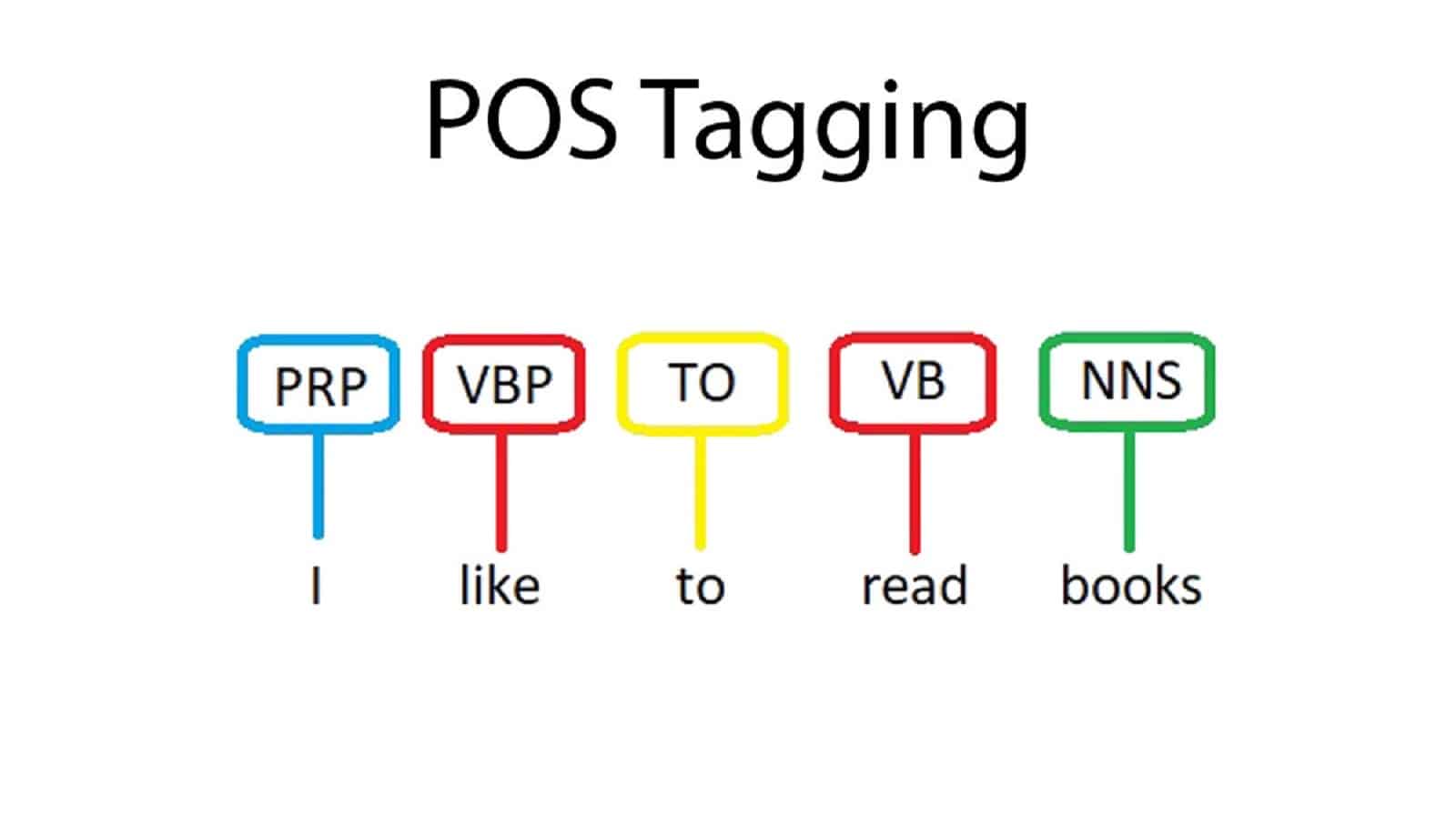
A marcação de parte da fala (POS) é um processo de atribuição de uma parte da fala a cada palavra em um determinado texto. Esse processo é necessário para o processamento de linguagem natural, pois ajuda o computador a entender a estrutura de uma frase e como as diferentes palavras se relacionam entre si. A marcação de POS fornece a base para tarefas mais sofisticadas, como análise de sintaxe e análise semântica.
A marcação de parte da fala também é conhecida como desambiguação de categoria de palavras. É um tipo de técnica de análise de texto que identifica palavras em um texto e atribui uma tag de parte do discurso a cada palavra. As partes do discurso que podem ser identificadas por esse método incluem substantivos, verbos, adjetivos, advérbios, pronomes, preposições, conjunções, interjeições e outras formas de discurso. Há vários algoritmos comumente usados na marcação de POS, incluindo métodos baseados em regras, métodos estatísticos e técnicas de aprendizado de máquina.
Os métodos baseados em regras examinam um texto aplicando regras linguísticas. Essas regras são baseadas na gramática do idioma que está sendo processado. Os métodos estatísticos usam um corpus de dados pré-marcados para identificar padrões entre palavras e tags. As técnicas de aprendizado de máquina são usadas para treinar um sistema para reconhecer padrões em um corpus sem tags e, em seguida, atribuir a tag correta para cada palavra.
A marcação de POS é um processo essencial para o processamento de linguagem natural. Ele é usado para identificar o significado semântico das palavras em um texto e ajuda a criar dados estruturados que podem ser usados posteriormente para criar uma melhor compreensão do texto. Esse processo é usado na área de programação de computadores, especialmente para tradução automática, resumo de texto e sistemas de diálogo. Além disso, ele pode ser usado no campo da segurança cibernética para examinar textos da Web ou determinar o sentimento de uma conversa on-line.
Em geral, a marcação de parte da fala (POS) é um processo usado para identificar com precisão as palavras em um texto e atribuir a elas uma tag de parte da fala. Esse processo é essencial para o processamento de linguagem natural e é utilizado em uma ampla variedade de aplicativos de computador, como tradução automática, resumo de texto, sistemas de diálogo e segurança cibernética.