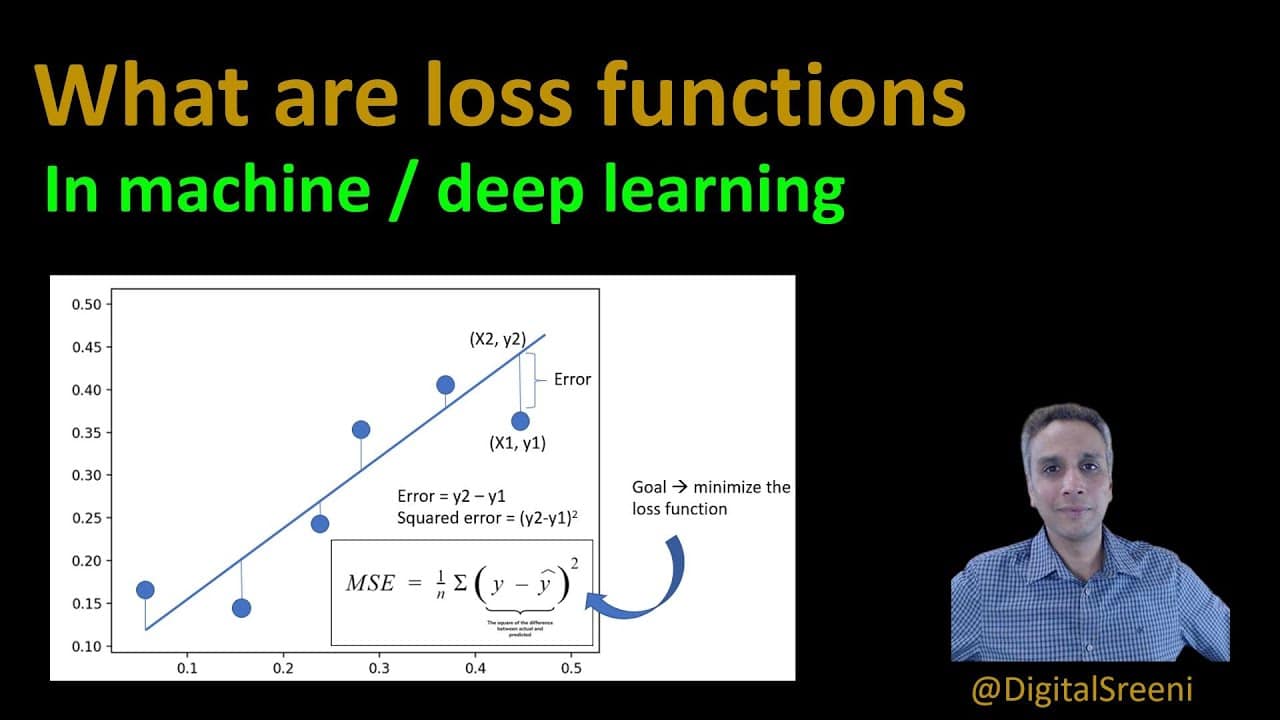
Loss functions, also known as cost functions, are mathematical equations that measure the performance of a machine learning algorithm. The loss function is typically written as a function of the algorithm’s predicted output and the actual desired output. The loss function calculates the amount of error, or “loss”, for each prediction.
Typically, the goal of the machine learning algorithm is to minimize the loss function in order to achieve a more accurate prediction. In order to achieve this, the current predicted output must be adjusted based on the difference between the predicted and desired output. This process of adjusting the predicted output for each iteration is known as gradient descent, and is a common optimization technique used in machine learning.
The type of loss function chosen for a particular machine learning algorithm depends on the problem being solved. For example, regression tasks require a different loss function than classification tasks. Commonly used loss functions include mean squared error, cross-entropy, and hinge loss.
The use of loss function in machine learning algorithms is a powerful tool for adjusting the machine’s predictions to more accurately reflect reality. Careful selection and tuning of the loss function is essential for achieving optimal performance by the machine learning algorithm.