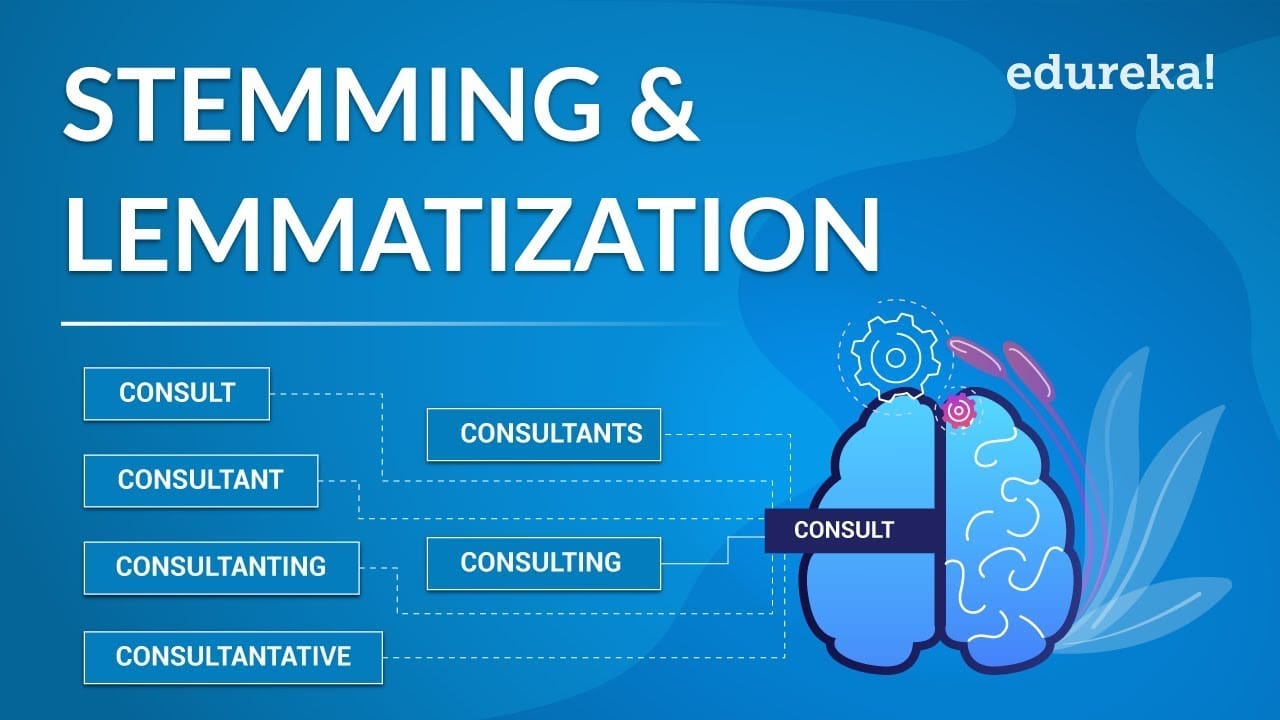
Stemming in Natural Language Processing is a text analysis technique used in computers and programming for the purposes of cybersecurity. It is used within a language processing system to reduce inflected (or sometimes derived) words to their word stem, base or root form. This is done by removing affixes which are otherwise attached to the stem of a word.
Stemming is primarily used in Computational Linguistics and Computer Science fields for the purposes of information retrieval and natural language processing tasks. By performing stemming, words with multiple morphological interpretations can be reduced to a single root form which can optimize texts for indexing and searching. For example, the words “laughing”, “laughed”, and “laughs” can all be reduced to the stem “laugh” to make results more relevant. Stemming is also used in sentiment analysis when determining the sentiment of a text by aggregating the sentiments of components to construct additional meaning.
Stemming algorithms are created depending on the language being used, as each language has its own rules for how to construct words. Each algorithm must account for grammar, morphology and syntactic nuances of the language in order to accurately parse words. For example, in the English language, the Porter Stemming algorithm has been used since 1980 as an efficient algorithm for reducing words to their stem form.
Overall, stemming in natural language processing is an important technique used in the field of computers, programming and cybersecurity. By reducing words to their stem form, efficiency in searching and accuracy in sentiment analysis is increased and more relevant understanding of data can be achieved.