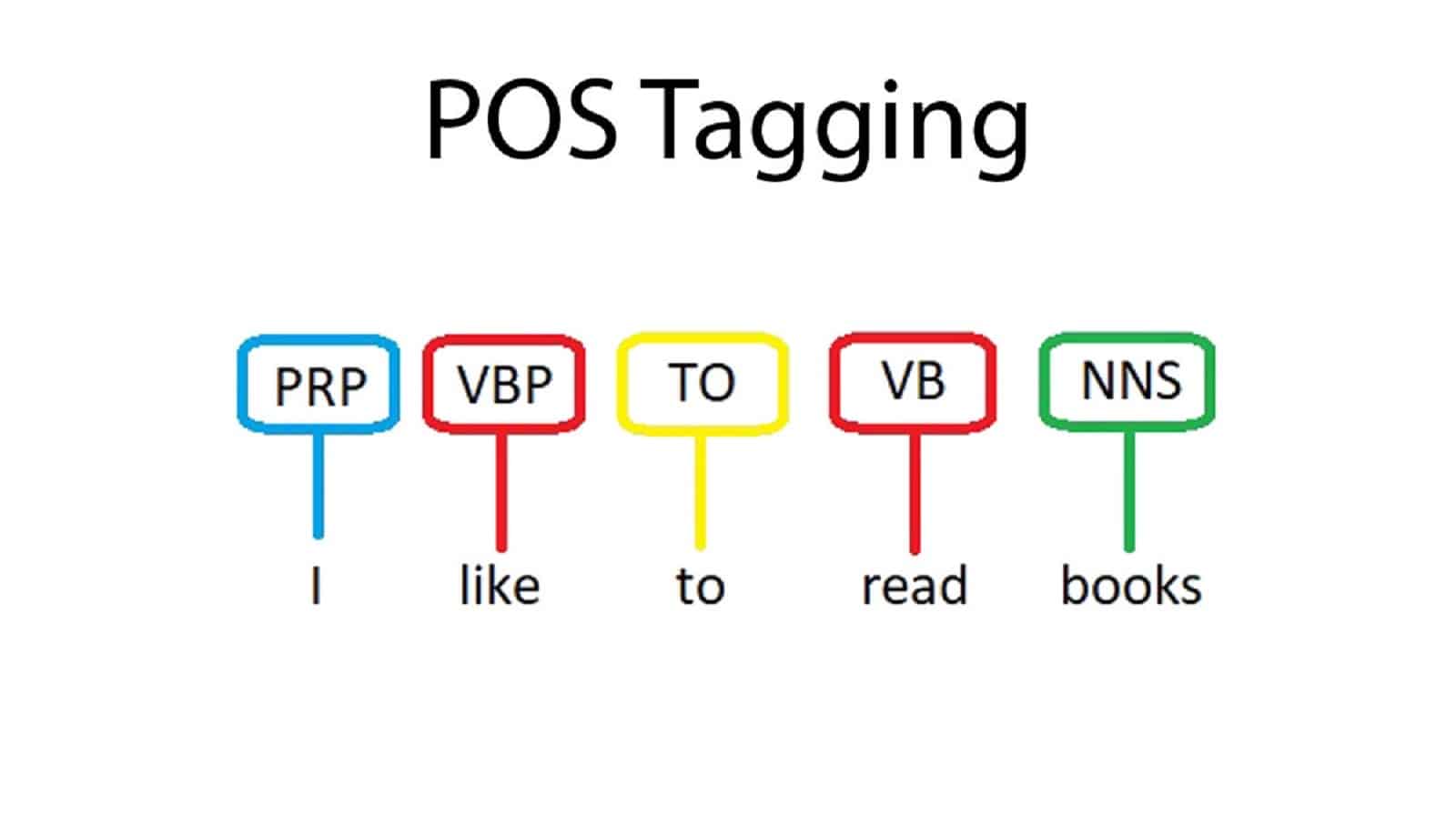
Tagowanie części mowy (POS) to proces przypisywania części mowy do każdego słowa w danym tekście. Proces ten jest niezbędny do przetwarzania języka naturalnego, ponieważ pomaga komputerowi zrozumieć strukturę zdania i sposób, w jaki różne słowa odnoszą się do siebie nawzajem. Tagowanie POS stanowi podstawę dla bardziej zaawansowanych zadań, takich jak analiza składni i analiza semantyczna.
Tagowanie części mowy jest również znane jako ujednoznacznienie kategorii słów. Jest to rodzaj techniki analizy tekstu, która identyfikuje słowa w tekście i przypisuje znacznik części mowy do każdego słowa. Części mowy, które można zidentyfikować za pomocą tej metody, obejmują rzeczowniki, czasowniki, przymiotniki, przysłówki, zaimki, przyimki, spójniki, wtrącenia i inne formy mowy. Istnieje kilka algorytmów powszechnie stosowanych w tagowaniu POS, w tym metody oparte na regułach, metody statystyczne i techniki uczenia maszynowego.
Metody oparte na regułach badają tekst poprzez zastosowanie reguł językowych. Reguły te opierają się na gramatyce przetwarzanego języka. Metody statystyczne wykorzystują korpus wstępnie oznaczonych danych do identyfikacji wzorców między słowami i tagami. Techniki uczenia maszynowego są wykorzystywane do szkolenia systemu w celu rozpoznawania wzorców w nieoznakowanym korpusie, a następnie przypisywania prawidłowego tagu dla każdego słowa.
Tagowanie POS jest niezbędnym procesem przetwarzania języka naturalnego. Służy do identyfikacji semantycznego znaczenia słów w tekście i pomaga tworzyć ustrukturyzowane dane, które mogą być dalej wykorzystywane do lepszego zrozumienia tekstu. Proces ten jest wykorzystywany w dziedzinie programowania komputerowego, w szczególności do tłumaczenia maszynowego, podsumowywania tekstu i systemów dialogowych. Ponadto może być stosowany w dziedzinie cyberbezpieczeństwa do skanowania tekstu internetowego lub określania nastrojów konwersacji online.
Ogólnie rzecz biorąc, tagowanie części mowy (POS) jest procesem używanym do dokładnej identyfikacji słów w tekście i przypisania im tagu części mowy. Proces ten jest niezbędny do przetwarzania języka naturalnego i jest wykorzystywany w wielu różnych aplikacjach komputerowych, takich jak tłumaczenie maszynowe, podsumowywanie tekstu, systemy dialogowe i cyberbezpieczeństwo.