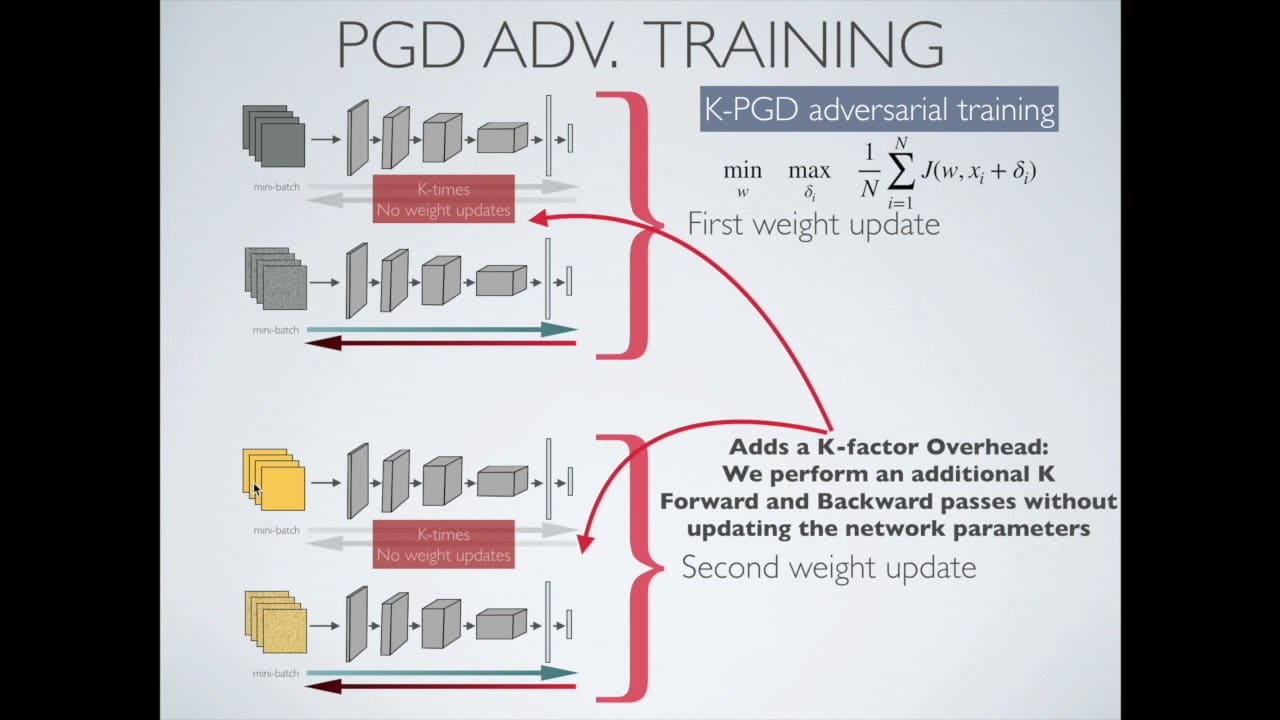
O treinamento contraditório é uma abordagem ao aprendizado de máquina que busca aumentar a robustez do modelo, armando-o com a capacidade de se defender contra ataques. É uma forma de aumento de dados que introduz uma forma de ruído artificial nos dados de treinamento. Esse ruído pode ser gerado por algoritmos ou simplesmente pela adição de pequenas perturbações às amostras de entrada.
O objetivo do treinamento contraditório é tornar o desempenho do modelo mais robusto a determinados tipos de ataque. Por exemplo, adicionar pequenas perturbações aos dados de entrada pode tornar o modelo menos sensível a determinados tipos de ataque. Em princípio, isso é semelhante ao conceito de regularização, no qual o modelo é treinado para ter menos dependência de recursos específicos.
O treinamento contraditório pode ajudar a reduzir o risco de sobreajuste, pois os dados ruidosos incentivam o modelo a generalizar com mais eficiência. Ele também pode ser usado para aumentar a precisão do modelo em novos conjuntos de dados, pois a robustez ao ataque melhora seu desempenho.
O treinamento contraditório também pode ajudar a melhorar a segurança do próprio modelo, pois ele tem um grau mais alto de resistência a determinados ataques. Isso o torna menos vulnerável à manipulação ou envenenamento dos dados de treinamento, por exemplo, o que pode resultar em desempenho ruim.
O treinamento contraditório é comumente usado para melhorar o desempenho e a segurança dos modelos de aprendizagem profunda. Ele tem sido usado para aumentar a precisão e a robustez das abordagens orientadas por dados para a segurança cibernética, como a detecção de anomalias e a prevenção de intrusões na rede.