
दुनिया के सबसे बड़े खोज इंजन के रूप में Google के पास बहुमूल्य जानकारी का विशाल खजाना है। फिर भी, जब Google खोज परिणामों को स्वचालित रूप से और बड़े पैमाने पर परिमार्जन करने की आवश्यकता आती है, तो आपको कुछ चुनौतियों का सामना करना पड़ सकता है। इस लेख में, हम इन चुनौतियों की प्रकृति पर गहराई से विचार करेंगे, उन्हें दूर करने के लिए रणनीतियों का पता लगाएंगे, और बड़े पैमाने पर Google खोज परिणामों को सफलतापूर्वक निकालने में आपका मार्गदर्शन करेंगे।
Google खोज परिणामों को स्क्रैप करने के बारे में किसी भी बातचीत में, आपको "SERP" का संक्षिप्त नाम मिलने की संभावना है, जो खोज इंजन परिणाम पृष्ठ के लिए है। यह वह पृष्ठ है जो खोज बार में कोई प्रश्न दर्ज करने के बाद आपका स्वागत करता है। वे दिन गए जब Google केवल लिंक की एक सूची प्रस्तुत करता था; आज के SERPs आपके खोज अनुभव को बढ़ाने के लिए डिज़ाइन की गई सुविधाओं और तत्वों का एक गतिशील मिश्रण हैं। नेविगेट करने के लिए अनेक घटकों के साथ, आइए प्रमुख घटकों पर ध्यान केंद्रित करें।
1. विशेष रुप से प्रदर्शित स्निपेट्स
2. विज्ञापन
3. वीडियो हिंडोला
4. लोग पूछते भी हैं
5. स्थानीय पैक
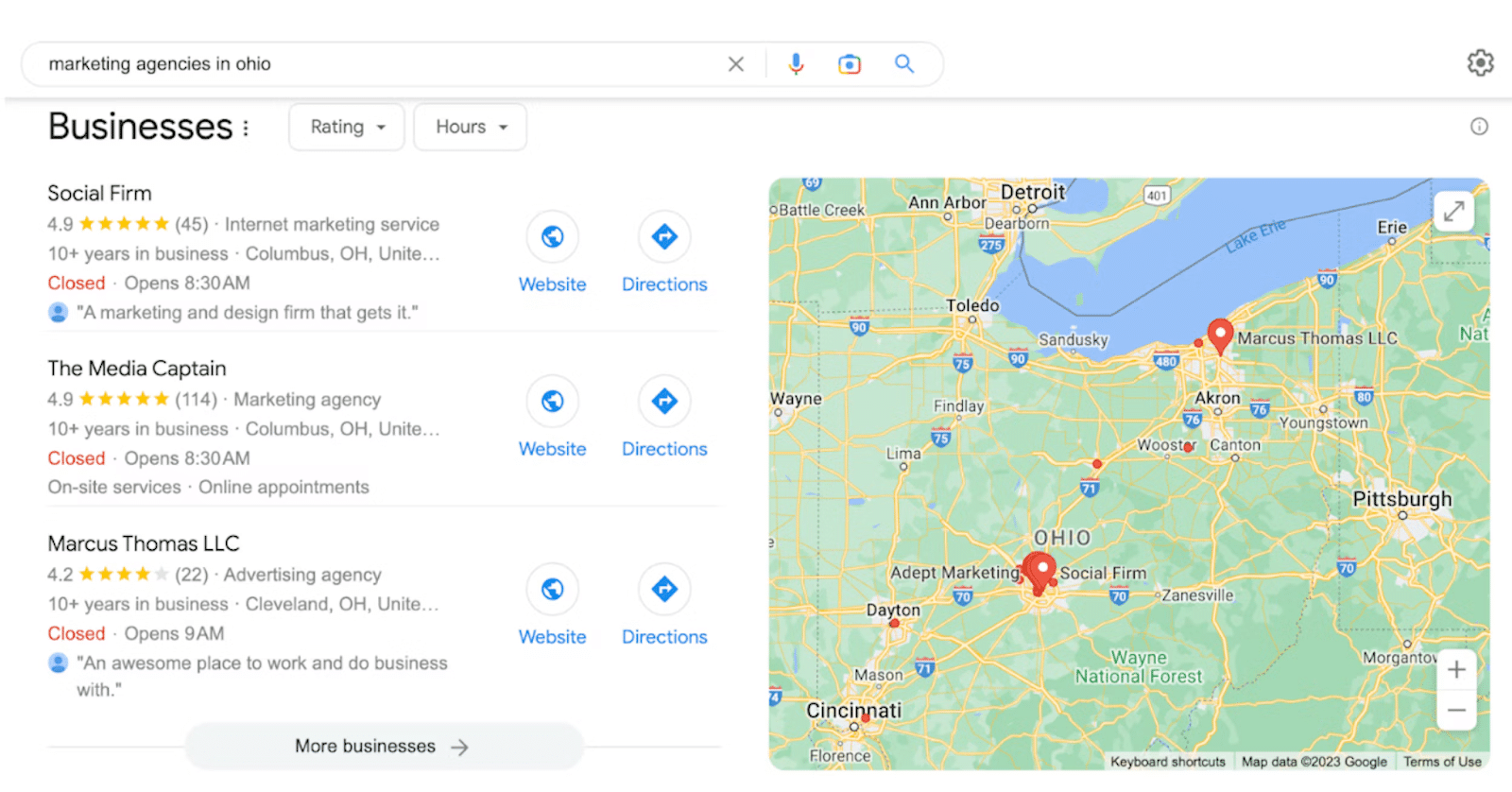
6. संबंधित खोजें
Google परिणामों को स्क्रैप करने की वैधता
यह प्रश्न कि क्या Google खोज डेटा को स्क्रैप करना कानूनी है, वेब स्क्रैपिंग डोमेन में एक सामान्य विषय है। संक्षेप में, Google SERP डेटा सहित इंटरनेट पर सार्वजनिक रूप से सुलभ डेटा को स्क्रैप करना आम तौर पर कानूनी माना जाता है। हालाँकि, विशिष्ट परिस्थितियों के आधार पर वैधता भिन्न हो सकती है, जिससे आपकी विशिष्ट स्थिति के अनुरूप कानूनी सलाह लेने की सलाह दी जाती है।
Google खोज परिणामों को स्क्रैप करने में चुनौतियाँ
जैसा कि पहले उल्लेख किया गया है, Google खोज परिणाम डेटा को स्क्रैप करना कठिन चुनौतियाँ प्रस्तुत करता है। Google दुर्भावनापूर्ण बॉट्स को अपना डेटा एकत्र करने से रोकने के लिए विभिन्न तंत्रों का उपयोग करता है, जिससे वेब स्क्रैपर्स के लिए एक जटिल परिदृश्य बन जाता है। प्राथमिक मुद्दा दुर्भावनापूर्ण बॉट और सौम्य बॉट के बीच अंतर करने में कठिनाई से उत्पन्न होता है, जिसके परिणामस्वरूप अक्सर वैध स्क्रैपर्स को चिह्नित या प्रतिबंधित कर दिया जाता है।
गहरी समझ हासिल करने के लिए, आइए सार्वजनिक Google खोज परिणामों को खंगालते समय सामने आने वाली विशिष्ट चुनौतियों पर गौर करें:
