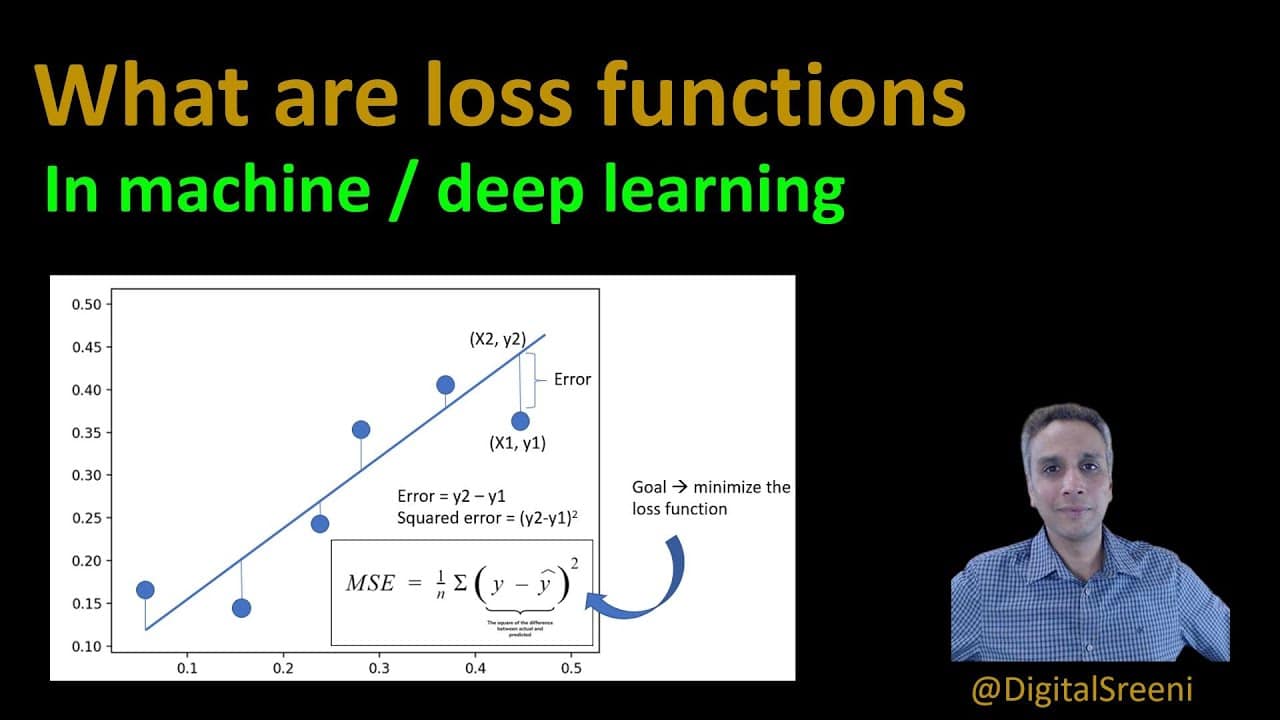
Les fonctions de perte, également appelées fonctions de coût, sont des équations mathématiques qui mesurent les performances d'un algorithme d'apprentissage automatique. La fonction de perte s'écrit généralement comme une fonction de la sortie prédite par l'algorithme et de la sortie réelle souhaitée. La fonction de perte calcule le montant de l'erreur, ou "perte", pour chaque prédiction.
En règle générale, l'objectif de l'algorithme d'apprentissage automatique est de minimiser la fonction de perte afin d'obtenir une prédiction plus précise. Pour ce faire, la sortie prédite actuelle doit être ajustée en fonction de la différence entre la sortie prédite et la sortie souhaitée. Ce processus d'ajustement de la sortie prédite à chaque itération est connu sous le nom de descente de gradient et constitue une technique d'optimisation couramment utilisée dans l'apprentissage automatique.
Le type de fonction de perte choisi pour un algorithme d'apprentissage automatique particulier dépend du problème à résoudre. Par exemple, les tâches de régression nécessitent une fonction de perte différente des tâches de classification. Les fonctions de perte couramment utilisées sont l'erreur quadratique moyenne, l'entropie croisée et la perte de charnière.
L'utilisation de la fonction de perte dans les algorithmes d'apprentissage automatique est un outil puissant qui permet d'ajuster les prédictions de la machine pour qu'elles reflètent plus précisément la réalité. Une sélection et un réglage minutieux de la fonction de perte sont essentiels pour obtenir des performances optimales de l'algorithme d'apprentissage automatique.