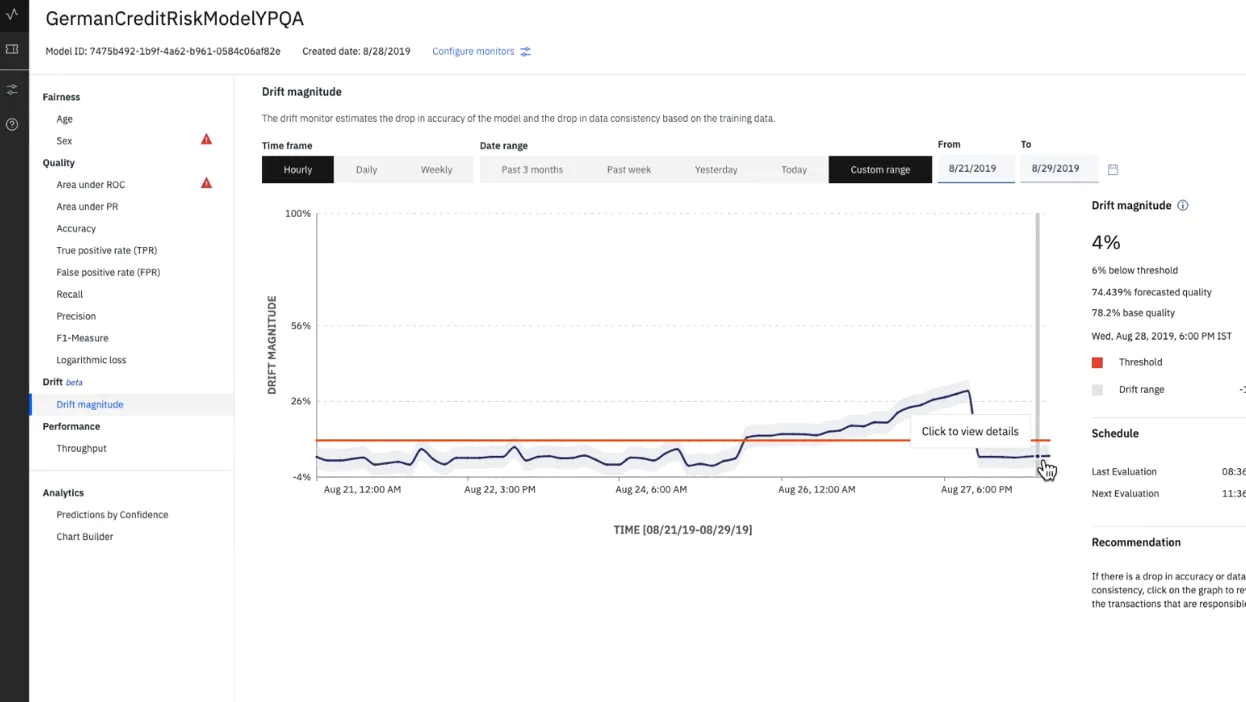
Model Drift (also known as concept drift, or data drift) is an important concept in machine learning and analytics. It refers to the process by which the predictive accuracy of an analytic model drops over time due to changing data and/or environment. The changing data and/or environment may come from a multitude of sources, including changing business needs, changing customer behaviors, or changing economic conditions.
Typically, when a model is first created, it performs well and is able to accurately predict outcomes against test data sets. However, as the environment surrounding the model changes, the model’s ability to accurately predict those outcomes begins to decrease. This is known as model drift. Model drift should therefore be monitored and managed in order to ensure the continued accuracy of a model’s predictions.
There are several strategies that can be employed to help mitigate model drift. These include data retraining, model validation, feature engineering, and data augmentation. In data retraining, the model is retrained with new, more up-to-date data in order to better match the changing environment. Model validation is the process of measuring a model’s performance against test data in order to identify any areas where its accuracy has decreased. Feature engineering involves the manipulation of the data set’s features in order to produce results more in line with the underlying data. Lastly, data augmentation involves the addition of new data points to a data set in order to improve a model’s performance.
Model drift is an important concept to consider when designing and maintaining machine learning models. By closely monitoring and managing model drift, organizations can ensure that their models are always working at peak accuracy.