- कैप्चा
Google कैप्चा को वास्तविक उपयोगकर्ताओं और स्वचालित बॉट के बीच अंतर करने के साधन के रूप में तैनात करता है। ये परीक्षण जानबूझकर बॉट्स के लिए चुनौतीपूर्ण होने के लिए डिज़ाइन किए गए हैं लेकिन मनुष्यों के लिए इन्हें पूरा करना अपेक्षाकृत सरल है। यदि कोई विज़िटर कई प्रयासों के बाद कैप्चा को हल करने में विफल रहता है, तो यह आईपी ब्लॉक को ट्रिगर कर सकता है। सौभाग्य से, हमारे SERP स्क्रैपर एपीआई जैसे उन्नत वेब स्क्रैपिंग टूल आईपी ब्लॉक का सामना किए बिना कैप्चा को संभालने के लिए अच्छी तरह से सुसज्जित हैं।
- आईपी ब्लॉक
जब भी आप ऑनलाइन गतिविधियों में संलग्न होते हैं, तो आपका आईपी पता उन वेबसाइटों के सामने आ जाता है, जिनमें Google SERP डेटा या अन्य वेबसाइटों से डेटा स्क्रैप करना शामिल है। वेब स्क्रैपिंग करते समय, आपकी स्क्रिप्ट पर्याप्त मात्रा में अनुरोध उत्पन्न करती है। यह बढ़ी हुई गतिविधि वेबसाइट के अंत में संदेह पैदा कर सकती है, जिससे संभावित रूप से आईपी प्रतिबंध लग सकता है, जो प्रभावी रूप से साइट तक पहुंच को प्रतिबंधित करता है।
- अव्यवस्थित डेटा
Google से बड़े पैमाने पर डेटा एकत्र करने का मुख्य उद्देश्य गहन विश्लेषण करना और मूल्यवान अंतर्दृष्टि प्राप्त करना है। यह डेटा अक्सर एक मजबूत खोज इंजन अनुकूलन (एसईओ) रणनीति तैयार करने जैसे आवश्यक कार्यों के लिए आधार के रूप में कार्य करता है। प्रभावी विश्लेषण की सुविधा के लिए, पुनर्प्राप्त किया गया डेटा अच्छी तरह से संरचित और आसानी से समझने योग्य होना चाहिए। इसके लिए आपके डेटा-एकत्रित उपकरण को JSON या CSV जैसे संगठित प्रारूप में जानकारी लौटाने की क्षमता की आवश्यकता होती है।
इन चुनौतियों के आलोक में, उन्हें प्रभावी ढंग से दूर करने के लिए एक उन्नत वेब स्क्रैपिंग समाधान अपरिहार्य है। Fineproxy Google Search API को Google द्वारा कार्यान्वित तकनीकी बाधाओं को नेविगेट करने और बायपास करने के लिए विशेषज्ञ रूप से डिज़ाइन किया गया है। यह सार्वजनिक Google खोज परिणामों तक निर्बाध पहुंच प्रदान करता है, जिससे उपयोगकर्ता की ओर से स्क्रैपर रखरखाव की आवश्यकता समाप्त हो जाती है।
वास्तव में, हमारे SERP एपीआई के साथ खोज परिणामों को स्क्रैप करने की प्रक्रिया सीधी और कुशल दोनों है। आइए इस प्रक्रिया को अधिक विस्तार से जानें। यदि आपकी Google शॉपिंग परिणामों को स्क्रैप करने में विशेष रुचि है, तो हम आपको अंतर्दृष्टि और मार्गदर्शन के लिए हमारी अन्य मार्गदर्शिका देखने के लिए प्रोत्साहित करते हैं।
