Rừng cách ly (còn được gọi là iForest) là một thuật toán phát hiện điểm bất thường được phát triển bởi Fei Tony Liu, Kai Ming Ting và Zhi-Hua Zhou vào năm 2008. Thuật toán này sử dụng các mô hình dựa trên cây để xác định các điểm bất thường hoặc ngoại lệ trong tập dữ liệu. Loại mô hình này giúp phân tích hành vi của dữ liệu được quan sát để tạo ra các lớp bình thường và bất thường. Isolation Forest chủ yếu được sử dụng để phát hiện dữ liệu gian lận trong một tập dữ liệu lớn và xác định hoạt động của người dùng có thể là dấu hiệu của cuộc tấn công hoặc mục đích xấu.
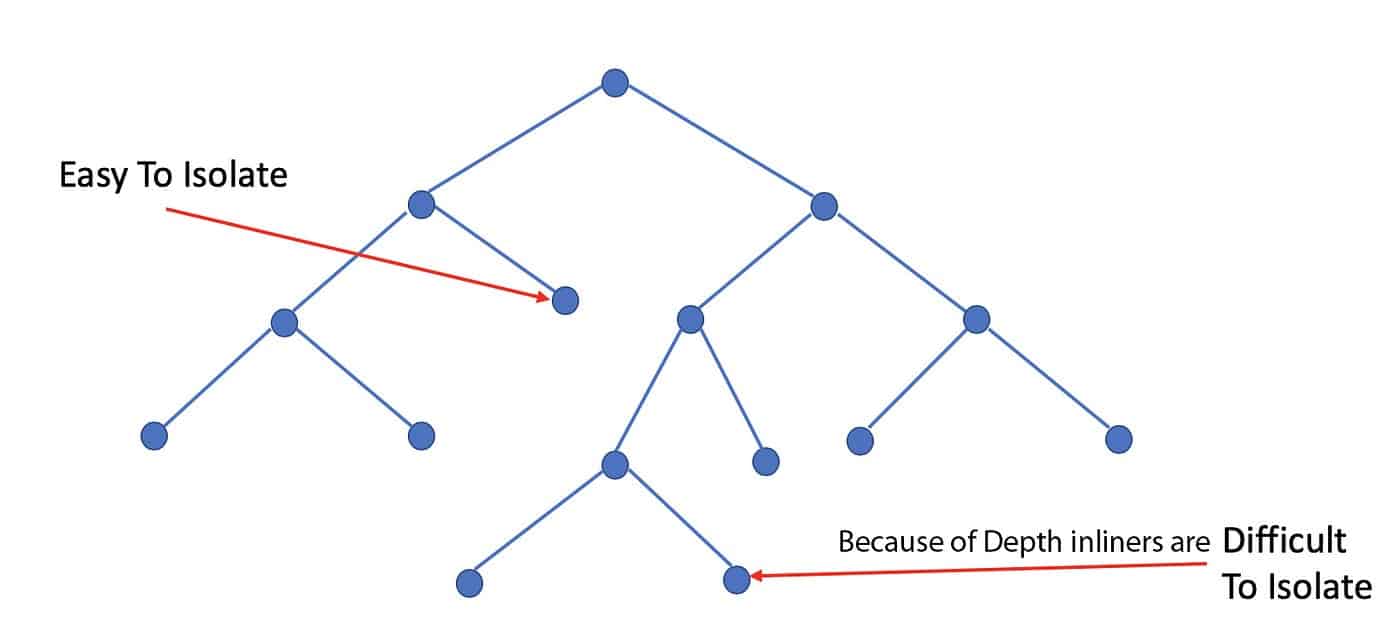
Thuật toán Rừng cách ly hoạt động bằng cách phân tách và cô lập ngẫu nhiên các điểm dữ liệu trong tập dữ liệu. Nó thực hiện điều này bằng cách tạo các nhóm nút và cô lập chúng dựa trên thuộc tính của chúng. Các thuộc tính này có thể là giá trị dự đoán, giá trị phân loại, giá trị boolean hoặc bất kỳ loại dữ liệu nào khác. Sau đó, thuật toán sẽ gán điểm cho các điểm dữ liệu bị cô lập. Điểm cao hơn cho thấy điểm dữ liệu có điểm bất thường.
Khi các điểm bất thường đã được xác định, có thể điều tra thêm các điểm dữ liệu được đề cập. Điều này giúp người dùng hiểu rõ hơn những đặc điểm nào khiến điểm dữ liệu cụ thể đó trở nên bất thường. Hơn nữa, nó có thể giúp xác định hoạt động của người dùng có thể là dấu hiệu của sự tấn công hoặc mục đích xấu.
Không giống như nhiều phương pháp học máy khác, Rừng cách ly không yêu cầu làm sạch và xử lý trước tập dữ liệu. Điều này làm cho nó trở thành một công cụ hữu ích để phát hiện nhanh chóng và đáng tin cậy các điểm bất thường trong các tập dữ liệu lớn có thể chưa được làm sạch hoàn toàn. Ngoài ra, nó không đòi hỏi sự hiểu biết sâu sắc về cấu trúc dữ liệu; thay vào đó, nó sử dụng một thuật toán đơn giản có thể được áp dụng trực tiếp vào tập dữ liệu.
Rừng cách ly có thể được áp dụng cho nhiều loại bộ dữ liệu, bao gồm hồ sơ tài chính, hồ sơ y tế, nhật ký hoạt động của người dùng và lưu lượng truy cập mạng. Nó là một công cụ có giá trị để khai thác dữ liệu và phát hiện sự bất thường vì nó có thể xác định các mẫu và hành vi có thể không rõ ràng khi xem xét dữ liệu một cách riêng biệt. Ngoài ra, thuật toán này giúp giảm số lượng kết quả dương tính giả khi phát hiện điểm bất thường.