Isolation Forest (también conocido como iForest) es un algoritmo para la detección de anomalías desarrollado por Fei Tony Liu, Kai Ming Ting y Zhi-Hua Zhou en 2008. Utiliza modelos basados en árboles para identificar anomalías o valores atípicos en un conjunto de datos. Este tipo de modelo ayuda a analizar el comportamiento de los datos observados para generar las clases normales y anómalas. Isolation Forest se utiliza principalmente para detectar datos fraudulentos dentro de un gran conjunto de datos y para identificar la actividad de los usuarios que pueda ser indicativa de ataque o intención maliciosa.
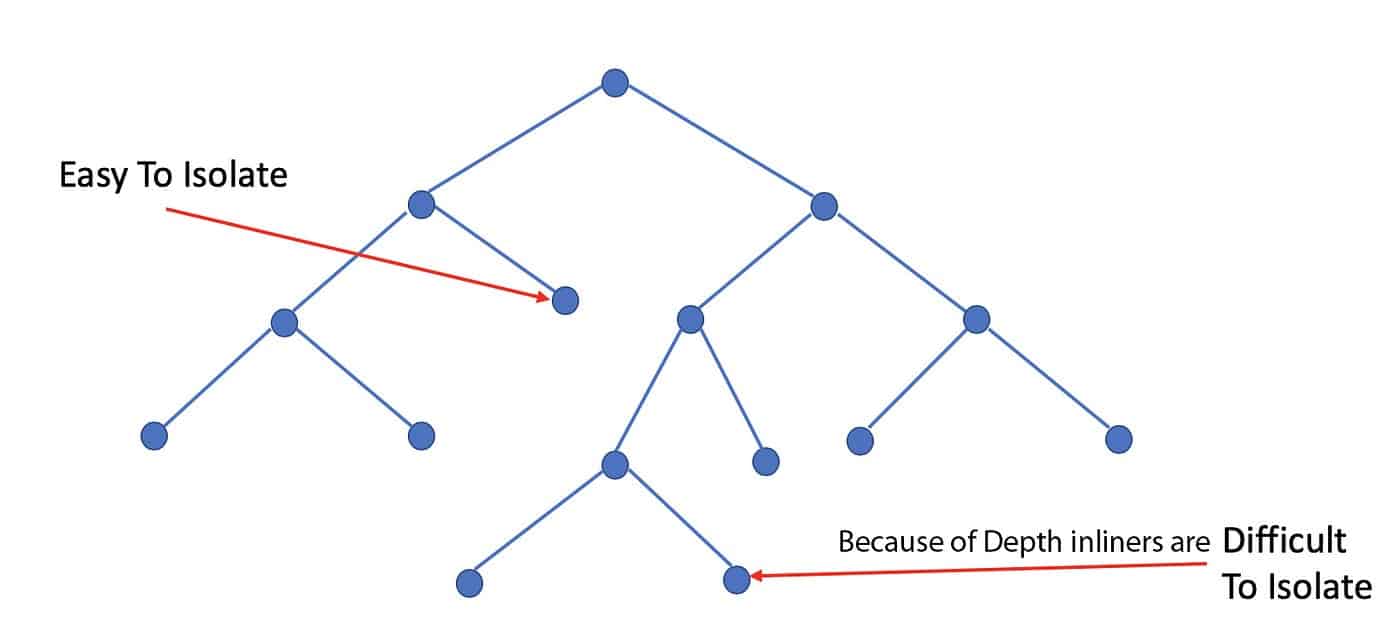
El algoritmo Isolation Forest funciona dividiendo y aislando aleatoriamente puntos de datos dentro de un conjunto de datos. Para ello, crea grupos de nodos y los aísla en función de sus atributos. Estos atributos pueden ser valores predictivos, valores categóricos, valores booleanos o cualquier otro tipo de datos. A continuación, el algoritmo asigna una puntuación a los puntos de datos aislados. Una puntuación más alta indica que el punto de datos es una anomalía.
Una vez identificadas las anomalías, es posible seguir investigando los puntos de datos en cuestión. Esto ayuda a los usuarios a comprender mejor qué características hacen que ese punto de datos en particular sea inusual. Además, puede ayudar a identificar la actividad del usuario que puede ser indicativa de ataque o intención maliciosa.
A diferencia de muchos otros métodos de aprendizaje automático, el bosque de aislamiento no requiere limpiar ni preprocesar un conjunto de datos. Esto lo convierte en una herramienta útil para detectar de forma rápida y fiable anomalías en grandes conjuntos de datos que pueden no haber sido limpiados a fondo. Además, no requiere un conocimiento profundo de la estructura de los datos, sino que utiliza un algoritmo sencillo que puede aplicarse directamente a un conjunto de datos.
Isolation Forest puede aplicarse a una amplia gama de conjuntos de datos, como registros financieros, historiales médicos, registros de actividad de usuarios y tráfico de red. Es una herramienta valiosa para la minería de datos y la detección de anomalías, ya que puede identificar patrones y comportamientos que podrían no ser evidentes al observar los datos de forma aislada. Además, este algoritmo ayuda a reducir la cantidad de falsos positivos al detectar anomalías.