एपीआई का उपयोग करके पायथन के साथ सार्वजनिक Google खोज परिणामों को स्क्रैप करना
इंटरनेट से डेटा एकत्र करने के लिए वेब स्क्रैपिंग एक मूल्यवान तकनीक है, और Google खोज परिणाम जानकारी का एक प्रमुख स्रोत हैं। हालाँकि, स्वचालित बॉट्स को रोकने के लिए Google द्वारा लागू किए गए उपायों के कारण Google खोज परिणामों को बड़े पैमाने पर स्क्रैप करना एक चुनौतीपूर्ण प्रयास हो सकता है। इस गाइड में, हम यह पता लगाएंगे कि पायथन और एपीआई का उपयोग करके सार्वजनिक Google खोज परिणामों को कैसे स्क्रैप किया जाए, जिससे आप पारंपरिक वेब स्क्रैपिंग विधियों से जुड़ी जटिलताओं और सीमाओं को दूर कर सकें।
1. अपना वातावरण स्थापित करें:
इससे पहले कि आप Google खोज परिणामों को खंगालना शुरू करें, सुनिश्चित करें कि आपके पास आवश्यक उपकरण और लाइब्रेरी स्थापित हैं। आपको अपने सिस्टम पर पायथन स्थापित करने की आवश्यकता होगी, साथ ही अनुरोध और json लाइब्रेरी भी। इसके अतिरिक्त, आपको Google खोज परिणामों तक पहुंचने के लिए एक एपीआई कुंजी की आवश्यकता होगी। एपीआई कुंजी प्राप्त करने के लिए, Google डेवलपर्स कंसोल पर एक प्रोजेक्ट बनाने के लिए Google के दिशानिर्देशों का पालन करें।
आयात अनुरोध
json आयात करें
# 'YOUR_API_KEY' को अपनी वास्तविक API कुंजी से बदलें
API_KEY = 'आपका_API_KEY'
# समापन बिंदु URL को परिभाषित करें
ENDPOINT_URL = 'https://www.googleapis.com/customsearch/v1'
# पैरामीटर सेट करें
search_query = 'आपकी खोज क्वेरी यहां है'
search_engine_id = 'आपकी खोज इंजन आईडी यहां है'
# अनुरोध URL बनाएं
पैरामीटर = {
'कुंजी': API_KEY,
'सीएक्स': search_engine_id,
'क्यू': search_query
}
2. एपीआई अनुरोध करें:
अपने परिवेश की स्थापना के साथ, अब आप Google खोज परिणाम लाने के लिए एपीआई अनुरोध कर सकते हैं। आपको Google के कस्टम सर्च JSON API पर एक GET अनुरोध भेजना होगा और प्रतिक्रिया संसाधित करनी होगी।
# एपीआई को एक GET अनुरोध भेजें
प्रतिक्रिया = request.get(ENDPOINT_URL, पैरामीटर=पैराम्स)
# प्रतिक्रिया को JSON के रूप में पार्स करें
डेटा = प्रतिक्रिया.json()
# जाँचें कि क्या अनुरोध सफल हुआ
यदि डेटा में 'आइटम':
search_results = डेटा['आइटम']
# आवश्यकतानुसार खोज परिणामों को संसाधित करें और उनका उपयोग करें
search_results में परिणाम के लिए:
शीर्षक = परिणाम['शीर्षक']
लिंक = परिणाम['लिंक']
स्निपेट = परिणाम['स्निपेट']
# डेटा के साथ अपने इच्छित कार्य निष्पादित करें
प्रिंट(f'शीर्षक: {शीर्षक}')
प्रिंट(f'लिंक: {लिंक}')
प्रिंट(f'स्निपेट: {स्निपेट}')
अन्य:
# त्रुटियों या कोई खोज परिणाम न मिलने को संभालें
प्रिंट करें ('कोई खोज परिणाम नहीं मिला या कोई त्रुटि हुई।')
3. दर सीमाएँ संभालें:
Google के एपीआई में दर सीमाएं हैं, जो एक विशिष्ट समय सीमा के भीतर आपके द्वारा किए जा सकने वाले अनुरोधों की संख्या को प्रभावित कर सकती हैं। सुनिश्चित करें कि आपकी स्क्रैपिंग प्रक्रिया इन दर सीमाओं का पालन करती है। इन सीमाओं से बचने के लिए अनुरोधों और HTTP 429 प्रतिक्रियाएँ प्राप्त करने के बीच विलंब लागू करने पर विचार करें।
4. डाटा प्रोसेसिंग और भंडारण:
Google खोज परिणाम पुनर्प्राप्त करने के बाद, आप अपने विशिष्ट उपयोग के मामले के लिए आवश्यकतानुसार डेटा को संसाधित और संग्रहीत कर सकते हैं। इसमें परिणामों को स्थानीय फ़ाइल, डेटाबेस में सहेजना या वास्तविक समय विश्लेषण करना शामिल हो सकता है।
5. Google की सेवा की शर्तों का सम्मान करें:
Google के खोज परिणामों को खंगालते समय उसकी सेवा की शर्तों का पालन करना आवश्यक है। सुनिश्चित करें कि डेटा का आपका उपयोग उनकी नीतियों के अनुरूप है और Google खोज परिणाम प्रदर्शित करते समय उचित एट्रिब्यूशन शामिल करने पर विचार करें।
संक्षेप में, पारंपरिक वेब स्क्रैपिंग विधियों की तुलना में पायथन और एपीआई का उपयोग करके सार्वजनिक Google खोज परिणामों को स्क्रैप करना अधिक कुशल और विश्वसनीय दृष्टिकोण है। सही एपीआई कुंजी और कोड के साथ, आप विभिन्न उद्देश्यों, जैसे बाजार अनुसंधान, एसईओ विश्लेषण, या सामग्री निर्माण के लिए Google से मूल्यवान डेटा एकत्र कर सकते हैं।
सामान्य प्रश्न
क्या वेब स्क्रैपिंग Google की अनुमति है?
जब Google को स्क्रैप करने की बात आती है, तो आप कानूनी पहलुओं के बारे में आश्चर्यचकित हो सकते हैं। Google खोज परिणाम, एक सामान्य नियम के रूप में, सार्वजनिक रूप से उपलब्ध डेटा माने जाते हैं, जिससे उन्हें स्क्रैप करना स्वीकार्य हो जाता है। हालाँकि, मुख्य रूप से व्यक्तिगत जानकारी और कॉपीराइट सामग्री से संबंधित प्रतिबंध हैं। अनुपालन सुनिश्चित करने के लिए, पहले से किसी कानूनी पेशेवर से परामर्श करना उचित है।
क्या आप Google ईवेंट डेटा को स्क्रैप कर सकते हैं?
निश्चित रूप से, आप दुनिया भर में संगीत समारोहों, त्योहारों, प्रदर्शनियों और समारोहों जैसी घटना-संबंधित जानकारी के लिए Google को खंगाल सकते हैं। ईवेंट-विशिष्ट कीवर्ड इनपुट करके, आप खोज इंजन परिणाम पृष्ठ पर ईवेंट की एक पूरक तालिका देखेंगे, जिसमें स्थान, ईवेंट शीर्षक, फ़ीचर्ड बैंड या कलाकार और तिथियां जैसे विवरण प्रदान किए जाएंगे। इस सार्वजनिक डेटा को खंगालना संभव है। फिर भी, इस बात पर ज़ोर देना ज़रूरी है कि Google से डेटा निकालना सभी प्रासंगिक नियमों के अनुपालन में किया जाना चाहिए। कानूनी सलाह लेना समझदारी है, खासकर जब बड़े पैमाने पर डेटा संग्रह से निपटना हो।
क्या Google स्थानीय परिणामों को स्क्रैप करने की अनुमति है?
Google इष्टतम खोज परिणाम देने के लिए प्रासंगिकता और निकटता मापदंडों का मिश्रण नियोजित करता है। उदाहरण के लिए, स्थानीय कॉफी स्थानों की खोज करते समय, Google निकटता में विकल्प प्रस्तुत करता है और यहां तक कि दिशा-निर्देश भी प्रदान करता है। इन विशिष्ट खोज परिणामों को Google स्थानीय परिणामों के रूप में वर्गीकृत किया गया है और ये Google मानचित्र परिणामों से भिन्न हैं, जो नेविगेशन पर ध्यान केंद्रित करते हैं। बशर्ते आप प्रासंगिक नियमों का पालन करें, आप वास्तव में अपने प्रोजेक्ट के लिए सार्वजनिक Google स्थानीय परिणाम प्राप्त कर सकते हैं। उचित अनुपालन सुनिश्चित करने के लिए कानूनी विशेषज्ञ से सलाह लेने की अनुशंसा की जाती है।
क्या आप "इस परिणाम के बारे में" अनुभाग से जानकारी निकाल सकते हैं?
Google किसी वेबसाइट के बारे में अतिरिक्त जानकारी प्रदान करता है जहां खोज परिणाम के दाईं ओर आसन्न तीन बिंदुओं पर क्लिक करके खोज परिणाम स्थित होता है। आप निश्चित रूप से सार्वजनिक रूप से उपलब्ध इस डेटा को खंगाल सकते हैं, लेकिन लागू नियमों और विनियमों का सख्ती से पालन करना महत्वपूर्ण है। विशेष रूप से व्यापक डेटा निष्कर्षण पर विचार करते समय, कानूनी पेशेवर से परामर्श करना एक विवेकपूर्ण कदम है।
Google वीडियो परिणामों को स्क्रैप करना: क्या इसकी अनुमति है?
सार्वजनिक Google वीडियो परिणामों को स्क्रैप करना आम तौर पर कानूनी माना जाता है। हालाँकि, इस बात पर ज़ोर देना अनिवार्य है कि प्रचलित नियमों और नियमों का कड़ाई से पालन आवश्यक है। यह अभ्यास आपके विशिष्ट उपयोग के मामले में मेटा शीर्षक, वीडियो विवरण, यूआरएल और बहुत कुछ जमा करने के लिए फायदेमंद हो सकता है। फिर भी, व्यापक डेटा संग्रह शुरू करने से पहले, कानूनी विशेषज्ञ से परामर्श करना एक अच्छा विकल्प है।
Google खोज पृष्ठों को स्क्रैप करने की प्राथमिक विधियाँ
Google खोज पृष्ठों से डेटा एकत्र करने के लिए, आपके पास दो प्राथमिक विधियाँ हैं: URL-आधारित निष्कर्षण और खोज क्वेरी-आधारित निष्कर्षण। यूआरएल-आधारित दृष्टिकोण में कॉपी किए गए यूआरएल का उपयोग करके Google खोज परिणाम पृष्ठ से डेटा प्राप्त करना शामिल है, चाहे वह किसी भी देश के Google डोमेन से हो (उदाहरण के लिए, google.co.uk)। आप अपने उद्देश्यों को पूरा करने के लिए आवश्यकतानुसार अधिक से अधिक यूआरएल शामिल करने के लचीलेपन का आनंद लेते हैं।







टिप्पणियाँ (0)
यहां अभी तक कोई टिप्पणी नहीं है, आप पहले हो सकते हैं!